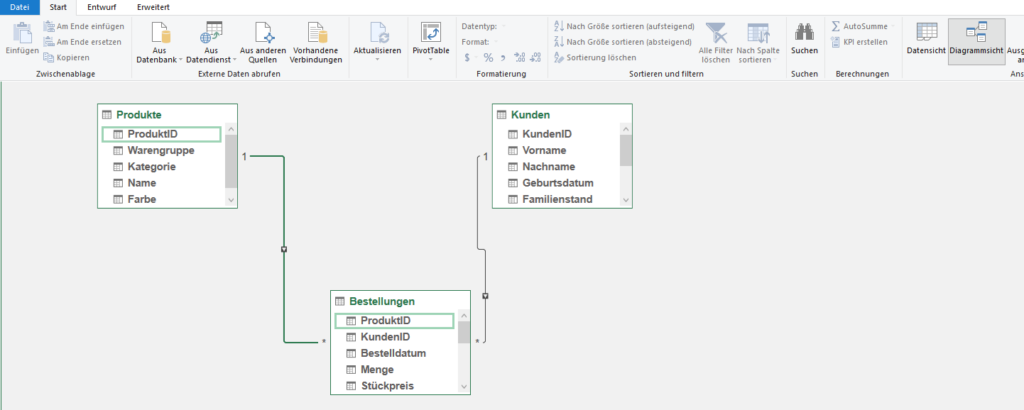
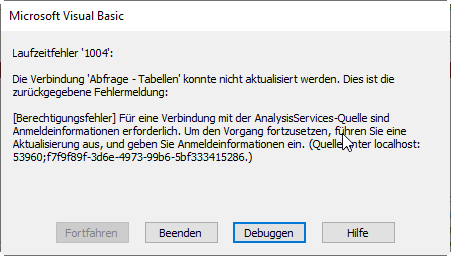
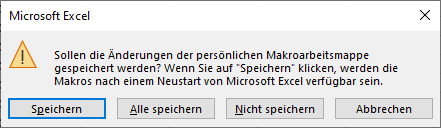
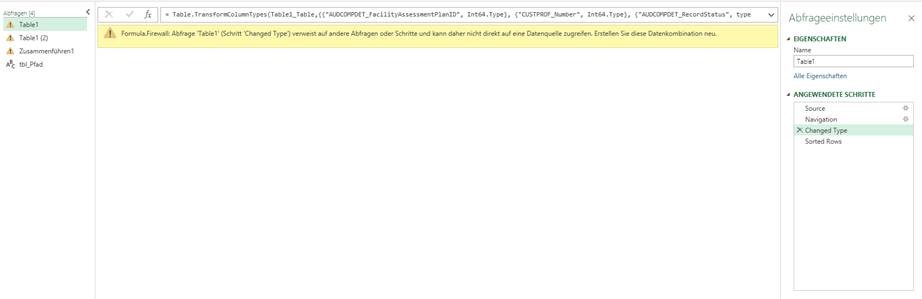
entschuldigen Sie bitte wenn ich Sie direkt ansprechen, allerdings habe ich mit PowerQuery als Anfänger ein Problem, das ich dringen lösen muss und für unser Haus von Wichtigkeit ist.
Ich hoffe daher auf Ihre kurze Unterstützung.
Folgendes Problem:
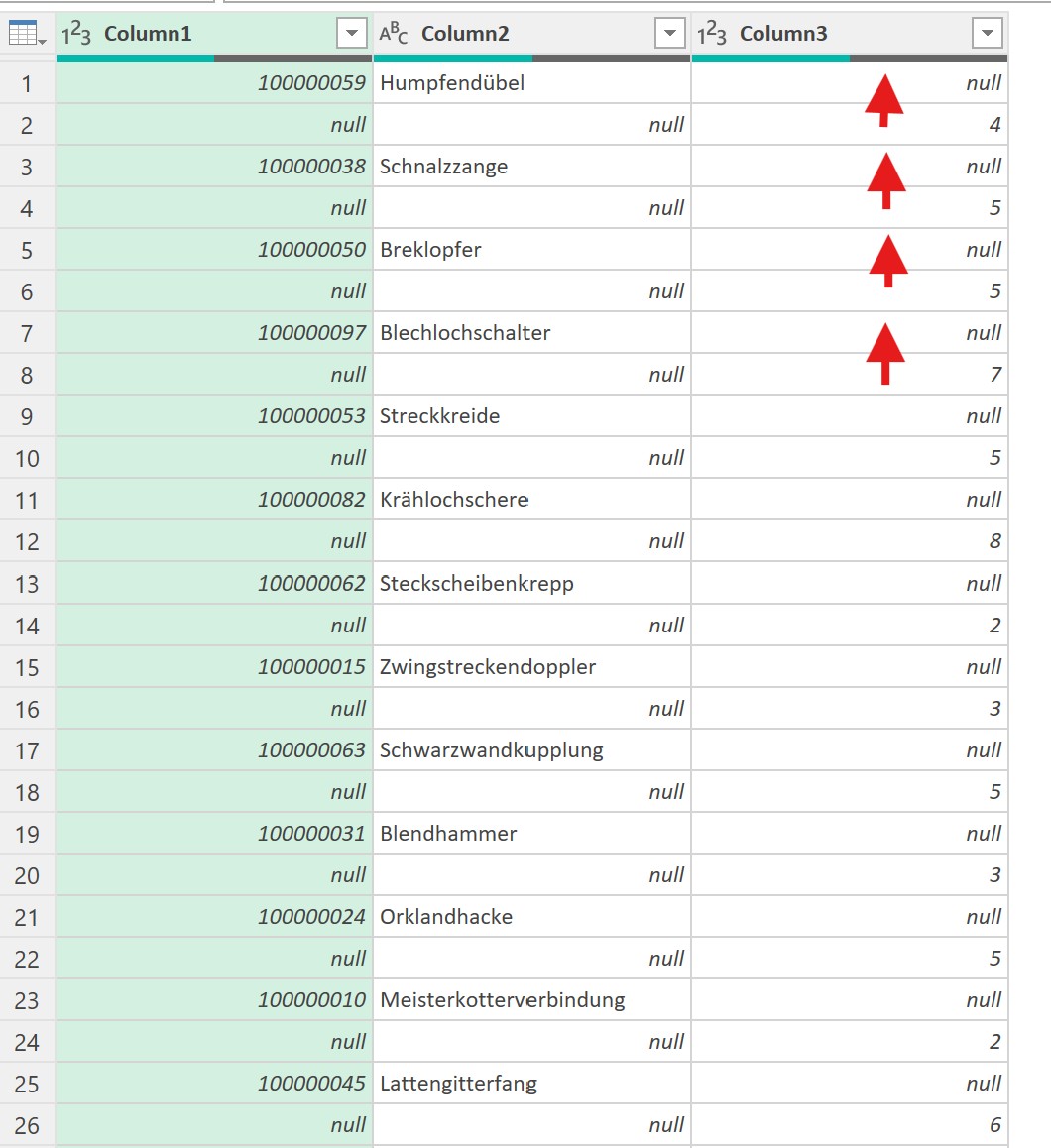
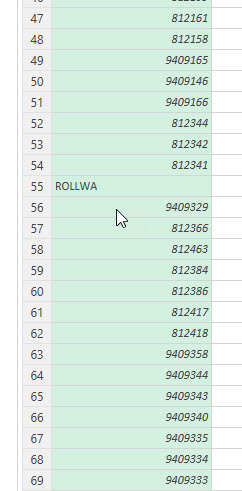
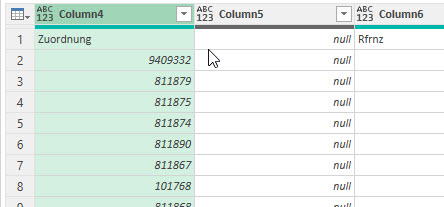
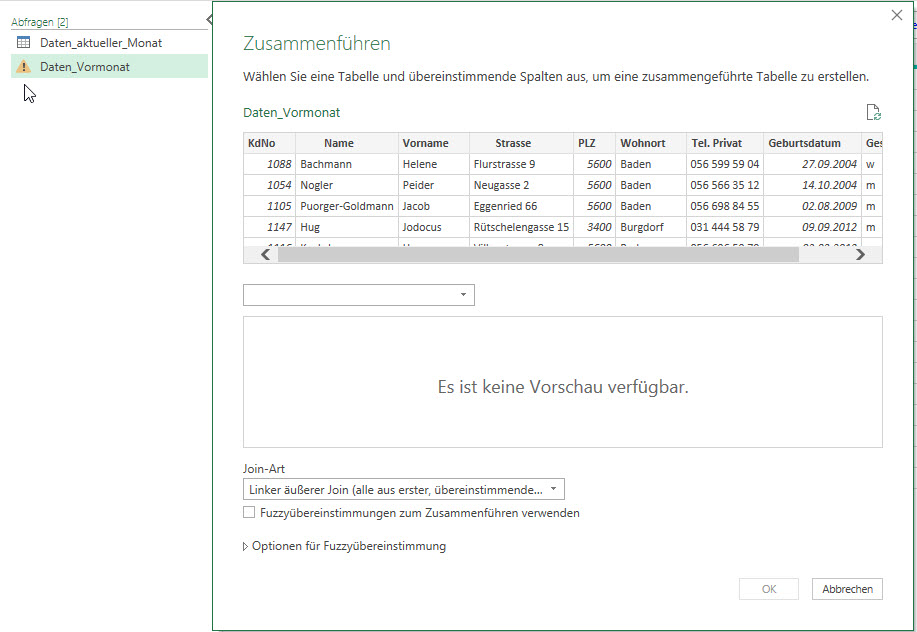
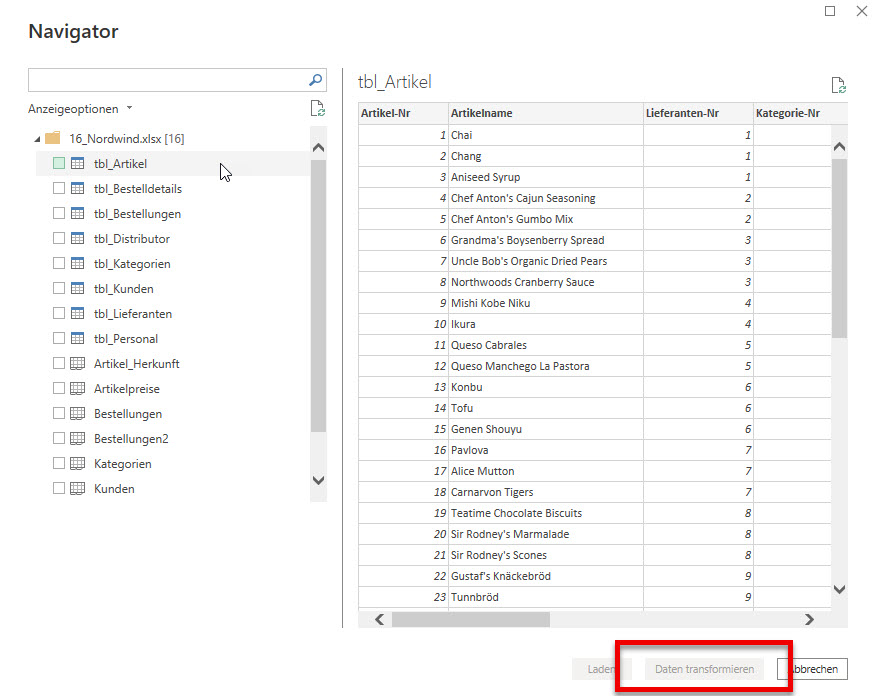
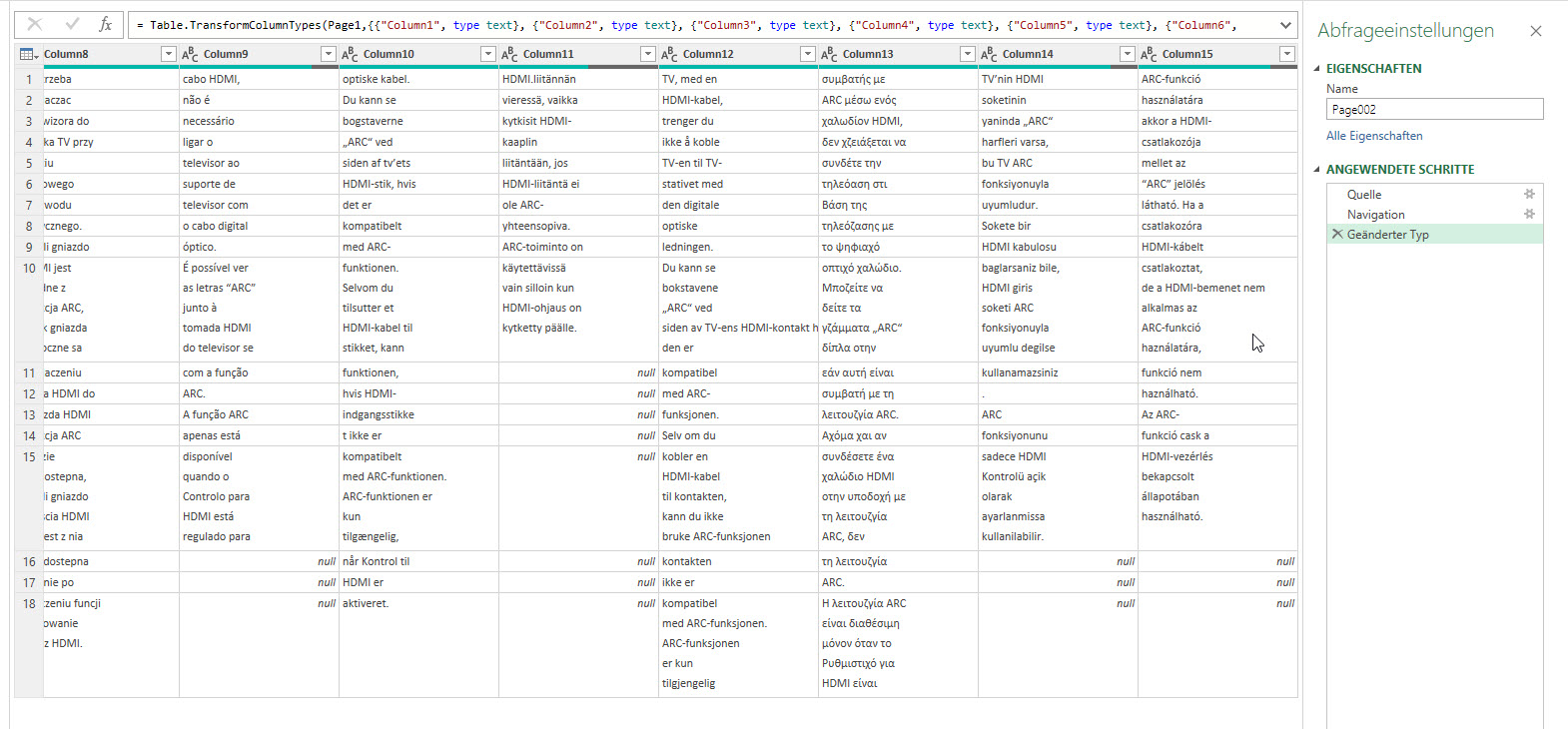
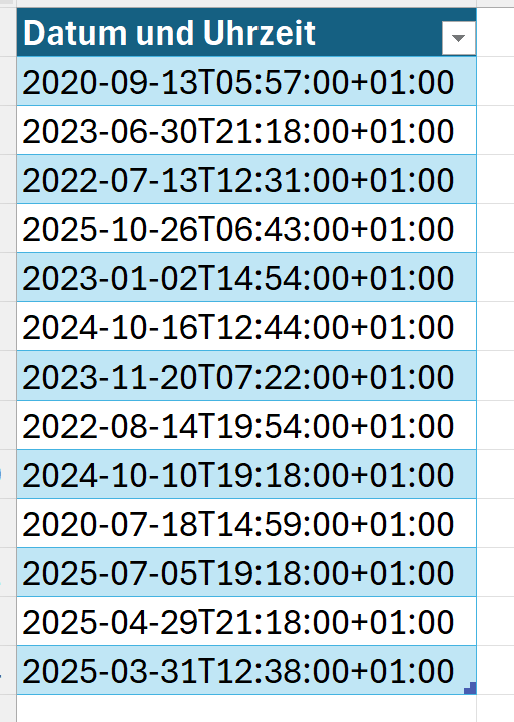
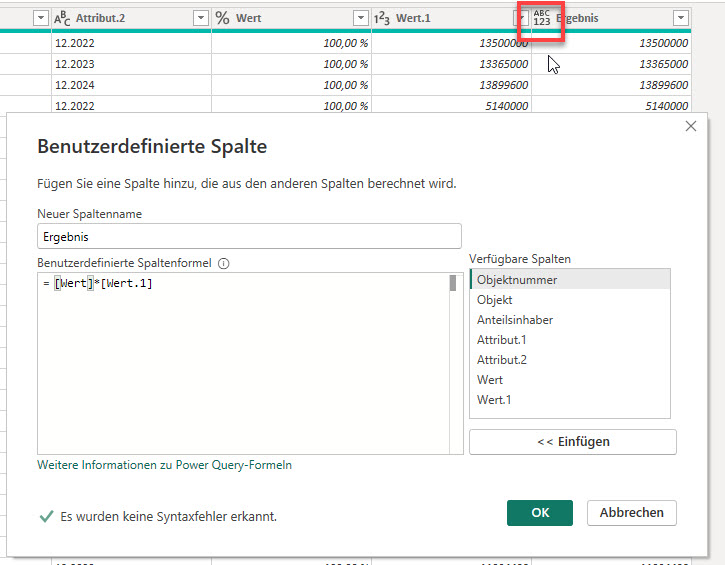
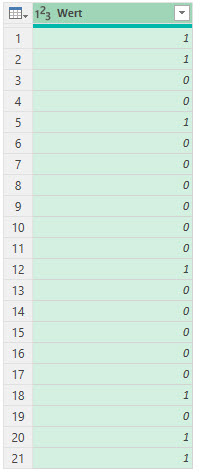
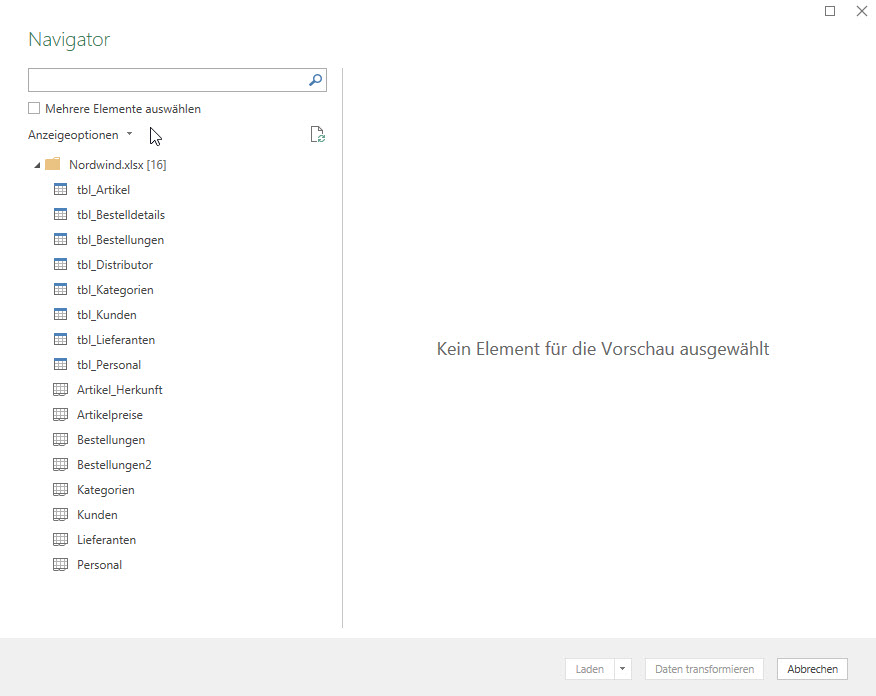
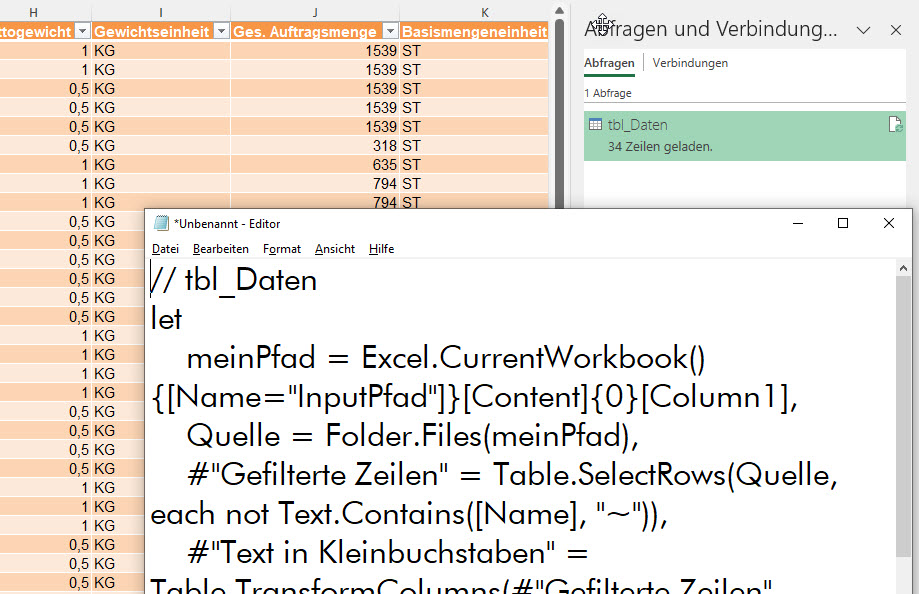
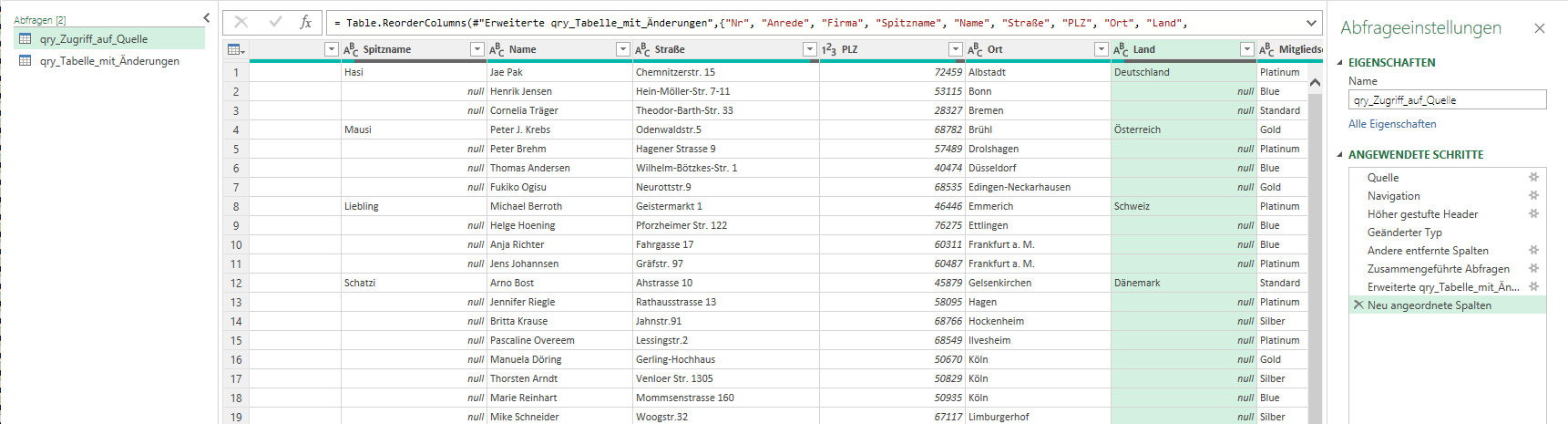
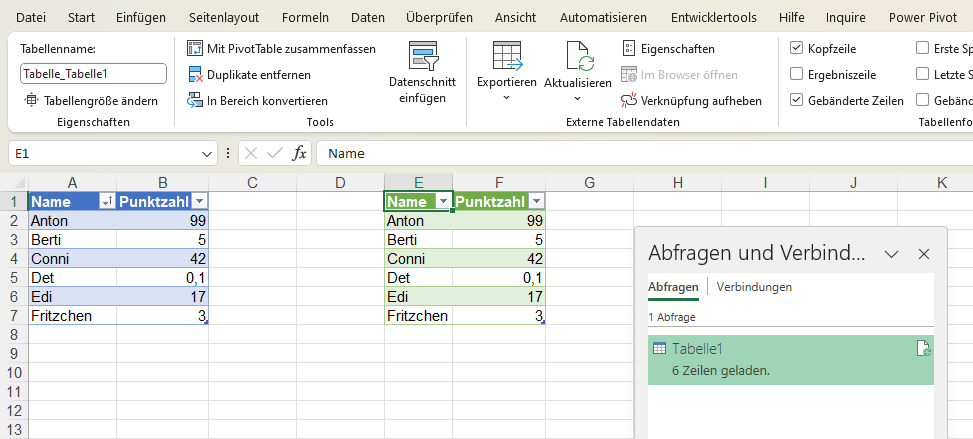
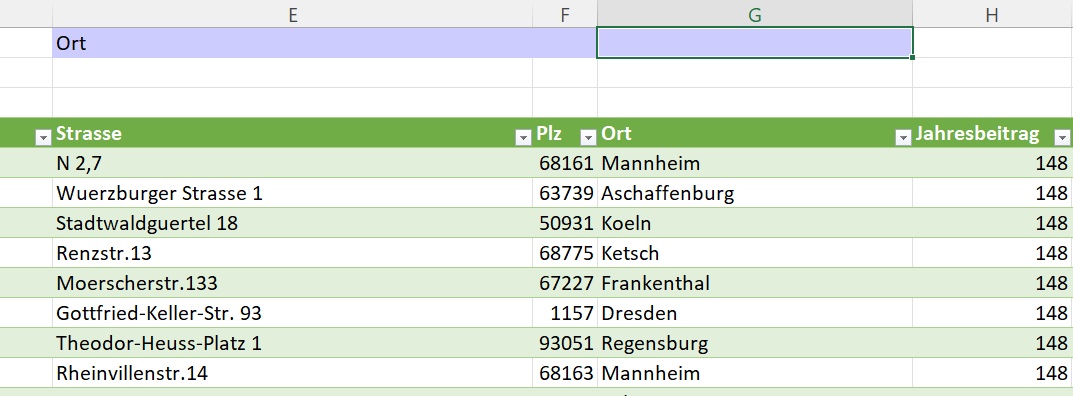
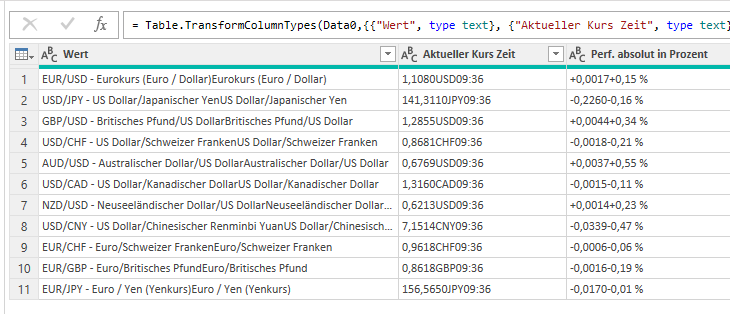
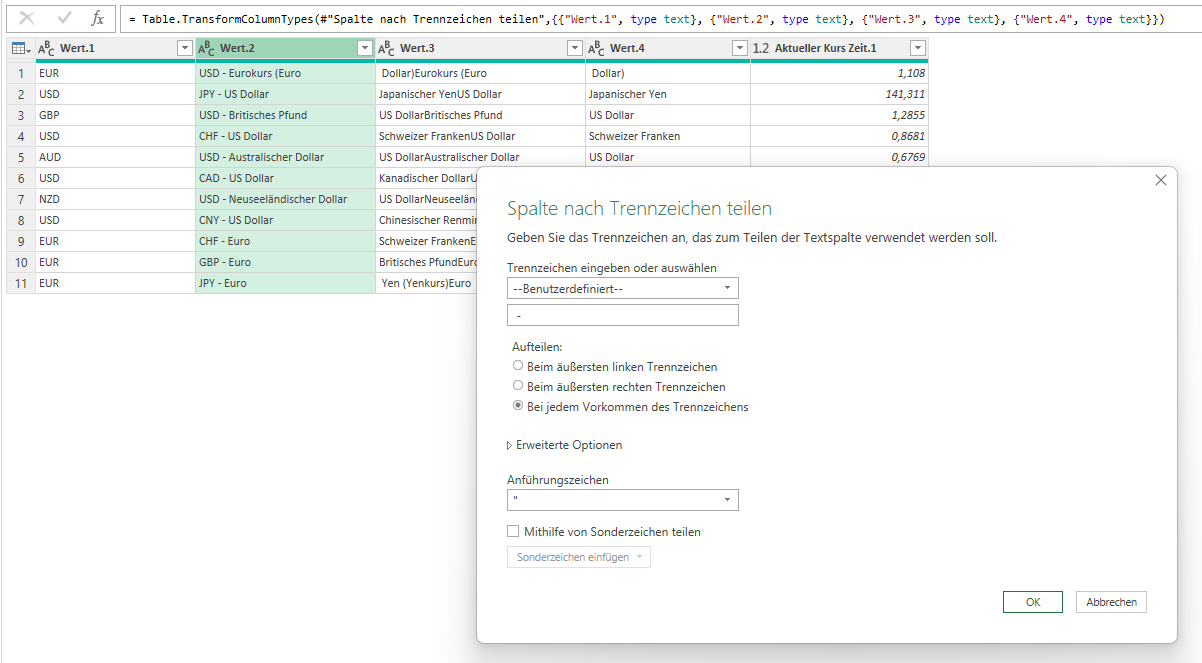
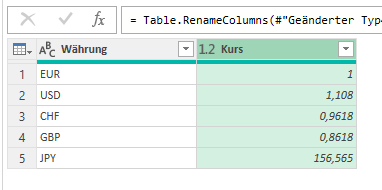
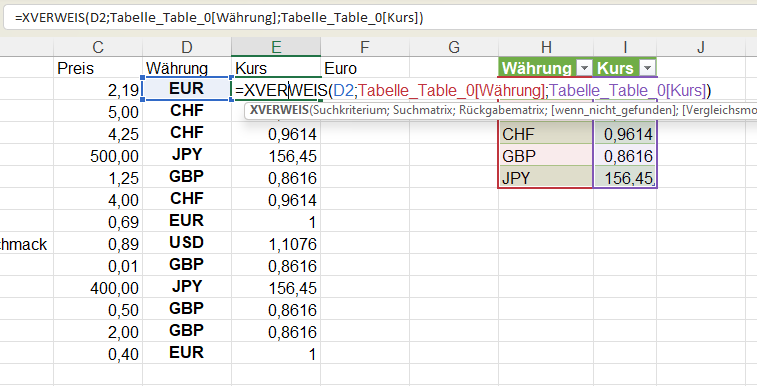
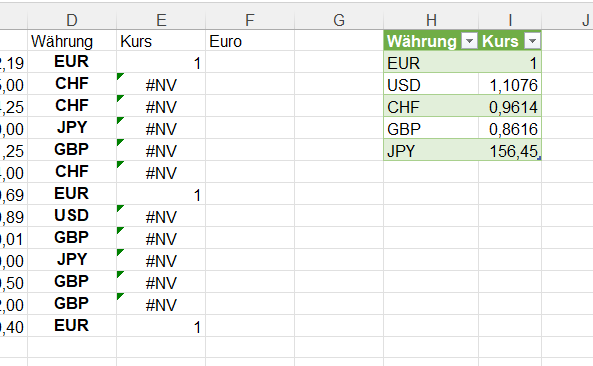
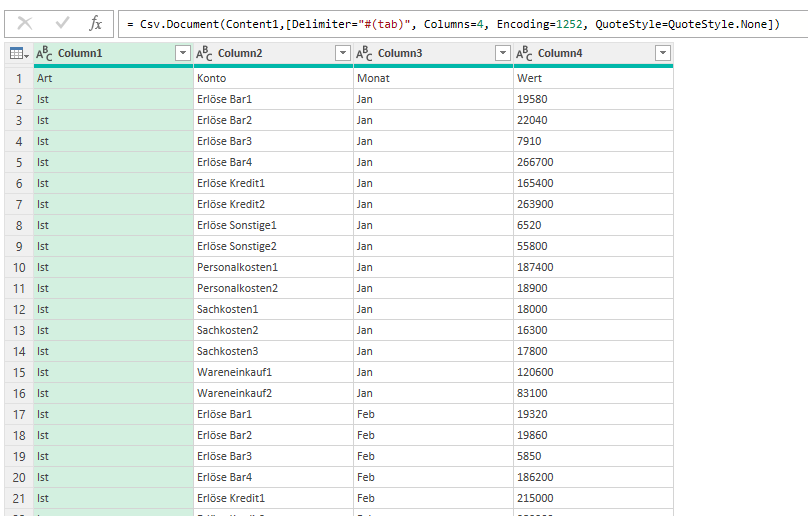
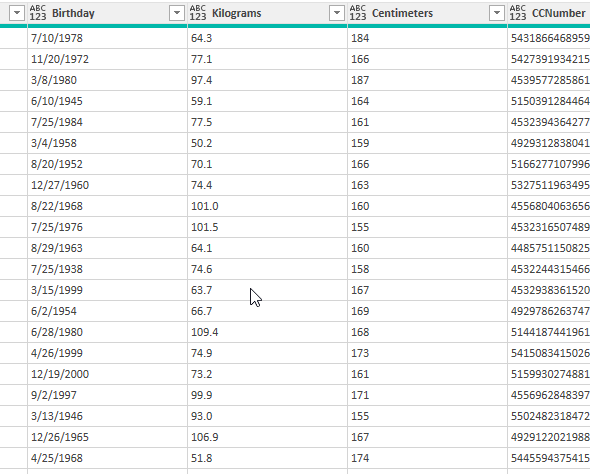
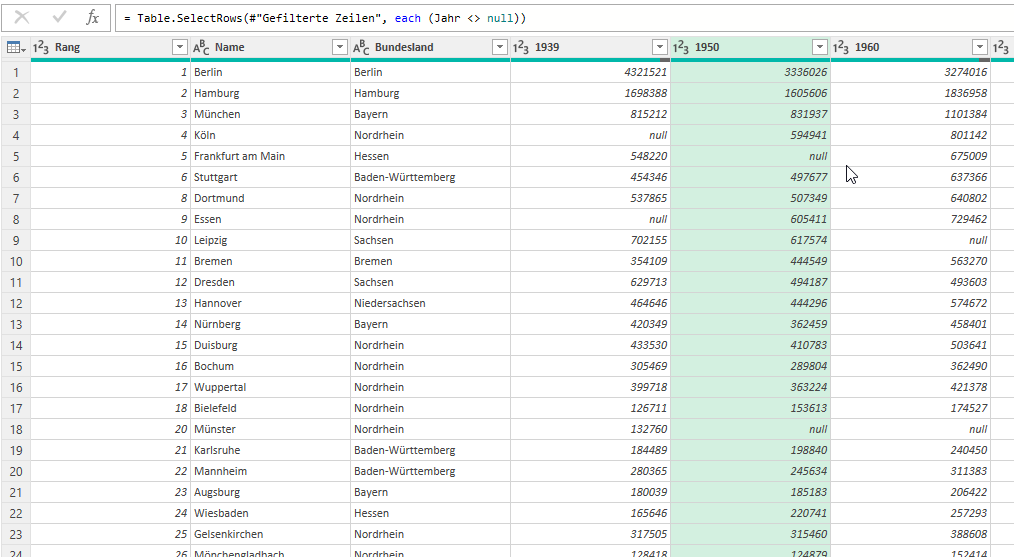
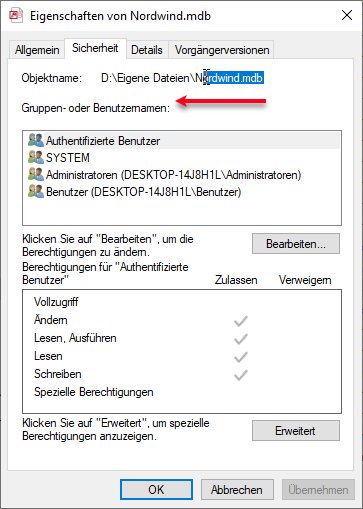
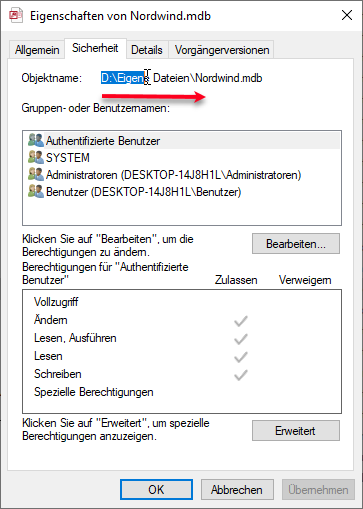
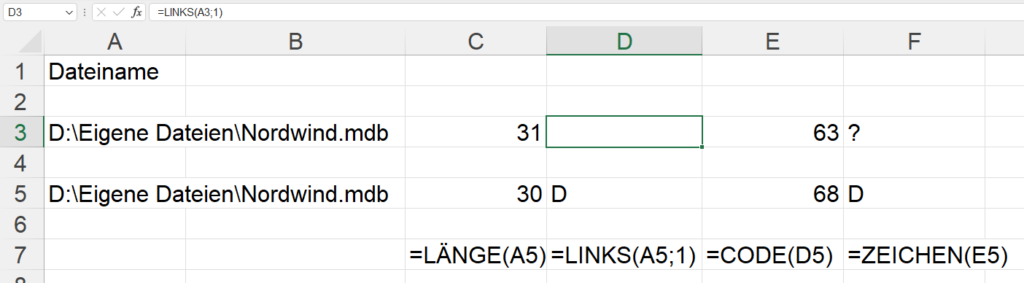
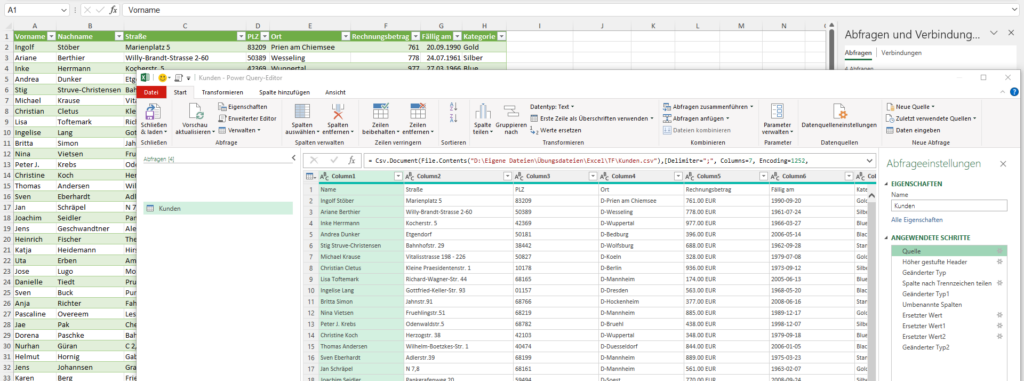
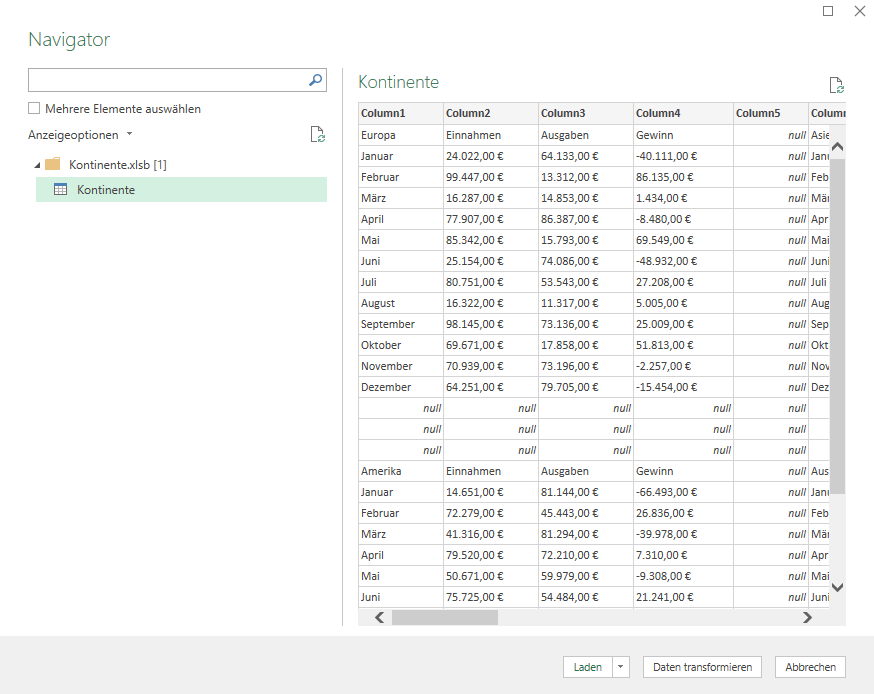
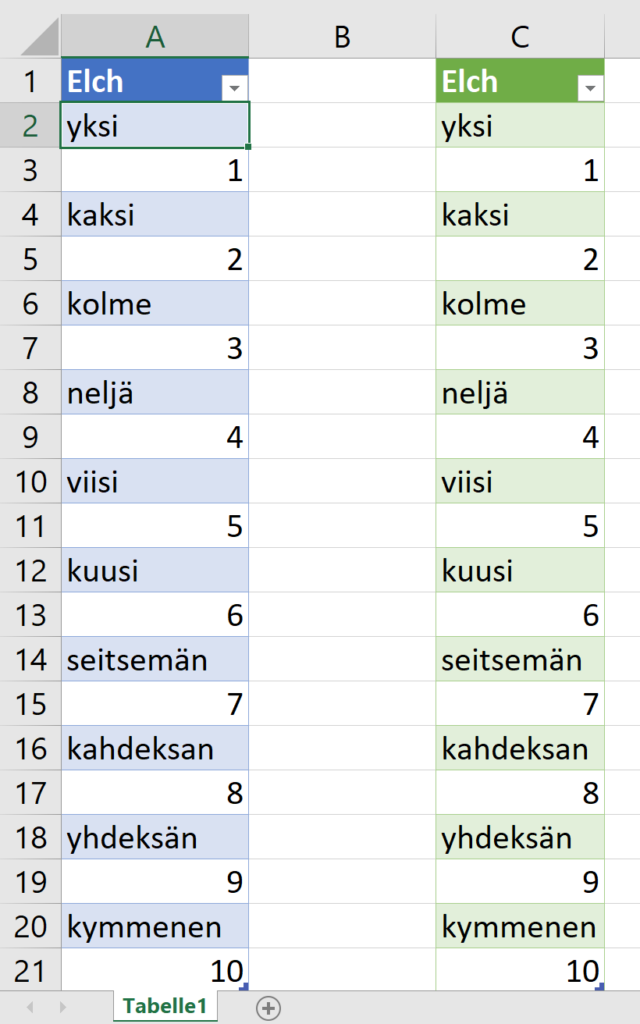
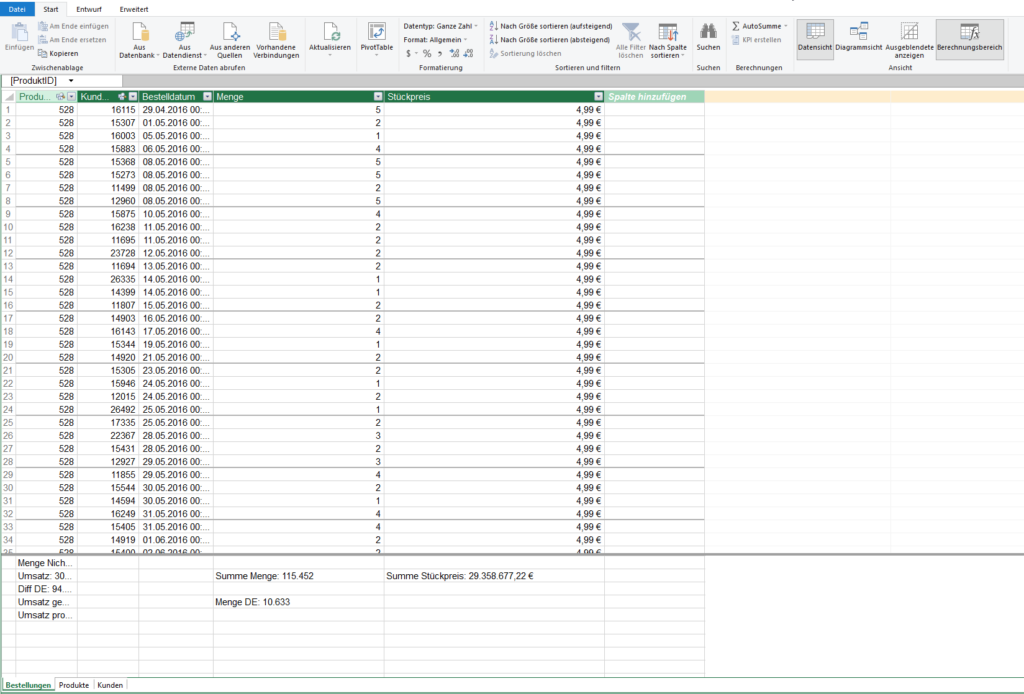
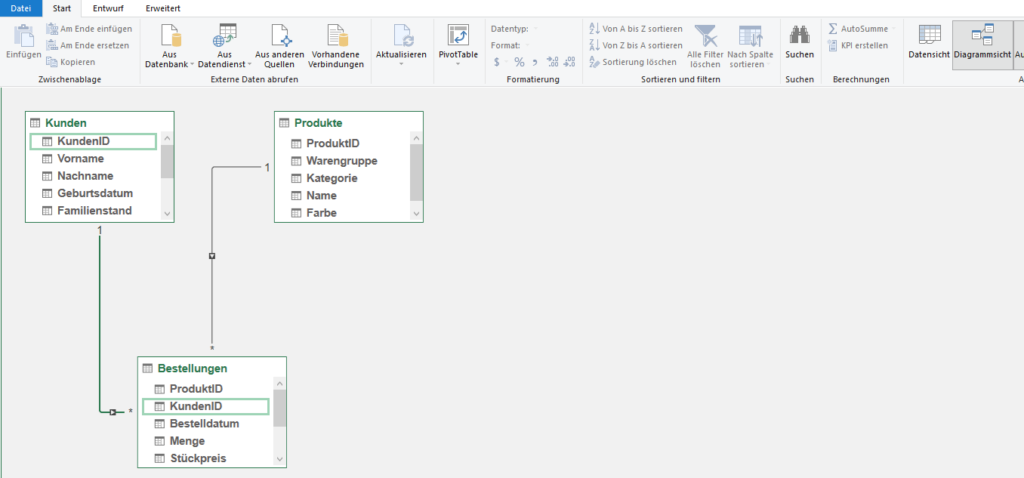
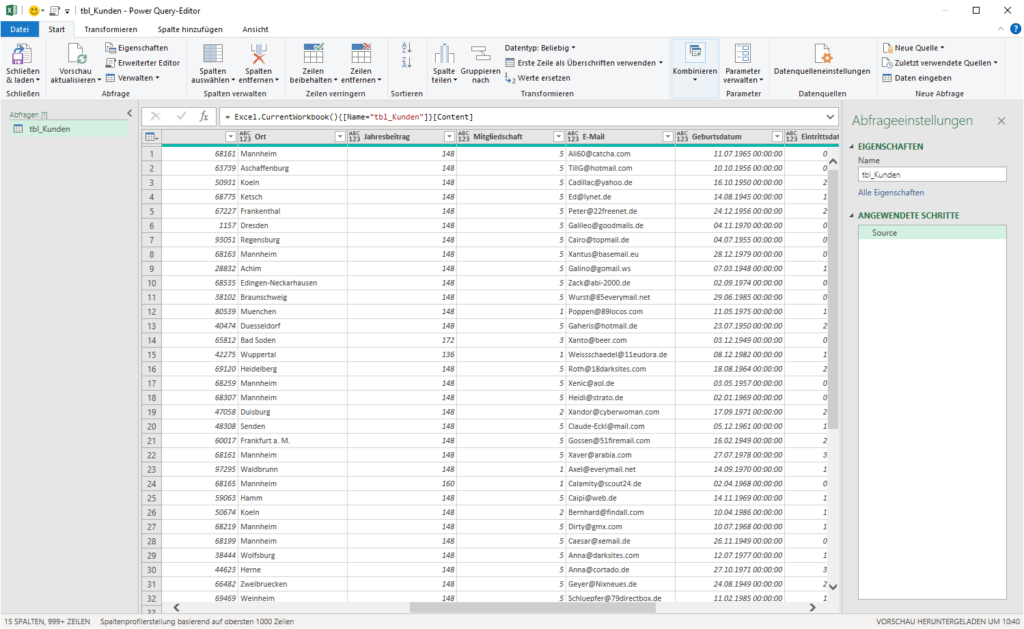
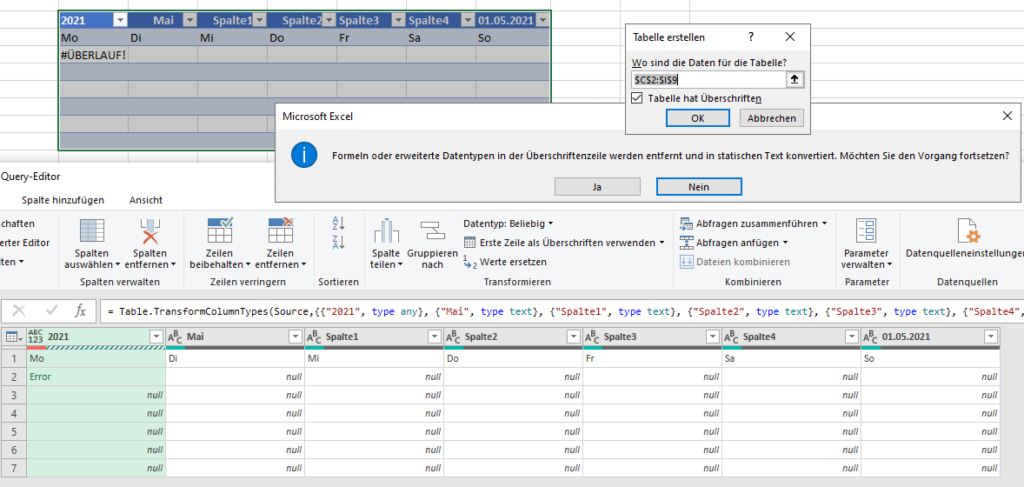
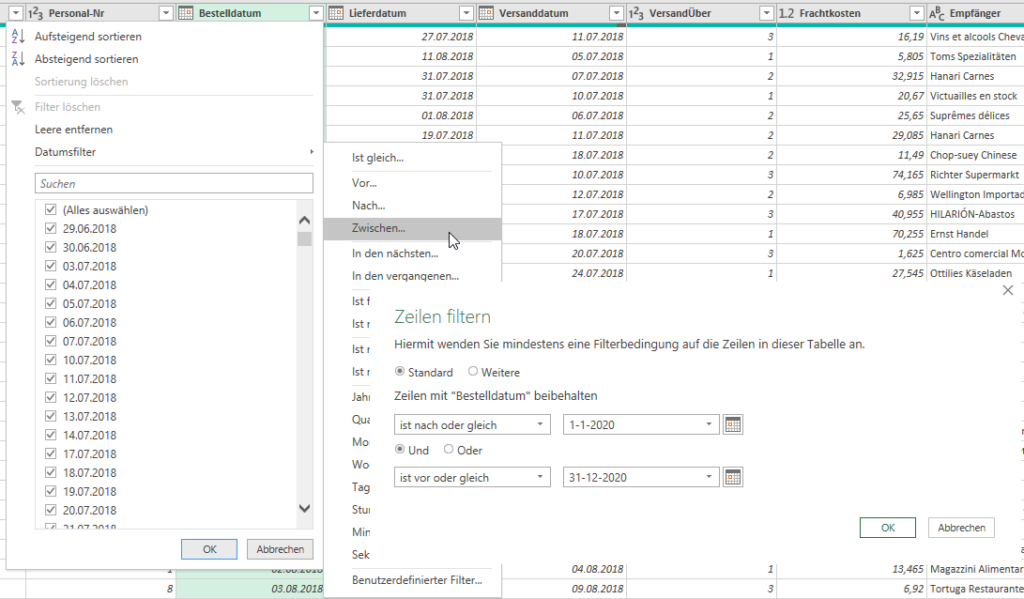
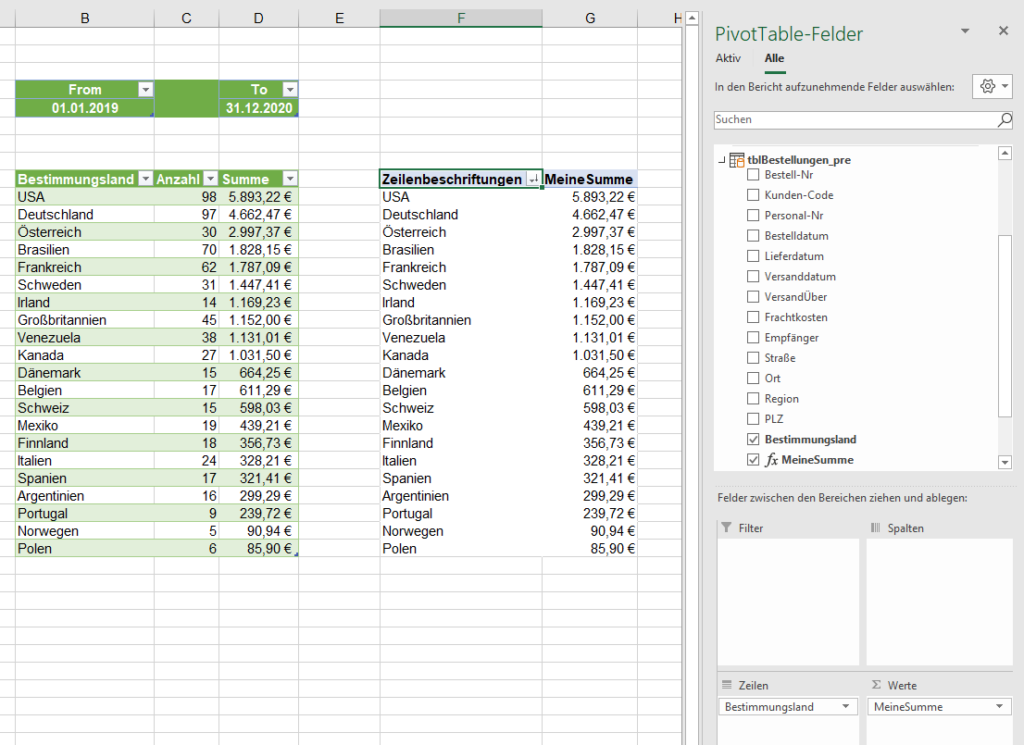
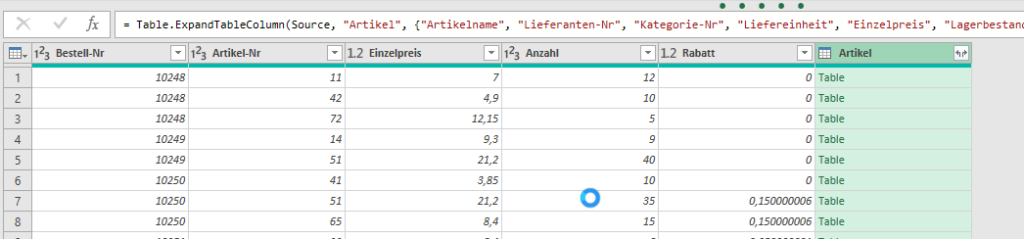
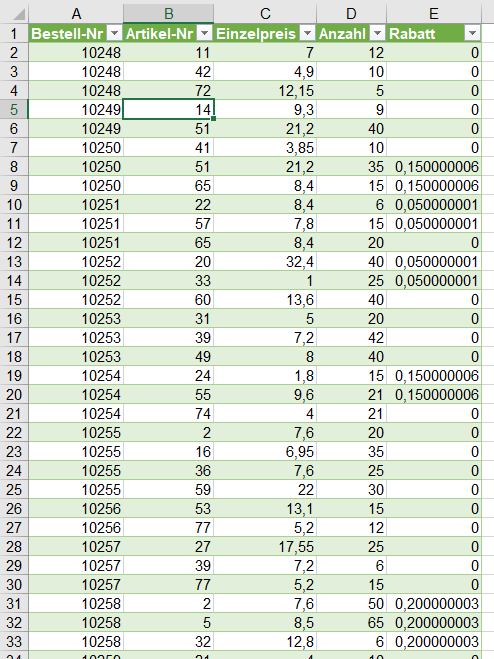
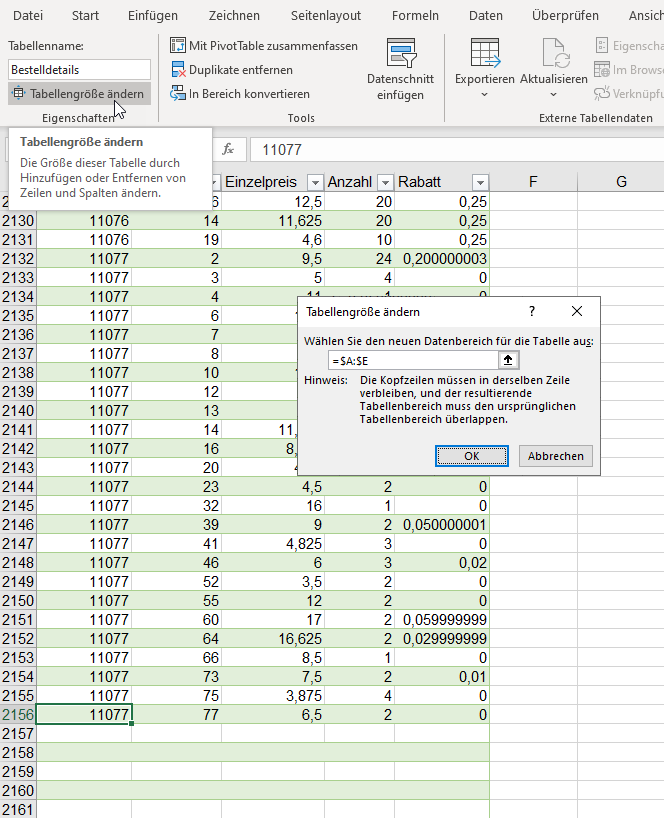
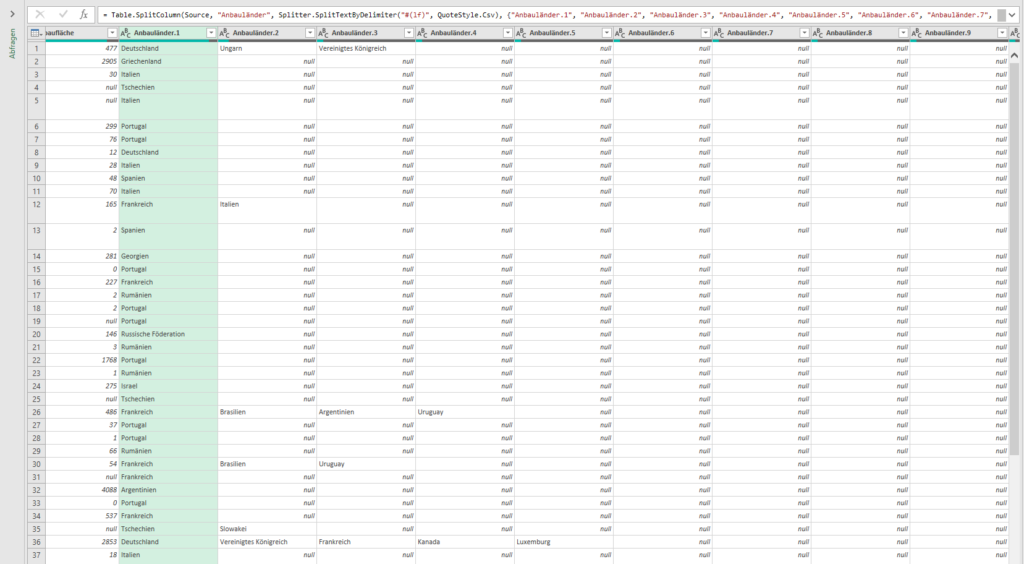
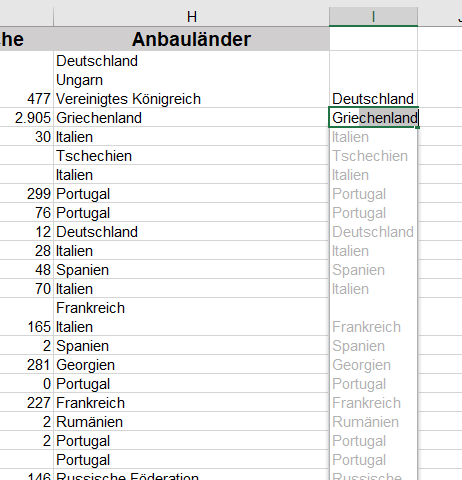
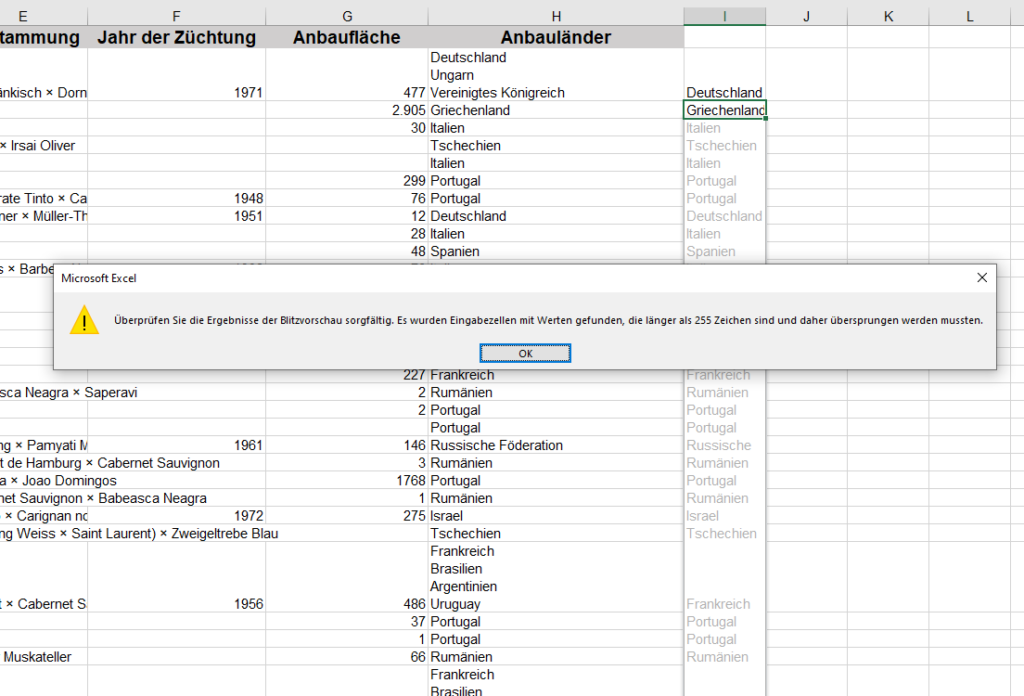
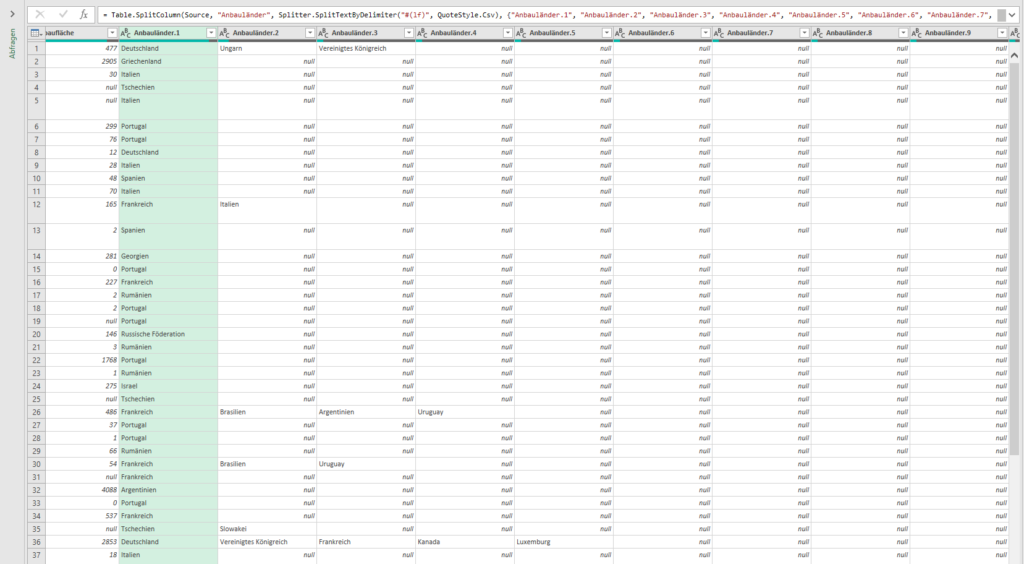
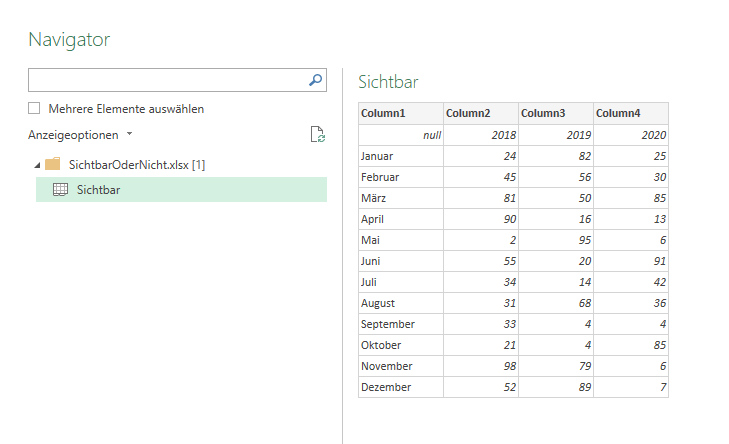
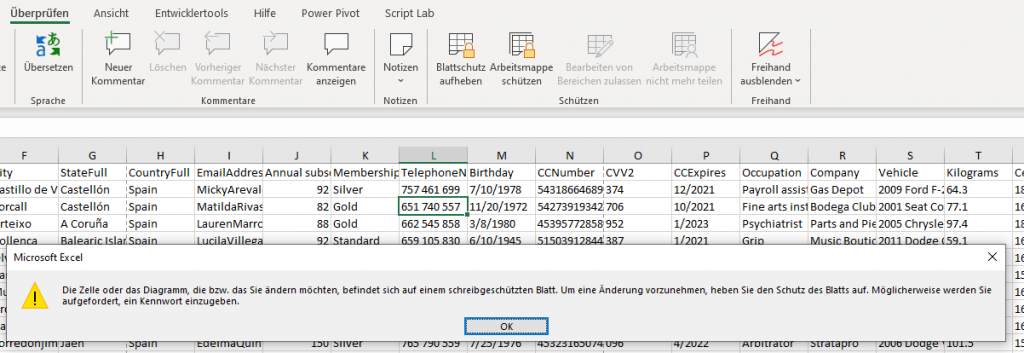
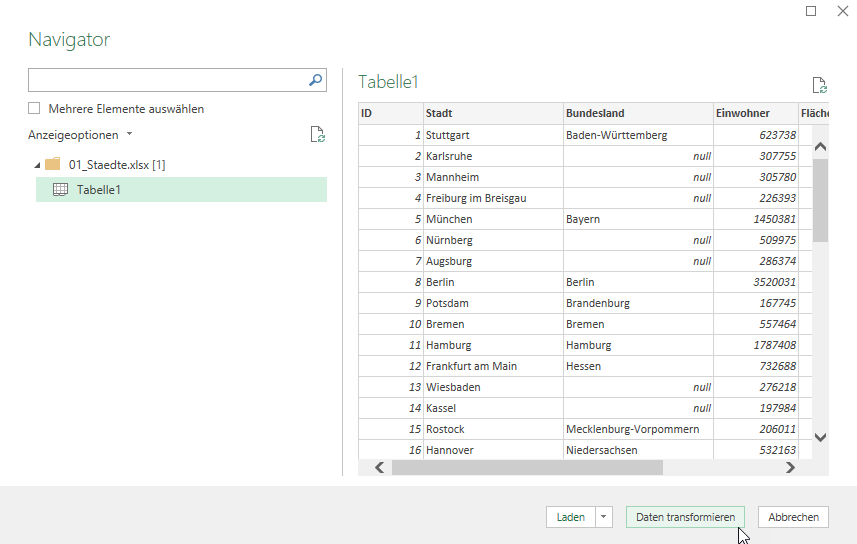
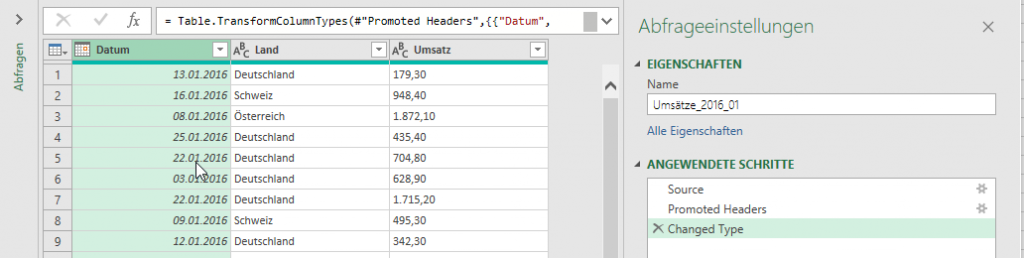
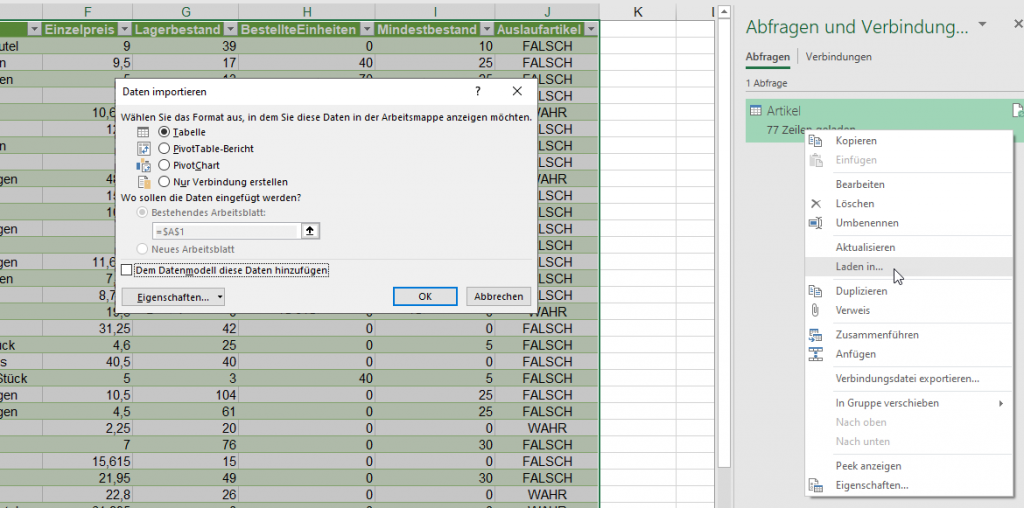
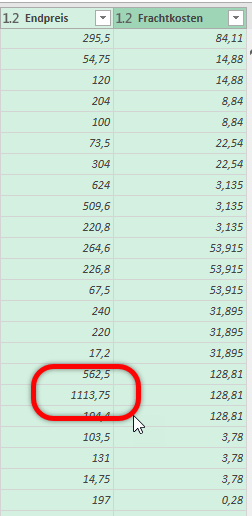
In der nachstehenden Tabelle sind Art.-Nr. (Columm1), Bezeichnung(Column2) und Werte unter Column3.
Die Werte stehen jeweils eine Zeile Tiefer wie die Bezeichnung und die Art.-Nr. (Wundern Sie sich bitte nicht, die Werte kommen aus einem alten System deren Programmierung leider nicht nachvollziehbar ist)
Ich finde im Internet leider keine Lösung um die Werte in Spalte Column3 in die jeweilig passende Zeile zu bekommen.
Gibt es hierzu eine Möglichkeit? Ich würde mich freuen, wenn Sie mir hierzu eine Rückmeldung geben könnten, vielen Dank!
####
Hallo Herr K.,
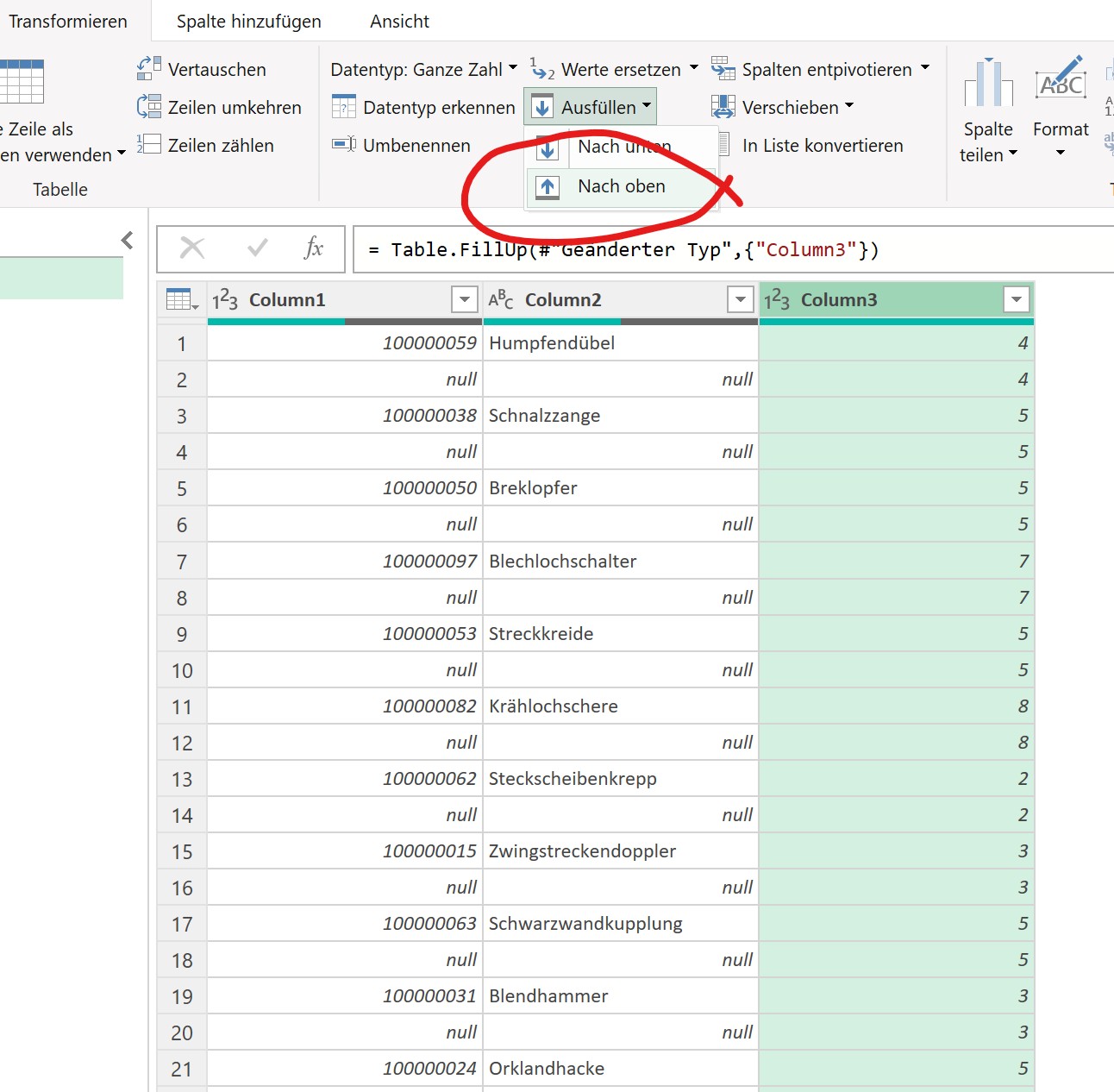
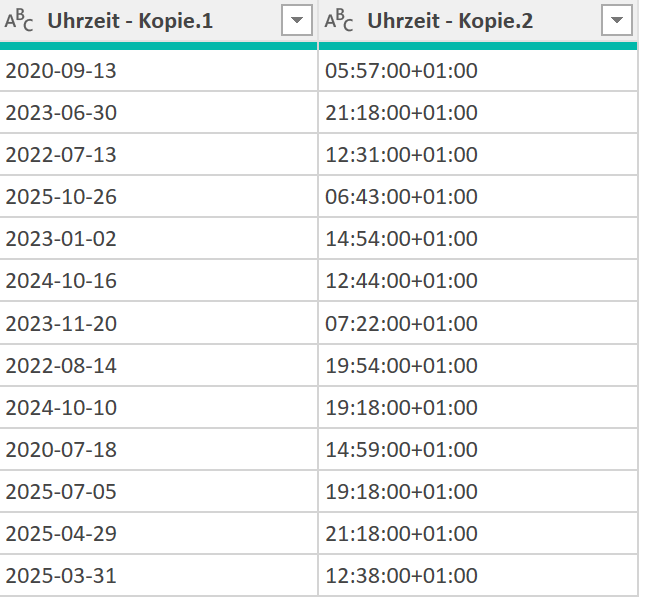
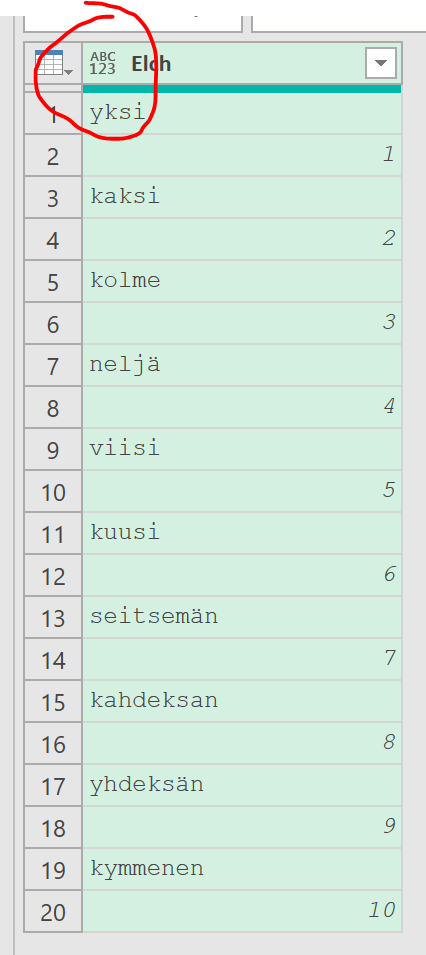
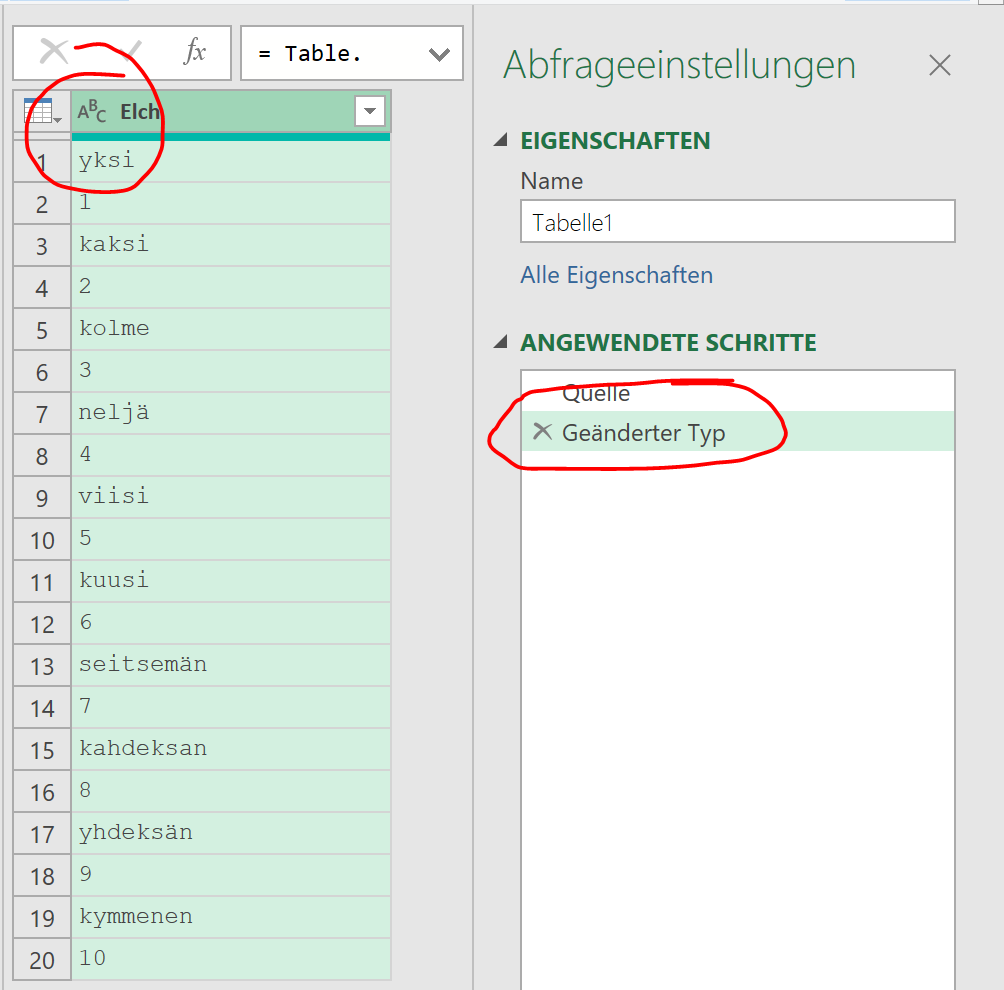
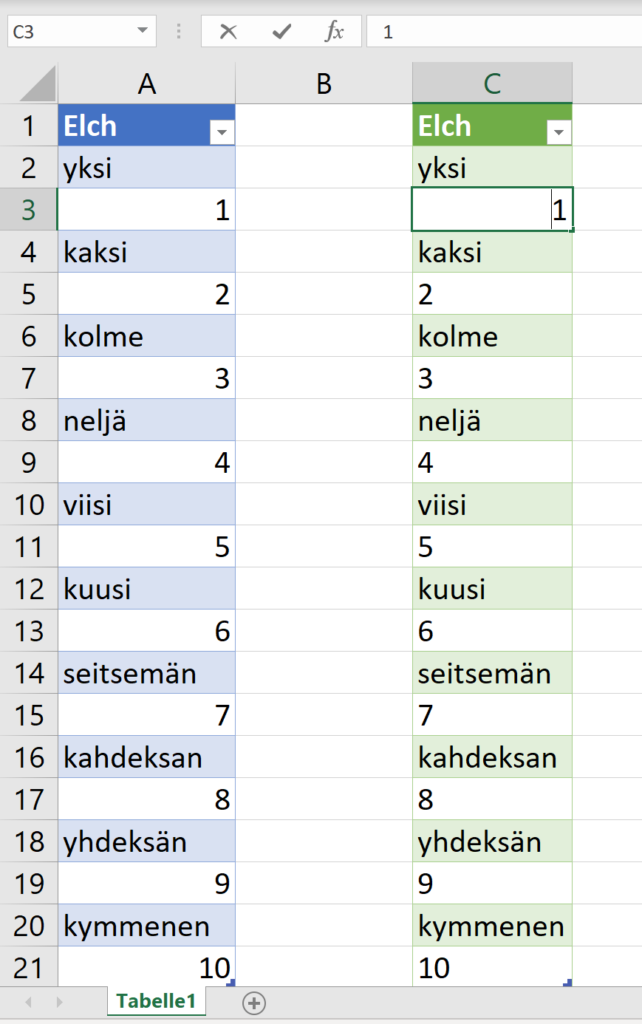
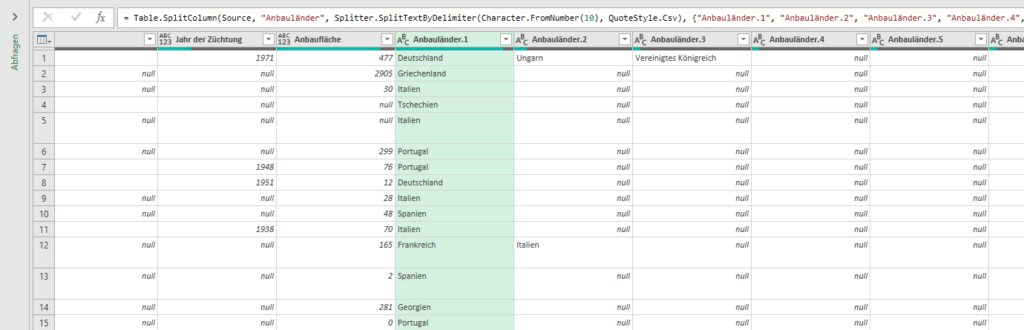
ich würde den Befehl Transformieren / Ausfüllen / Nach oben verwenden.
Und anschließend die überflüssigen Zeilen (weg-)filtern.
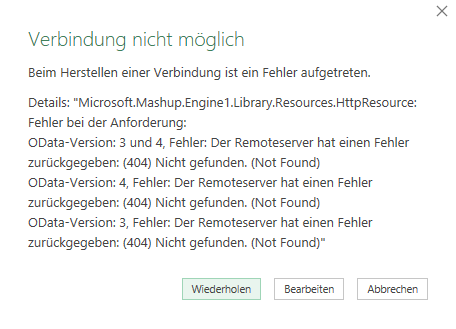
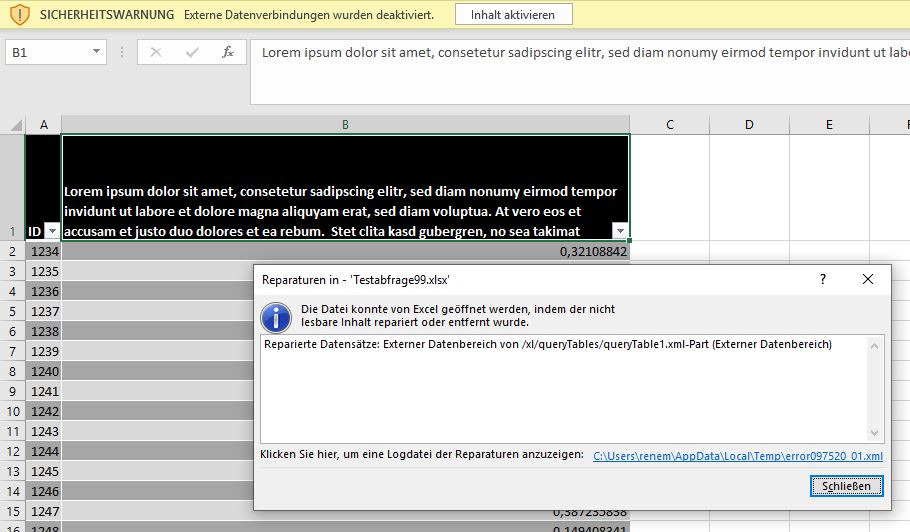
leider habe ich heute beim Einspielen der aktuellen Preise in unsere Excel Datei Datenaustausch einen Fehler erhalten.
Die Daten wurden mehrmals eingespielt, obwohl der Eintrag nur einmal vorhanden ist. Ich kann leider keinen Fehler erkennen.
Ich habe Ihnen die entsprechenden Dateien angehängt.
Könnte Sie mich bitte unterstützen.
Vielen Dank und viele Grüße AR
####
Hallo Frau Rumpel,
ich habe den Fehler gefunden: in den neuen SAP-Dateien war ein Druckbereich festgelegt – unser Programm hat nun die alten Daten plus die Daten aus dem Druckbereich (also zwei Mal) eingelesen.
Das habe ich korrigiert.
###
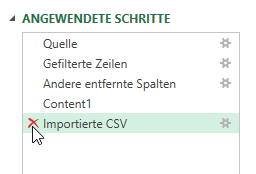
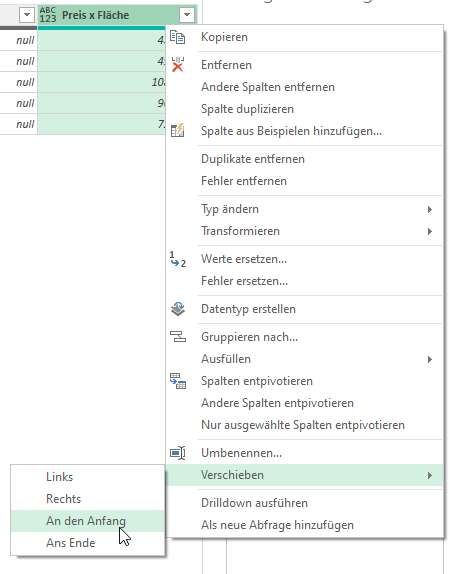
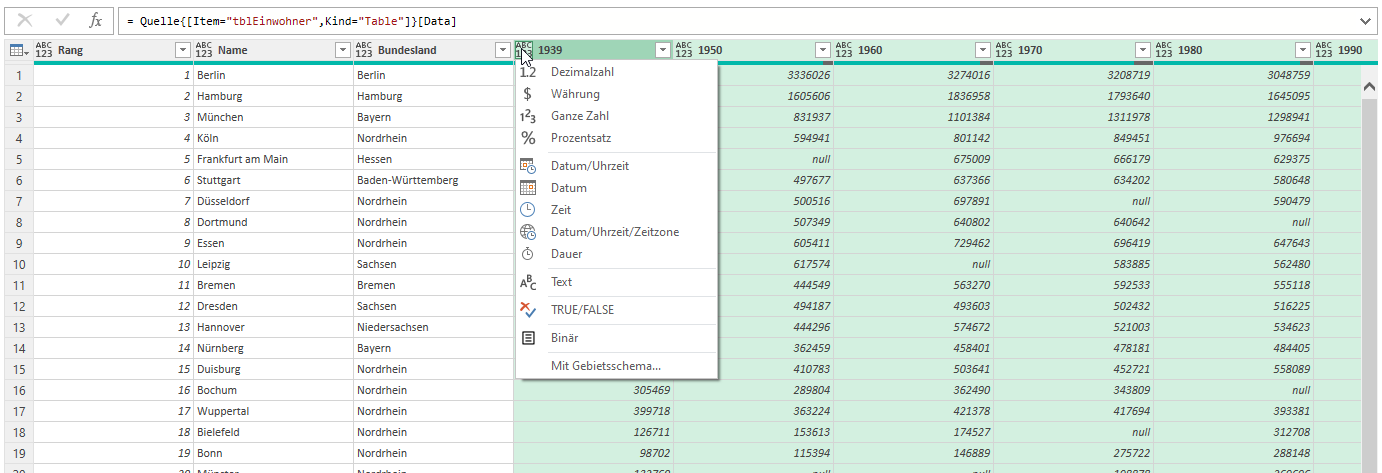
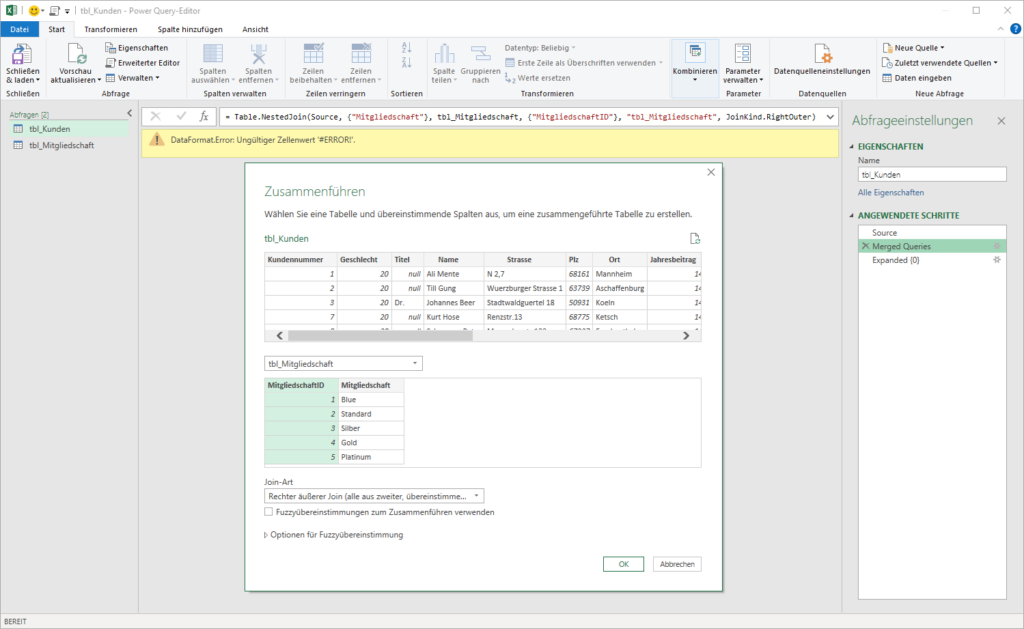
Was habe ich gemacht?
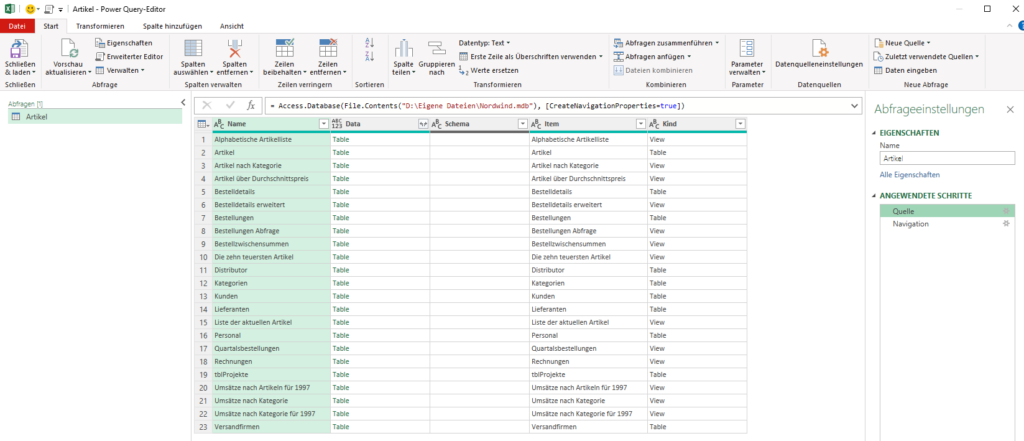
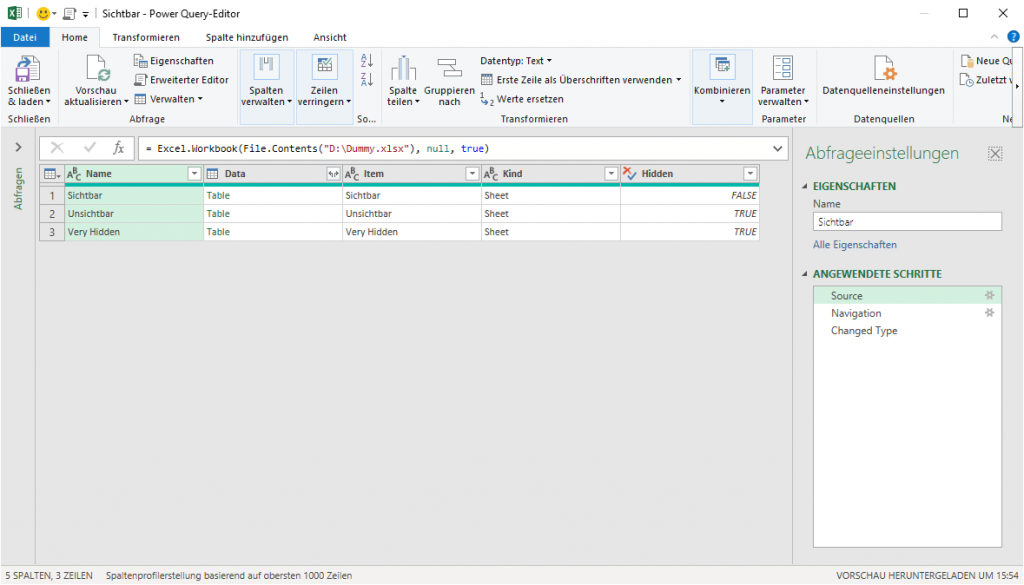
Ich habe nicht nur „Data“ anzeigen lassen, sondern auch „Kind“:
Dort sieht man den Fehler. Nun kann man „Sheet“ filtern und die Spalte „Kind“ wieder löschen. Und so werden die Daten nur ein Mal eingefügt.
Power Query stürzt ab. Und wieder. Und erneut ein Absturz:
Woran liegt es? Windows 11? Teams und Internet und ClickView? Keine Ahnung. Nervig. Und vor allem: SO heftig hatte ich das noch nie. Bislang war Power Query sehr stabil!
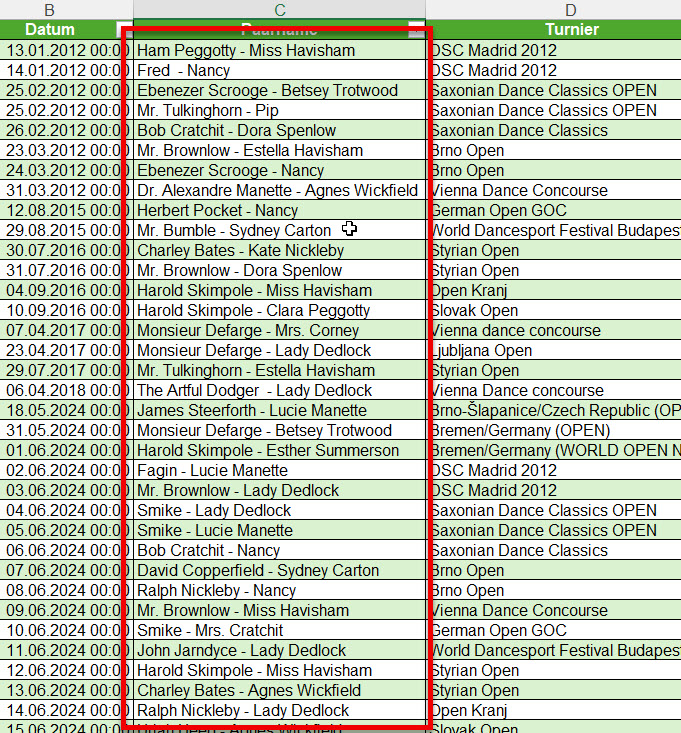
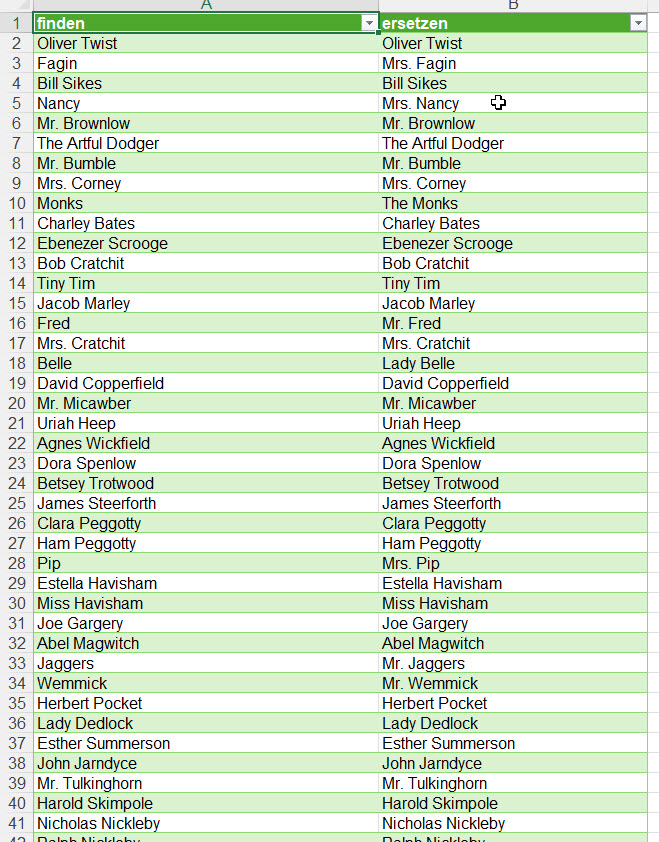
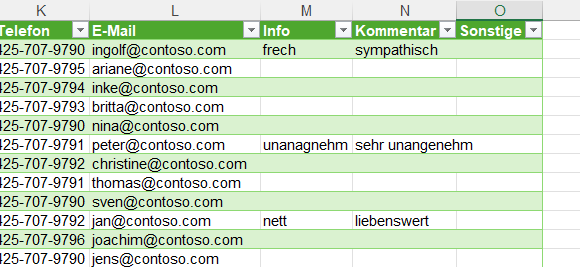
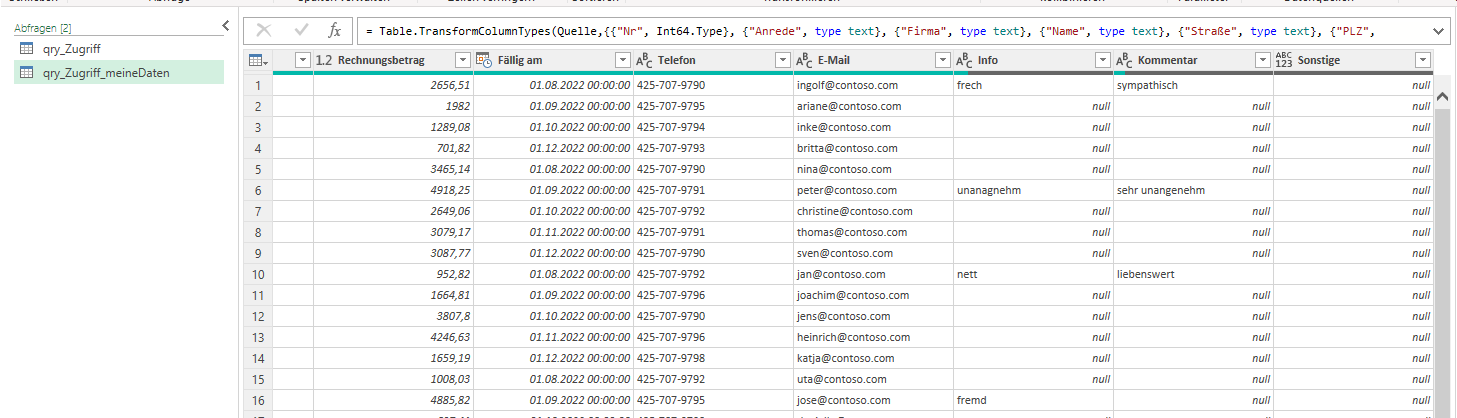
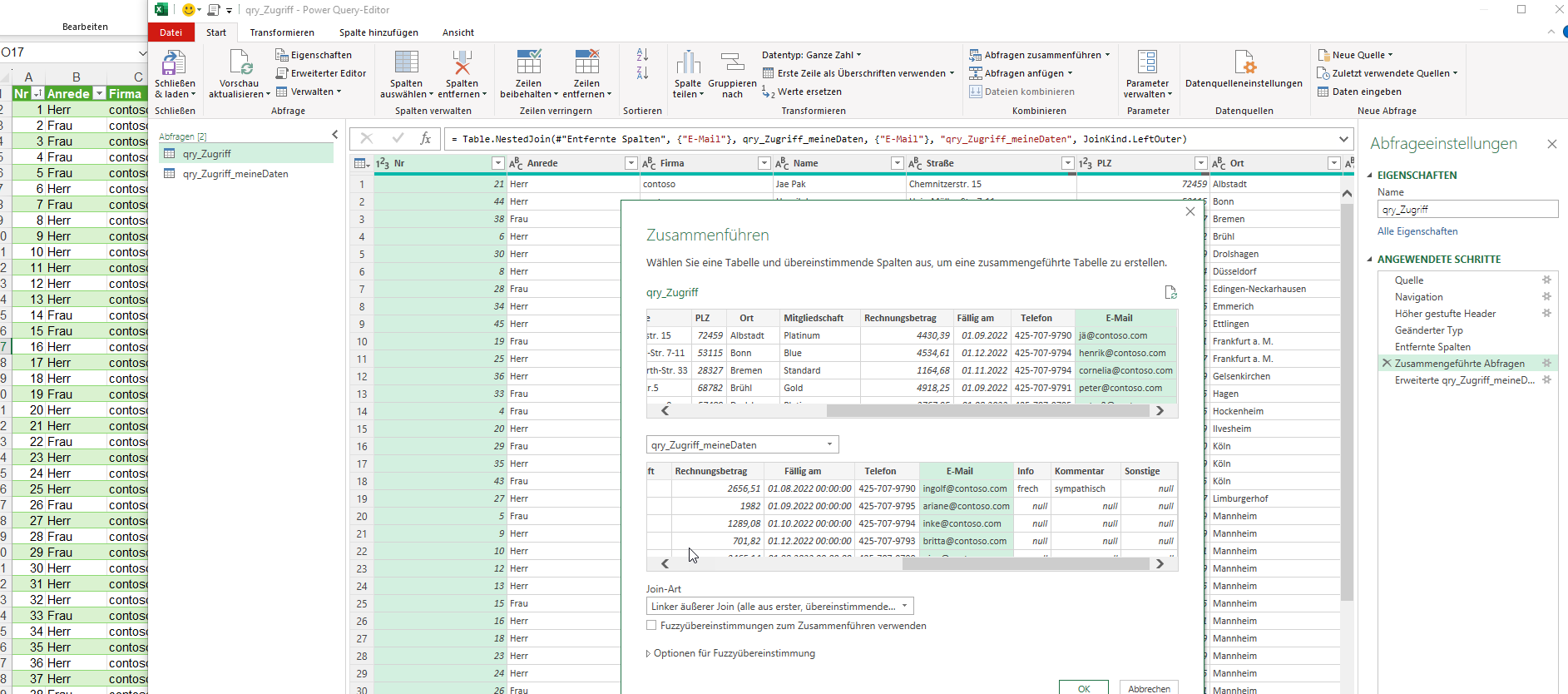
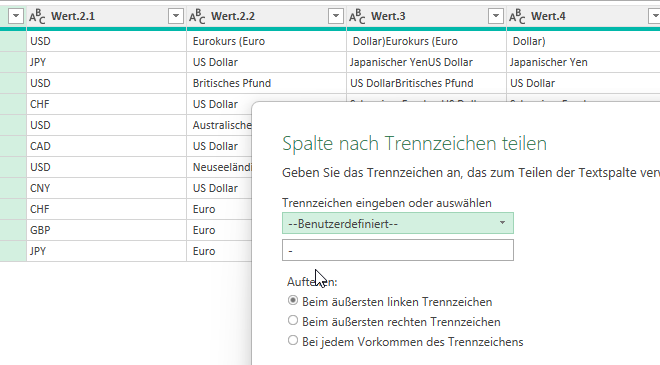
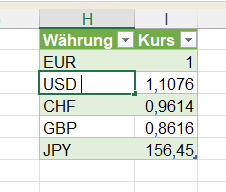
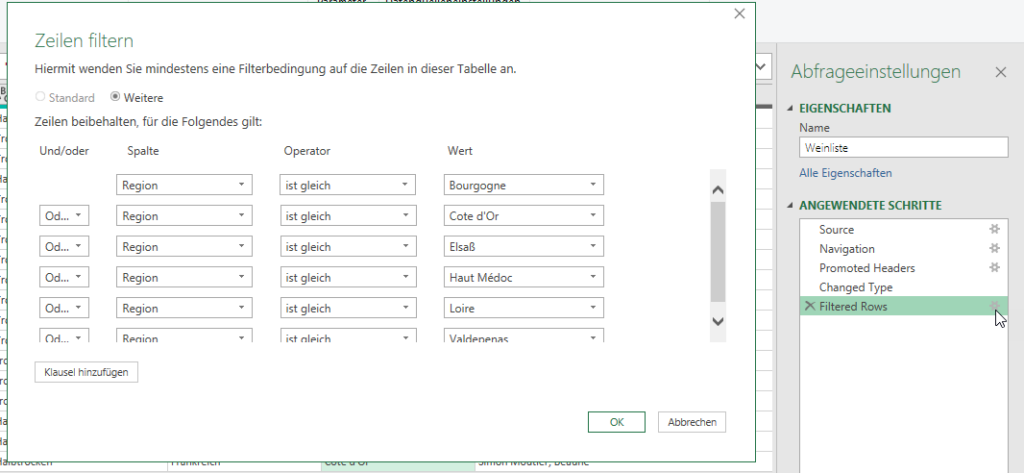
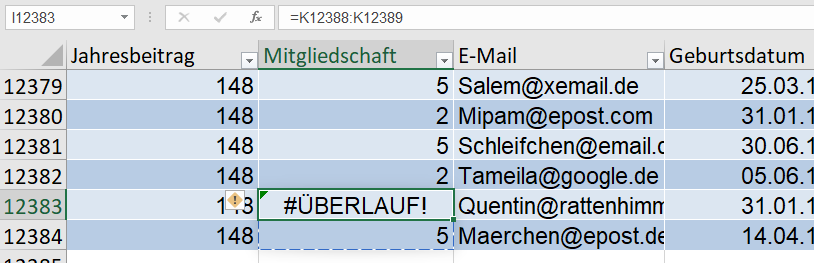
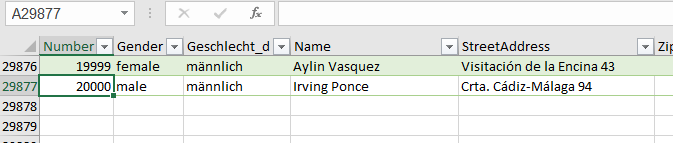
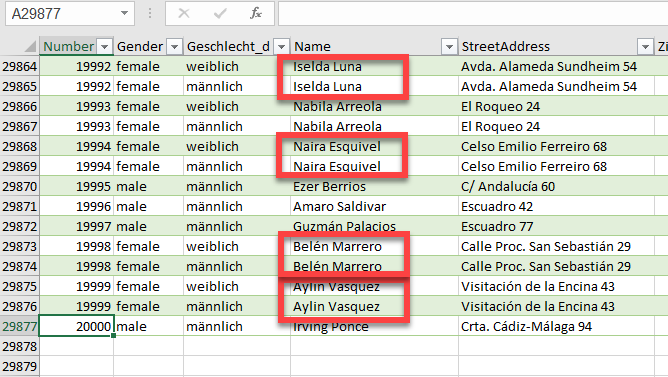
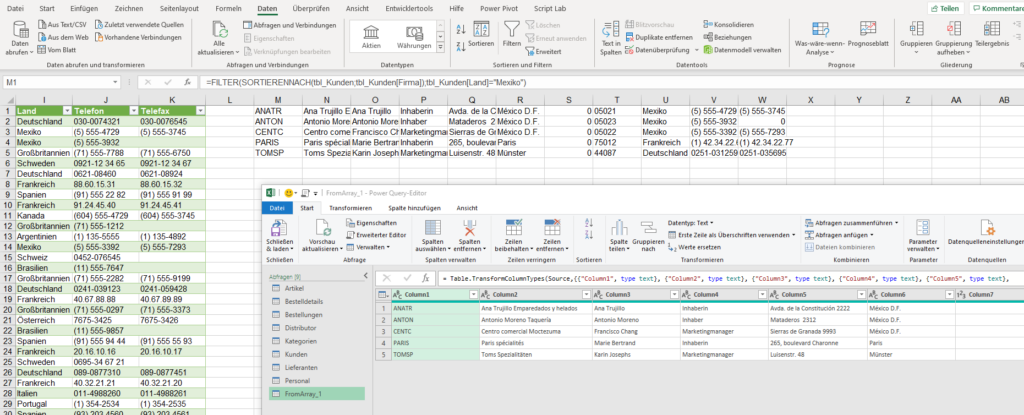
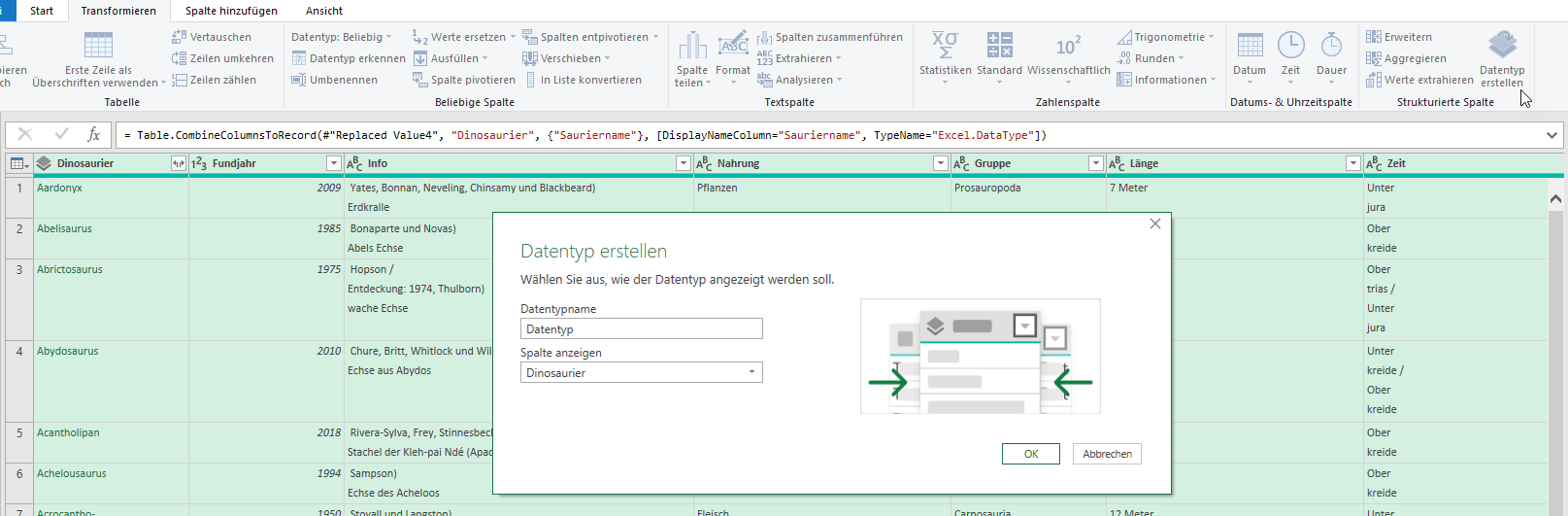
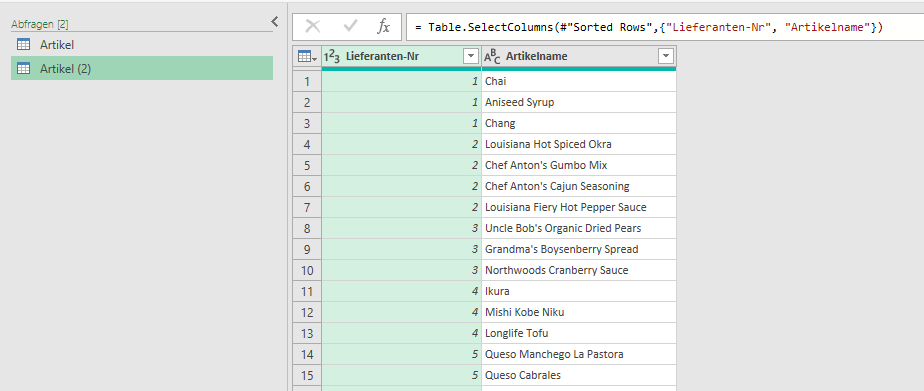
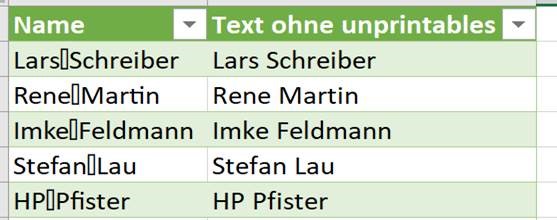
In der Spalte ‚Paarname‘ (12.000 Datensätze) sind viele Namen zu berichtigen.
Paarnamen die nicht geändert werden, sollen in der gleichen Spalte stehen.
Durch die Änderung der Umlaute habe ich gelernt, dass das mit einer Tabelle
gelöst werden kann.
Leider habe ich keine Formeln für die Namensänderungen gefunden 🙁
Vielen Dank Peter
Die AusgangslisteDie Suchen- und Ersetzen-Liste
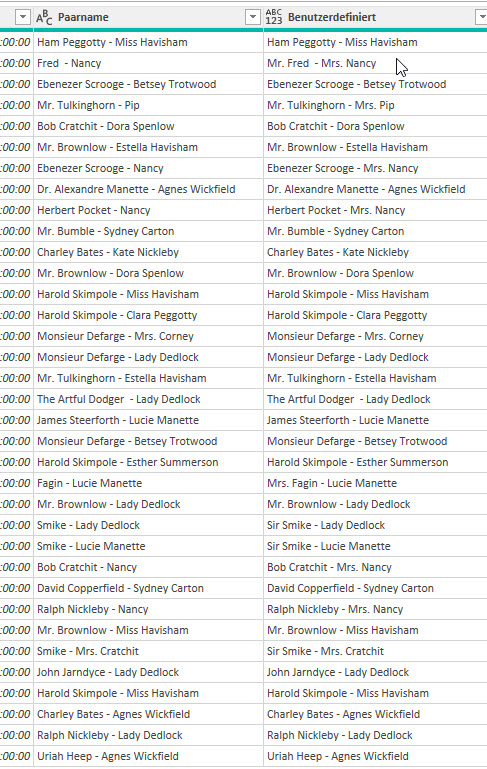
Hallo Peter,
mit dieser Funktion kannst du das lösen:
// Funktion: fnErsetzeNamen
// Parameter:
// text – der zu bearbeitende Text (z. B. aus der Spalte "Paarname")
// tabelleNamen – Tabelle mit den Spalten [suchen] und [ersetzen]
let
fnErsetzeNamen = (text as text, tabelleNamen as table) as text =>
let
// Alle Zeilen der Ersetzungstabelle abrufen
ersetzteTexte = List.Accumulate(
Table.ToRecords(tabelleNamen),
text,
(zustand, aktueller) => Text.Replace(zustand, aktueller[finden], aktueller[ersetzen])
)
in
ersetzteTexte
in
fnErsetzeNamen
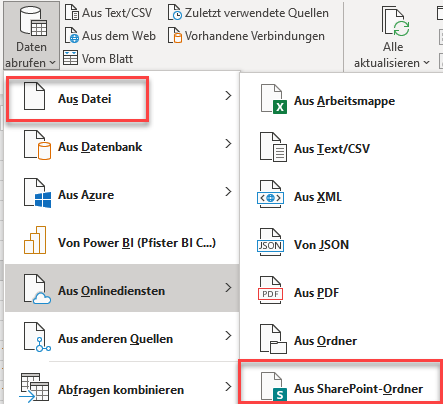
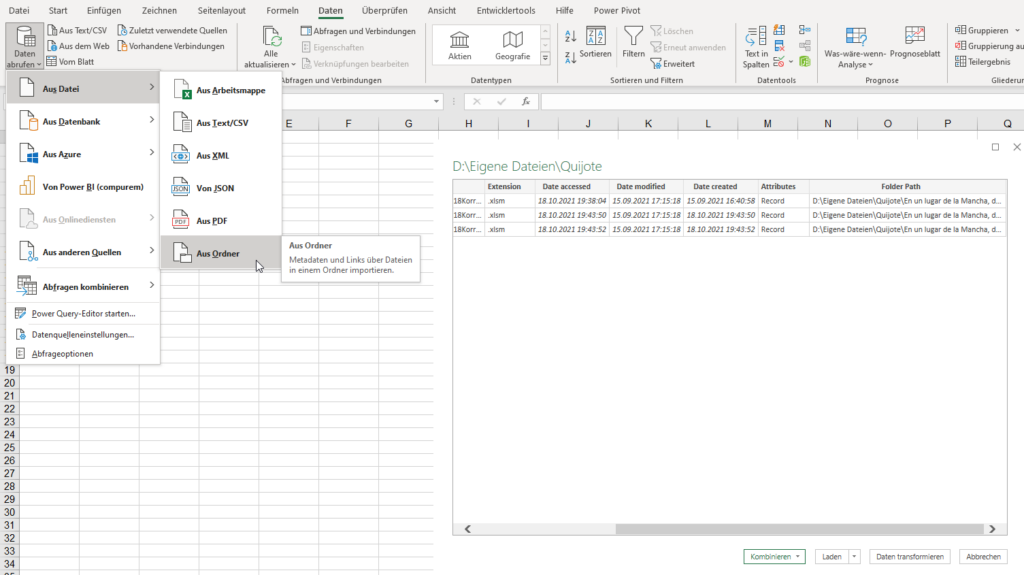
Schulung Power Query. Wir greifen auf Dateien eines Ordners zu.
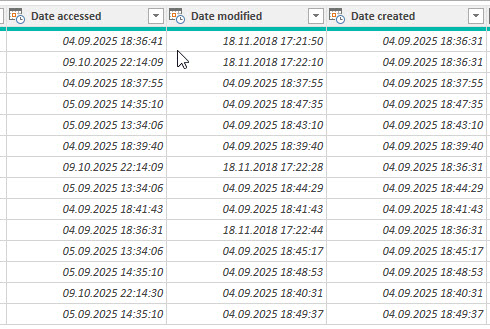
Eine Teilnehmerin fragt, was der Unterschied zwischen Date accessed und Date modified ist.
Ich bin nicht ganz sicher. Bevor ich Blödsinn erzähle, frage ich ChatGPT. Die Antwort:
🗓️ Date accessed („Zugriffsdatum“)
Zeigt an, wann eine Datei zuletzt geöffnet oder gelesen wurde.
Es bedeutet nicht, dass die Datei geändert wurde — nur, dass jemand oder ein Programm sie angesehen oder verwendet hat.
Beispiel: Wenn du eine Excel-Datei nur öffnest, um sie anzuschauen, und sie dann wieder schließt, → „Date accessed“ wird aktualisiert, → „Date modified“ bleibt gleich.
📝 Date modified („Änderungsdatum“)
Zeigt an, wann der Inhalt der Datei zuletzt geändert wurde.
Wenn du also in einer Datei etwas speicherst oder bearbeitest, → „Date modified“ wird auf diesen Zeitpunkt gesetzt.
Beispiel: Du öffnest die Datei, änderst Werte und speicherst sie, → „Date modified“ aktualisiert sich, → „Date accessed“ wird ebenfalls aktualisiert (weil du sie geöffnet hast).
💡 In Power Query
Wenn du z. B. den Ordnerinhalt über
Daten → Aus Ordner → Transformieren
lädst, siehst du oft beide Spalten:
Date accessed
Date modified
Du kannst also entscheiden:
Willst du wissen, wann zuletzt jemand auf die Datei zugegriffen hat → Date accessed
Willst du wissen, wann sie inhaltlich zuletzt geändert wurde → Date modified
wir hatten doch im Sommer das PowerQuery Seminar mit Ihnen.
Wir kann ich nochmal Word Dateien mit Tabellen nach Excel in PowerQuery bearbeiten ohne vorher in PDF umzuwandeln?
Was hatten Sie hier herausgefunden?
Freundliche Grüße
####
Hallo Frau M.,
sorry – das geht nicht! Power Query hat keinen Connector für Word. Sie müssen es entweder als PDF speichern oder als HTML. Oder nach Excel kopieren oder als Textdatei speichern …
Sorry!
Liebe Grüße
Rene Martin
####
Hallo Herr Martin,
Danke für die Info. Hab mir jetzt ein Makro gebaut, was mir alle Words in PDF automatisch umwandelt und dann kann ich PowerQuery nutzen.
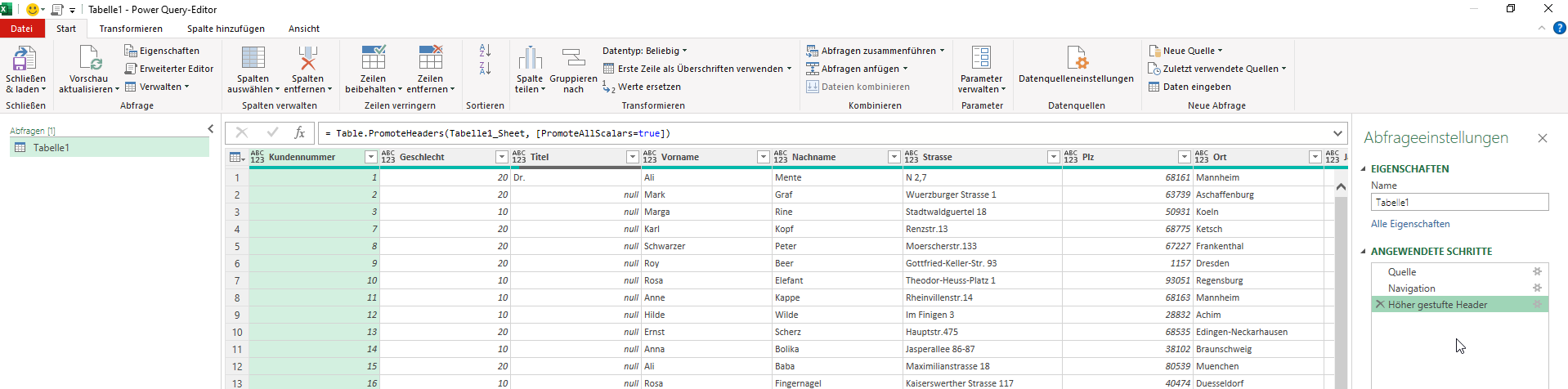
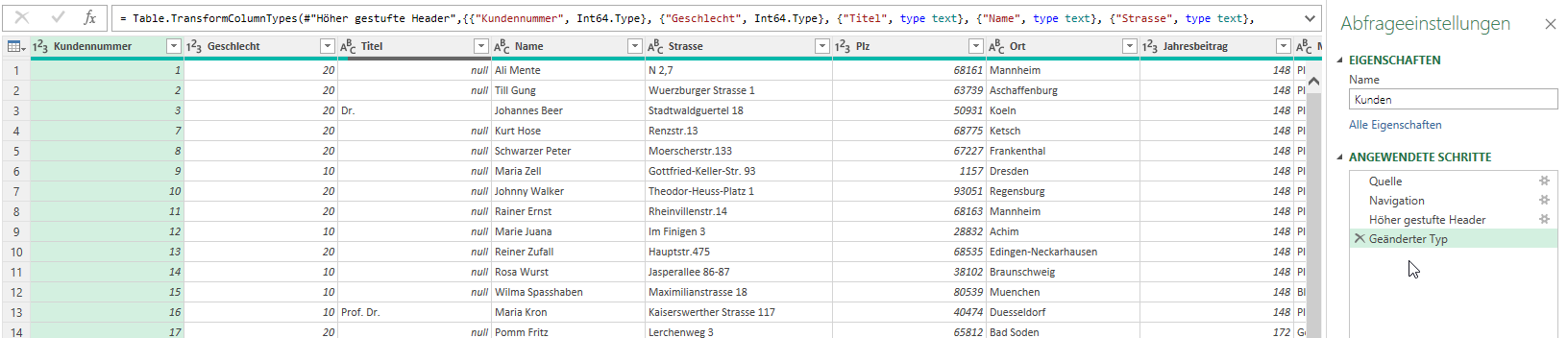
In einer Excelliste befinden sich Rechnungsnummern als Zahlen. Jedoch wird diese Liste an einigen Stellen durch Texte unterbrochen. Auf diese Liste greift Power Query zu:
Bei der Transformation muss die erste Zeile als Überschrift verwendet werden:
Dadurch fügt Power Query nun zwei Schritte ein – der Datentyp wird auch automatisch bestimmt (diese Option wurde nicht deaktiviert):
Power Query hat sich für den Datentyp „Beliebig“ entschieden:
Ich ändere ihn auf „Zahl“ und bin erstaunt, dass kein Fehler erscheint:
Obwohl sich in Zeile 54 ein Fehler befindet:
Das Problem: Power Query hat den Datentyp „Any“ zugewiesen. Das Ändern des Datentyps bewirkt keine Änderung der Anzeige. Auch „Vorschau aktualisieren“ hilft erstaunlicherweise auch nicht.
Man muss zu einem anderen Schritt wechseln und dann wieder zurück – dann erscheint der Fehler!
Umgekehrt ebenso: Wird der Datentyp in „Text“ geändert, bleibt der Fehler stehen, obwohl er nicht mehr vorhanden ist. Auch hier hilft ein Wechsel zu einem anderen Schritt.
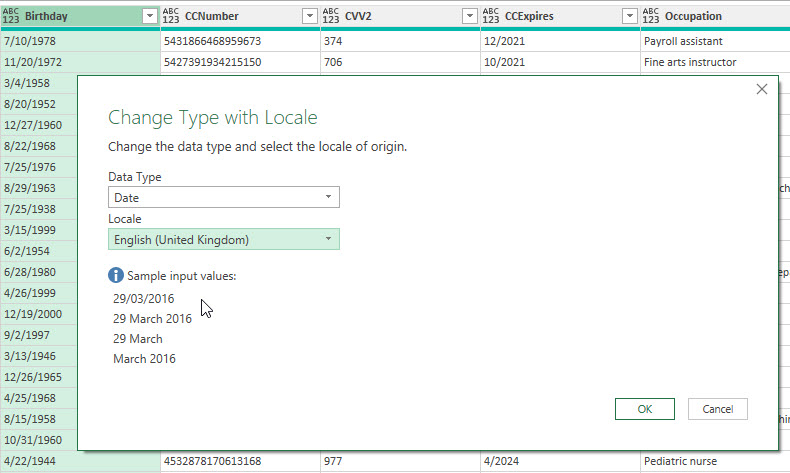
Power Query-Schulung. Englische Unterrichtssprache; britische Teilnehmer und Teilnehmerinnen. Da die Firma eine deutsche ist, verwenden sie als Dezimaltrennzeichen das Komma, als Datumsformat TT-MM-JJJJ.
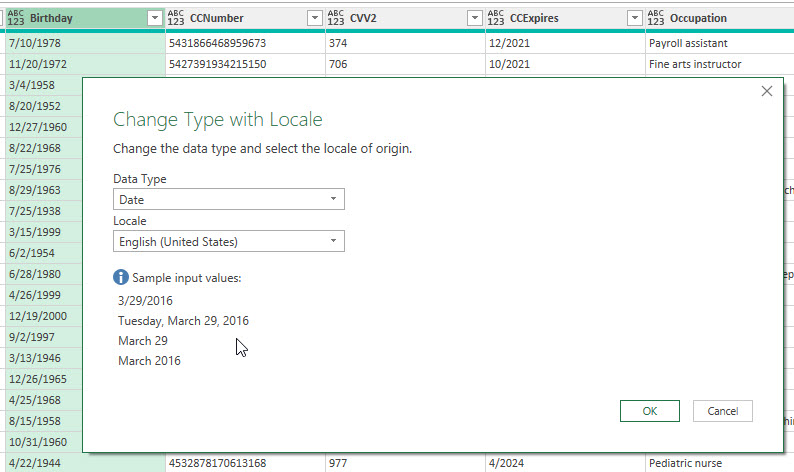
Ich zeige, wie man US-amerikanische Daten ins lokale Format konverviert. Eine Datumsspalte liegt in der Form MM/TT/JJJJ vor. Also zeige ich den Befehl „Using Locale“:
Klappt prima.
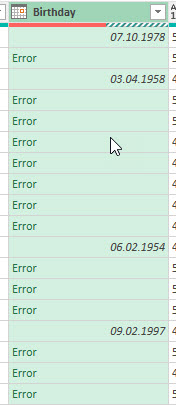
Eine Teilnehmerin meldet sich und sagt, dass bei ihr Fehler auftauchen:
Ich sehe es mir an:
Tatsächlich: Sie hat nicht genau hingeschaut und statt English (United States) aus Versehen English (United Kingdom) ausgewählt. Macht der Gewohnheit?
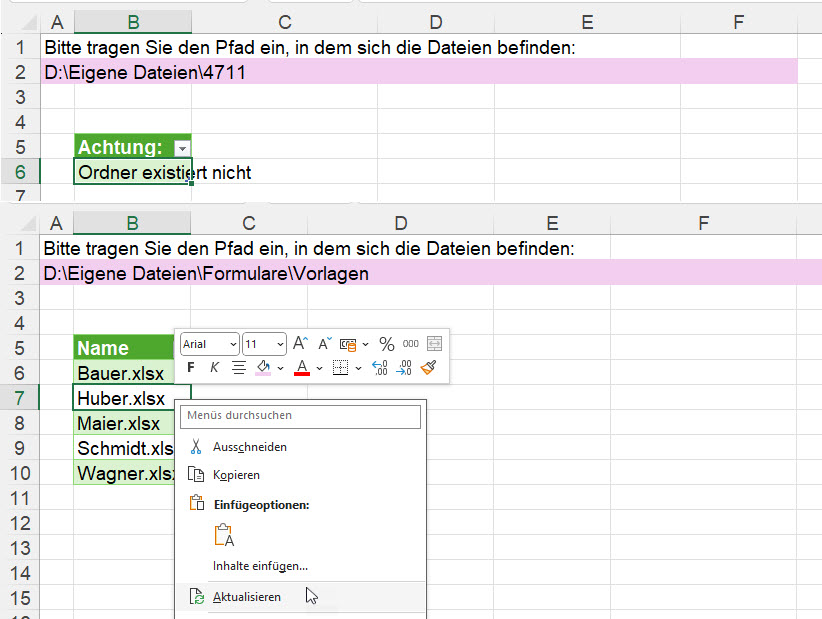
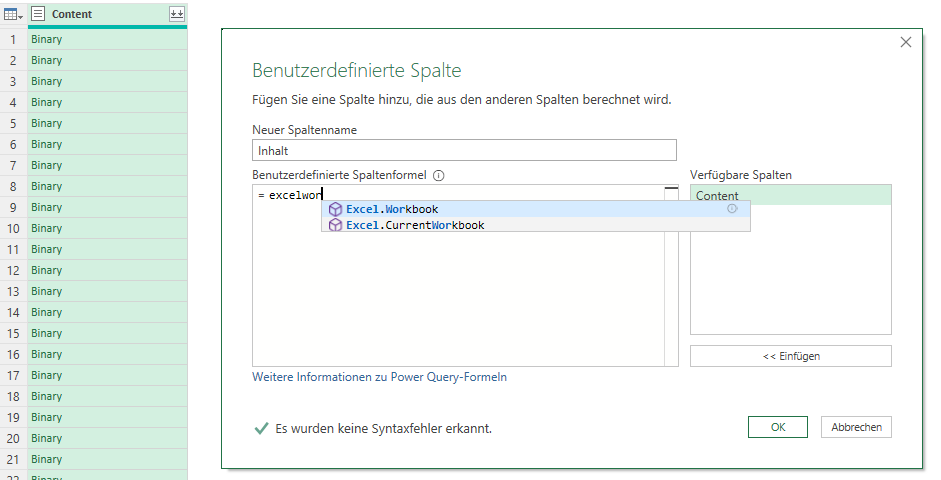
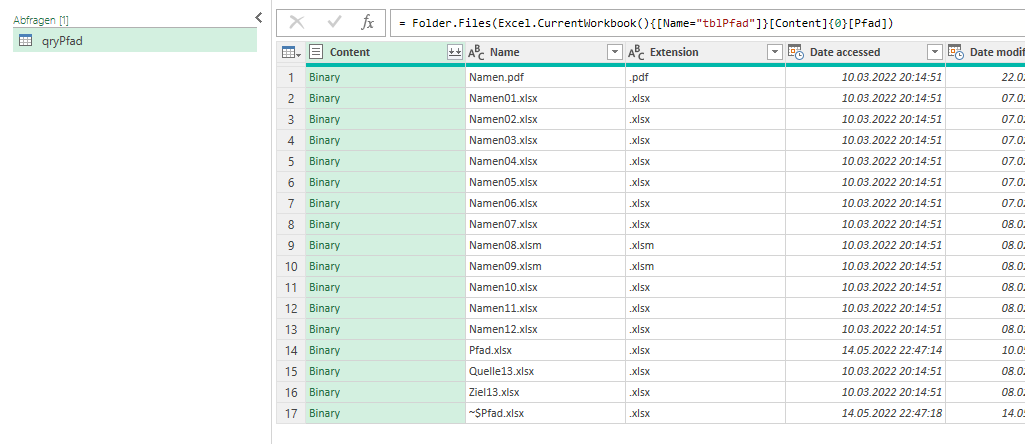
Ich erstelle häufig Power Query-Lösungen für Mitarbeiter und Mitarbeiterinnen verschiedener Firmen. Dabei werden oft Parameter in andere Zellen ausgelagert. Beispielsweise der Ordner, aus dem die Dateien herausgeholt werden.
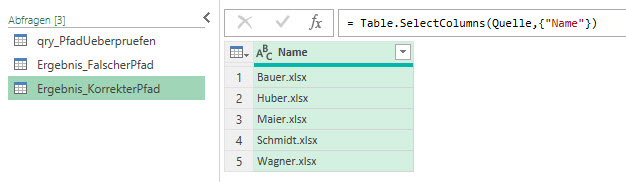
Sollte der Anwender nun einen falschen Ordnernamen eintragen, soll eine Fehlermeldung kommen. Das geht nicht in Power Query. Aber warum nicht eine Tabelle mit dem Hinweis, dass dieser Ordner nicht existiert. Bei korrekter Eingabe erfolgt die Transformation und das Laden der gewünschten Tabelle in Excel. Hier eine Auflistung der Dateinamen des Ordners:
Wie macht man so etwas?
Man benötigt eine Weiche.
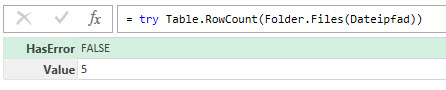
Der eingetragene Pfad wird als Tabelle/Bereich in Power Query verwendet. Nun kommt der Befehl try ins Spiel, der entweder einen Fehler produziert oder nicht. Und je nachdem – Fehler oder nicht – wird die eine Abfrage oder die andere Abfrage aufgerufen. Hier der Code:
let
Dateipfad = Excel.CurrentWorkbook(){[Name="Pfad2"]}[Content]{0}[Column1],
// holt den eingetragenen Verzeichnisnamen aus der Zelle, die "Pfad2" heißt
Quelle = try Table.RowCount(Folder.Files(Dateipfad)),
// der try-Befehl
Ausgabe = if Logical.From(Quelle[HasError]) then Ergebnis_FalscherPfad else Ergebnis_KorrekterPfad
// Weiche zu der Abfrage/Tabelle, welche angezeigt wird, wenn der Pfad korrekt oder falsch ist
in
Ausgabe
man probiert also irgendeinen Befehl, beispielsweise Folder.Files. Der Befehl try hat den Parameter HasError, der True oder False liefert – je nachdem, ob Fehler oder nicht:
PowerBI-Schulung. Eine Teilnehmerin sagt, dass sie nicht eine Tabelle aus einer Excelarbeitsmappe abrufen könne. Die Schaltfläche „Daten transformieren“ sei ausgegraut:
Klar: Sie hat den Fehler selbst schnell entdeckt: Sie muss das Kontrollkästchen aktivieren. Warum hatte sie es vergessen?
Vorher haben wir Power Query in Excel geübt: DORT genügt eine einfache Auswahl der Tabelle:
Schöne Frage in der Power Query-Schulung: kann man mit Power Query die Daten des XML-Dokuments einer e-Rechnung, die im ZUGFeRD-Format erstellt wurde, also aus dem PDF, auslesen?
Greift man mit dem Connector XML auf das PDF-Dokument zu, werden nur die PDF-Informationen angezeigt, aber nicht die internen XML-Daten:
Ich wüsste nicht, wie man das mit Power Query-Mitteln lösen könnte …
Kann man mit Power Query auf Word, oder besser: auf Word-Tabellen, zugreifen?
Nein!
Aber man kann ein Word-Dokument als PDF speichern.
Beispiel: in diesem Dokument befindet sich eine Tabelle:
Wie man sieht, ragt die Tabelle über die Seite hinaus.
Speichert man es als PDF und greift darauf zu, zerlegt Power Query das Dokument in mehrere Tabellen (so werden sie wohl intern gespeichert) und Seiten.
Beim Transformieren fällt auf, dass die letzten Spalten, also die Spalten, die zwar im Worddokument vorhanden waren, aber nicht in das PDF gespeichert wurden, nicht mitgenommen wurden:
Was tun?
Die Antwort: Die Tabelle in Word auf eine Seite quetschen. Entweder die Spalten sehr klein machen oder die Schriftgröße auf einen Punkt setzen:
Da Power Query Formatierungen übergeht, werden JETZT alle Daten der PDF-Datei gezogen:
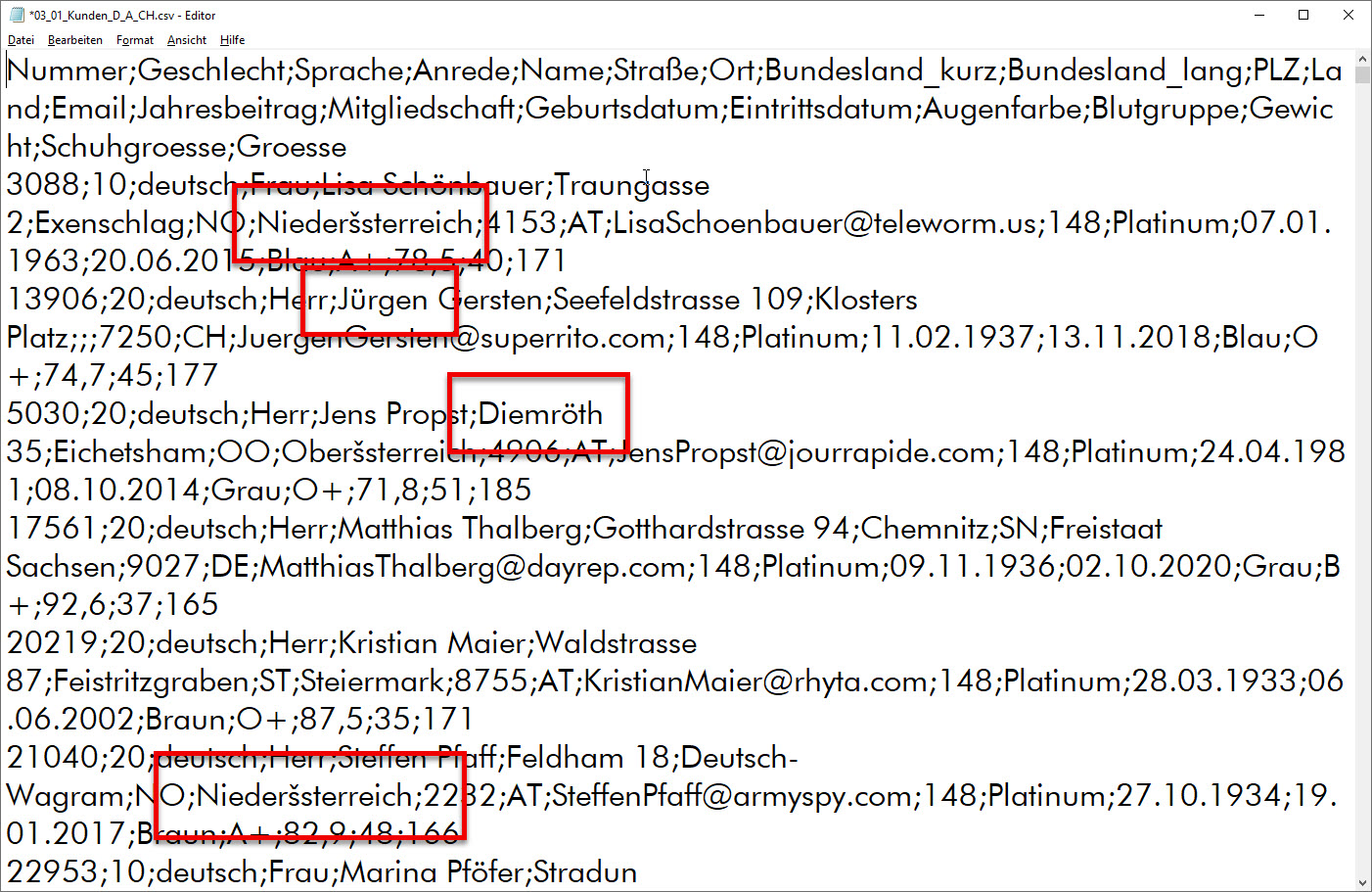
ich verstehe nicht ganz: du hast die Excel-Mappe durch PowerQuery auf Basis der CSV-Datei erzeugt? Wenn ich die CSV-Datei im Editor öffne, dann sehe ich dort: „Niederšsterreich“, aber ich sehe auch „Jürgen“
Das heißt: einige der Umlaute sind in der CSV-Datei schon zerschossen – DAS bekommst du auch in Power Query nicht sauber importiert (es sei denn mit Ersetzen).
####
Hallo Rene!
Vielen, vielen Dank für die schnelle Hilfe.
Nicht kontrolliert habe ich leider die CSV-Datei.
Klar, dass Power Query falsche Zeichen nicht automatisch umändern kann.
Heute in der Power Query-Schulung: „Wir haben mehrere Hundert SQL-Datenbanken“. Wie kann ich auf ALLE Datenbanken zugreifen?“
Natürlich kann man mit Power Query auf alle DATEIEN zugreifen, die in einem Ordner liegen: Excelmappen, Textfiles, CSV-Dateien … Aber SQL-Datenbanken – ich glaube nicht, dass man sie mit „einem Klick“ anzapfen kann …
Warum der Befehl „Alle aktualisieren“ bei Power Query nur in der Registerkarte „Tabellenentwurf“ zu finden ist, will ein Teilnehmer der Power Query-Schulung wissen.
Wirklich erstaunlich: In der Registerkarte „Abfrage“ ist kein Symbol vorhanden; im Kontextmenü auch nicht.
Er schlägt vor, dieses Symbol in die Symbolleiste für den Schnellzugriff aufzunehmen. Gute Idee! Am besten gleich neben die beiden Symbole „Abfragen und Verbindungen“ und „Power Query-Editor starten“. Damit Excel ein bisschen weniger nervt …
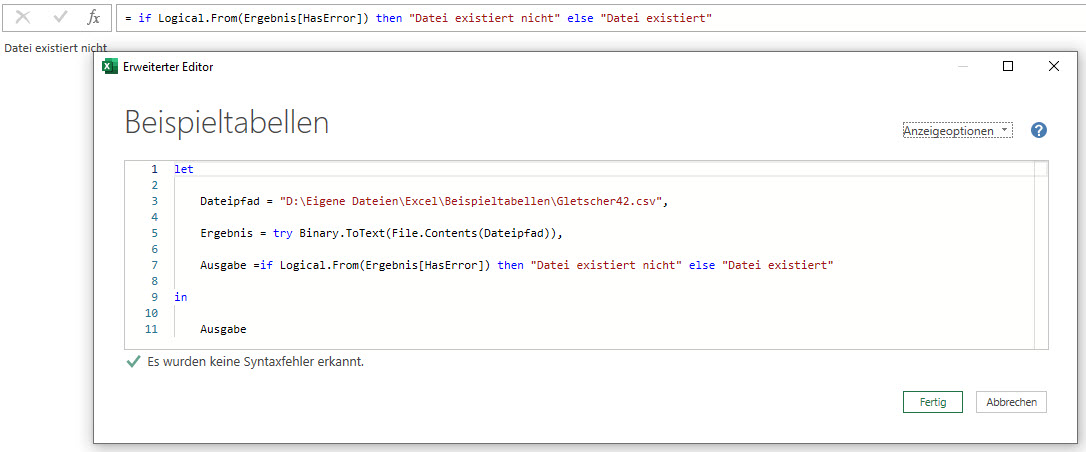
Ich schreibe in Power Query ein kleines Programm, das überprüft, ob eine Datei vorhanden ist. Während „Gletscher.csv“ existiert, gibt es die Datei „Gletscher42.csv“ nicht in meinem Ordner. Beide Varianten funktionieren hervorragend:
Der Code:
let
Dateipfad = "D:\Eigene Dateien\Excel\Beispieltabellen\Gletscher42.csv",
Ergebnis = try Binary.ToText(File.Contents(Dateipfad)),
Ausgabe = if Logical.From(Ergebnis[HasError]) then "Datei existiert nicht" else "Datei existiert"
in
Ausgabe
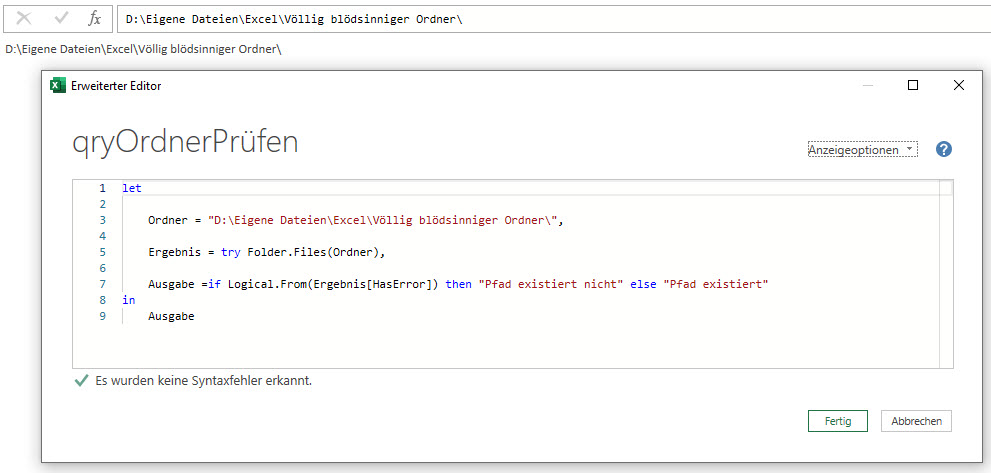
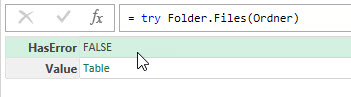
Versuche ich das Gleiche mit einem Ordner, liefert der try-Befehl bei HasError immer ein False. Behauptet also, dass der Ordner vorhanden ist.
Der Code:
let
Ordner = "D:\Eigene Dateien\Excel\Völlig blödsinniger Ordner\",
Ergebnis = try Folder.Files(Ordner),
Ausgabe = if Logical.From(Ergebnis[HasError]) then "Pfad existiert nicht" else "Pfad existiert"
in
Ausgabe
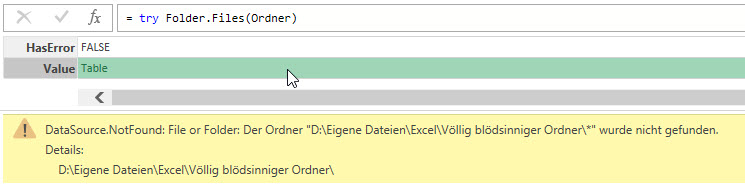
Die zweite Zeile zeigt es deutlich: HasError ist immer False:
Obwohl Power Query bei HasError keinen Fehler wirft, wird die Tabelle nicht gefunden – dort taucht ein Fehler auf:
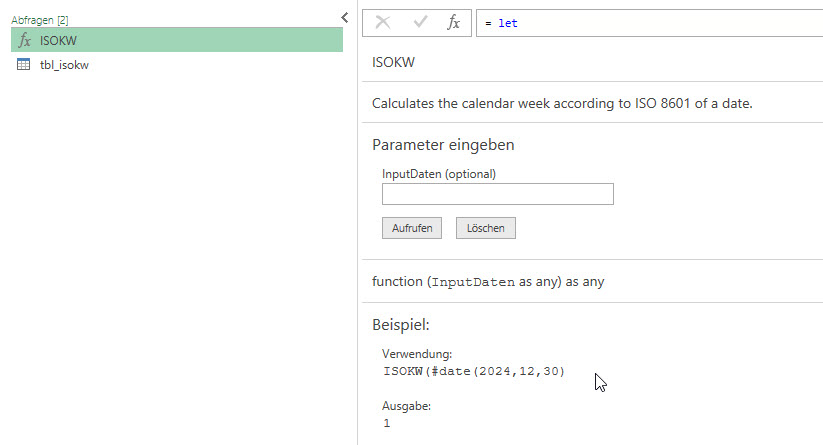
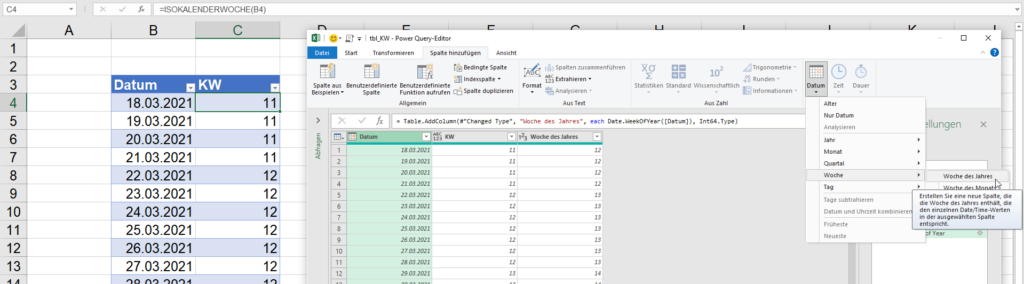
Ernst schickt mir eine Lösung zur korrekten Berechnung der Kalenderwoche nach ISO in Power Query:
Hallo Rene,
Du hast in letzter Zeit mehrere Beiträge zu Power Query gepostet. Vor einiger Zeit habe ich eine Möglichkeit beschrieben, die Iso-Kalenderwoche mit WORD-Feldfunktionen zu berechnen. Nun habe ich den verwendeten Algorithmus auf Power Query „M“ übertragen.
Die benutzerdefinierte Funktion sieht sieht dann in der einfachen Variante wie folgt aus.
InputDaten as any) as any => let Quelle = DateTime.Date(InputDaten), Wochentag = Date.DayOfWeek(Quelle,Day.Monday)+1, Jahr = Date.Year(Date.AddDays(Quelle, 4-Wochentag))-1 IsoKw = Number.IntegerDivide(Duration.Days(Quelle – #date(1901,1,1)) – Wochentag-Duration.Days(#date(Jahr,12,21) – #date(1901,1,1)),7) in IsoKw
In einer Version, in der eine Erläuterung mit angezeigt wird sieht sie wie folgt aus.
let //Errechnet die Kalenderwoche nach ISO 8601 eines Datums. ISOKW = let Function = (InputDaten as any) as any => let Quelle = DateTime.Date(InputDaten), Wochentag = Date.DayOfWeek(Quelle,Day.Monday)+1, Jahr = Date.Year(Date.AddDays(Quelle, 4-Wochentag))-1, FunctionResult = Number.IntegerDivide(Duration.Days(Quelle-#date(1901,1,1))-Wochentag-Duration.Days(#date(Jahr,12,21)-#date(1901,1,1)),7) in FunctionResult, FunctionType = type function (InputDaten as any) as any meta [ Documentation.Name = „ISOKW“, Documentation.LongDescription = „Calculates the calendar week according to ISO 8601 of a date.“, Documentation.Examples = { [Description = „“, Code = „ISOKW(#date(2024,12,30)“, Result = „1“] } ], TypedFunction = Value.ReplaceType(Function, FunctionType) in TypedFunction in ISOKW
Was mir an dieser cleveren Lösung gut gefällt, ist der Teil der Metadaten. Diese Teile werden beim Selektieren der Funktion angezeigt. Große klasse!
Hallo Rene,
wie ich gesehen habe, hast Du meinen Beitrag zur Berechnung der Iso-Kalenderwoche veröffentlicht. Ich habe noch eine kurze Anmerkung zu dieser PQ-Funktion.
Die Zeile FunctionResult = Number.IntegerDivide(Duration.Days(Quelle-#date(1901,1,1))-Wochentag-Duration.Days(#date(Jahr,12,21)-#date(1901,1,1)),7) kann durch die kürzere Version FunctionResult = Number.IntegerDivide(Duration.Days(Quelle-#date(Jahr,12,21))-Wochentag,7) ersetzt werden.
Außerdem habe ich die Verwendung von Metadaten in eine weitere benutzerdefinierte Funktion (TrimAll) integriert.
Diese Funktion entfernt die führenden und nachfolgenden Leerzeichen aus einem Textwert und ersetzt alle Mehrfachleerzeichen durch ein einzelnes Leerzeichen.
___________________________
Let // Erstellt von Ernst-A. Börgener //Entfernt die führenden und nachfolgenden Leerzeichen aus einem Textwert und ersetzt alle mehrfachen Leerzeichen durch ein einzelnes Leerzeichen. TrimAll = let Function = (InputDaten as any) as any => let FunctionResult = try Text.Combine(List.RemoveItems(Text.Split(InputDaten, “ „),{„“}),“ „) otherwise InputDaten //Funktion TrimAll in FunctionResult, FunctionType = type function (InputDaten as any) as any meta [ Documentation.Name = „TrimAll“, Documentation.LongDescription = „Removes the leading and trailing spaces from a text value and replaces all multiple spaces with a single space.“, Documentation.Examples = { [Description = „“, Code = „TrimAll(„“ Removes the leading and trailing spaces from a text value and replaces all multiple spaces with a single space. „“)“, Result = „““Removes the leading and trailing spaces from a text value and replaces all multiple spaces with a single space.“““] } ], TypedFunction = Value.ReplaceType(Function, FunctionType) in TypedFunction in TrimAll
_____________________
Um mit dieser Funktion eine ganze Tabelle zu bearbeiten reicht folgender Aufruf.
= Table.TransformColumns(Quelle,{}, TrimAll)
Durch die leere Liste als zweiten Parameter werden alle Spalten der Tabelle abgearbeitet.
Amüsant: ich greife mit Power Query in Excel (ein Programm aus dem Hause Microsoft) auf eine Seite von microsoft.com zu und werde gefragt, ob diese Seite wirklich vertrauenswürdig ist:
Traut Microsoft sich selbst nicht über den Weg?
Nein – ich glaube eher, dass sie im Vorfeld KEINE Ausnahmen implementieren wollten.
Ich habe mich noch etwas mit dem „Altersproblem“ beschäftigt und dabei eine Alternative im Netz von Imke Feldmann entdeckt:
(Startdatum as date, Enddatum as date) =>
let
StartdatumINT = Date.Year(Startdatum) * 10000 + Date.Month(Startdatum) * 100 + Date.Day(Startdatum),
EnddatumINT = Date.Year(Enddatum) * 10000 + Date.Month(Enddatum) * 100 + Date.Day(Enddatum),
Alter = Number.IntegerDivide((EnddatumINT - StartdatumINT),10000)
in Alter
Gruß
Christian
Stimmt, Christian,
diese Lösung – den Monat mit einer sehr großen Zahl und den Tag mit einer kleineren zu multiplizieren, habe ich vergessen. Die Lösung habe ich auch vor vielen Jahren mal irgendwo gefunden. Auch clever.
Ich habe gestern darauf hingewiesen, dass die Altersberechnung von Power Query (es wird die Anzahl der Tage durch 365 dividiert und damit die Schalttage übergangen) sehr unscharf ist.
Man kann durch 365,25 (geschrieben: 365.25) dividieren. Das stimmt.
Oder nicht?
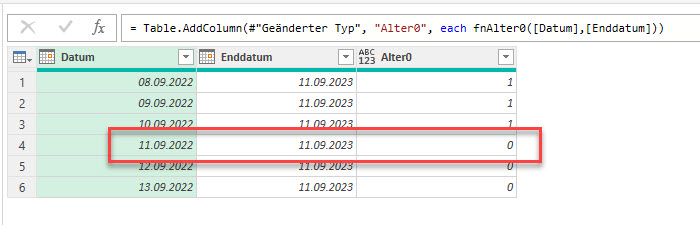
Nein – leider nicht ganz. Das Jahr 2024 war ein Schaltjahr, das heiß: es gab einen 29.02.2024.
Heute ist der 11.09.2024
Die Anzahl der Tage zum 11.09.2023, 11.09.2022 und 11.09.2021 betragen 366, 731 und 1096 Tage. Teilt man diese Zahlen durch 365.25 erhält man 1,0020534 beziehungsweise 2,0013689 und 3,0006845
Abgerundet also die Zahlen 1, 2 und 3
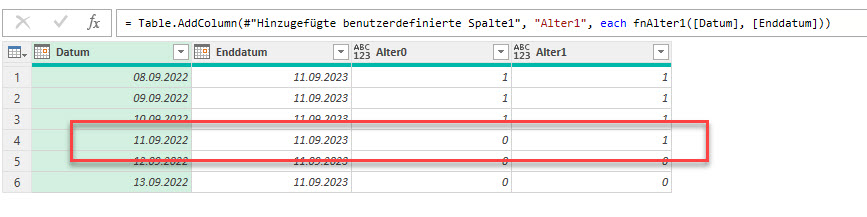
Angenommen heute wäre der 11.09.2023 (also kein Schaltjahr). Dann beträgt die Differenz zum 11.09.2022, 11.09.2021 und 11.09.2020 als Ergebnis 0,9993155 beziehungsweise 1,9986311 und 2,9979466 – oder abgerundet:
0, 1 und 2
In den Nicht-Schaltjahren bleibt ein Tag Differenz: das bedeutet: Er oder sie wird erst „einen Tag später“ ein Jahr älter.
Wir erstellen in Power Query eine einfache Funktion:
(Anfangsdatum as date, Enddatum as date) =>
Number.RoundDown(Duration.Days(Enddatum - Anfangsdatum) / 365.25)
Randbemerkung: Leider kann man nicht Enddatum – Anfangsdatum rechnen (wie in Excel), sondern muss das Ergebnis mit Duration.Days in eine (Tages-)Zahl konvertieren.
Und so zeigt sich die Unschärfe von einem Tag:
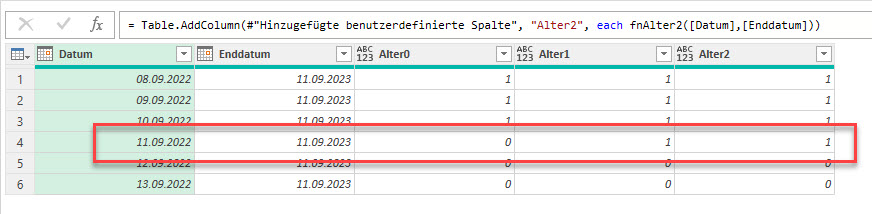
Richtig wäre folgende Berechnung: Jahr vom Ende minus Jahr vom Anfang.
Wenn der Monat des Enddatums kleiner als der Monat des Anfangsdatums, dann muss 1 abgezogen werden.
Wenn beide Monate gleich, allerdings der Tag des Enddatums kleiner als der Tag des Anfangsdatums, dann muss 1 abgezogen werden (umgangssprachlich: er oder sie hatte noch nicht in diesem Jahr Geburtstag). Oder als Formel:
(Anfangsdatum as date, Enddatum as date) =>
Date.Year(Enddatum) - Date.Year(Anfangsdatum) -
(if Date.Month(Enddatum) < Date.Month(Anfangsdatum) then 1 else
if Date.Month(Enddatum) = Date.Month(Anfangsdatum) and
Date.Day(Enddatum) < Date.Day(Anfangsdatum) then
1 else 0)
Rechnet korrekt:
Oder – man kann auch anders rechnen. Man transformiert das Anfangsdatum ins Jahr des Enddatums. Also: man holt Tag und Monat des Anfangsdatums und Jahr des Enddatums und baut ein Datum daraus.
Man berechnet Jahr minus Jahr.
Wenn das transformierte Datum größer als das Enddatum ist, muss noch 1 abgezogen werden.
Umgangssprachlich bei Geburtstagen: sollte er oder sie in diesem Jahr noch nicht Geburtstag gehabt haben, muss man 1 abziehen. Als Formel:
(Anfangsdatum as date, Enddatum as date) =>
Date.Year(Enddatum) - Date.Year(Anfangsdatum) -
(if #date(Date.Year(Enddatum), Date.Month(Anfangsdatum), Date.Day(Anfangsdatum)) > Enddatum then
1 else 0)
Klappt auch:
Natürlich sollte man das Enddatum optional setzen, beispielsweise so:
(Anfangsdatum as date, optional Enddatum as date) =>
let
EnddatumNeu = if
Enddatum is null then
Date.From(DateTime.LocalNow()) else
Enddatum,
Diff = Date.Year(EnddatumNeu) - Date.Year(Anfangsdatum),
Alter = Diff - (if
#date(Date.Year(EnddatumNeu), Date.Month(Anfangsdatum), Date.Day(Anfangsdatum)) > EnddatumNeu then
1 else 0)
in
Alter
Oh wie schön wäre eine Funktion DateDif oder DATEDIFF!
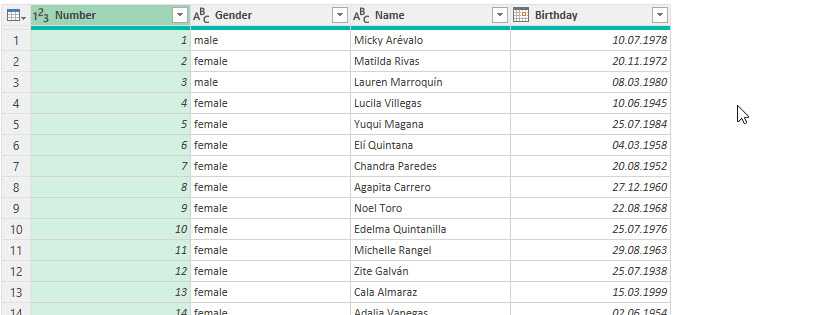
Gestern auf dem Excelstammtisch. Angelika (Angelika Meyer; https://www.asmeyer.de/) will es wissen:
Sie hat eine Liste mit Namen und Geburtstagsdaten. Diese werden in Power Query abgerufen:
Sie möchte das Alter berechnen und dann in einer Pivottabelle gruppieren, um einen Überblick über die Altersstruktur zu erhalten.
Es erstaunt:
Excel stellt die Funktion DATEDIF zur Verfügung
VBA stellt die Funktion DateDiff zur Verfügung
DAX stellt die Funktion DATEDIFF zur Verfügung
Und Power Query? Nichts dergleichen. Also per Hand:
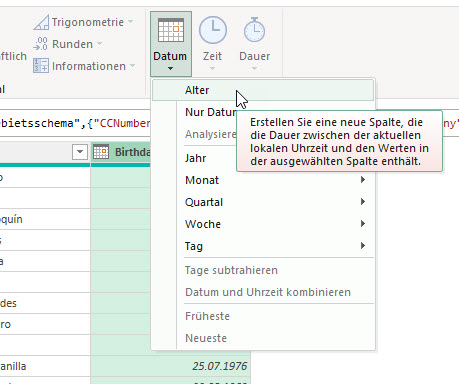
Über Spalte hinzufügen / Datum / Alter kann man eine berechnete Altersspalte erzeugen. Wirklich?
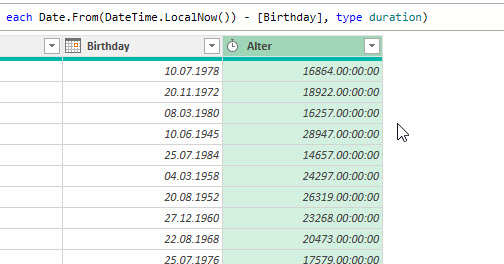
Das Ergebnis ist eine Dauer – genauer: die Differenz in Tagen zwischen dem aktuellen Datum und dem Geburtsdatum (hier: Spalte „Birthday“)
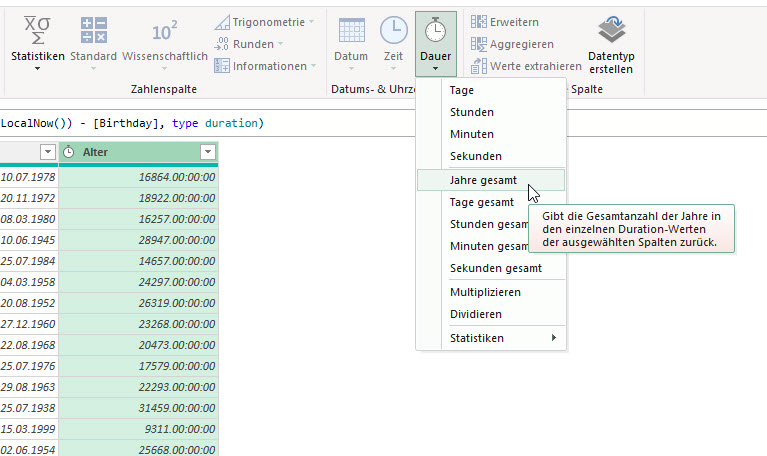
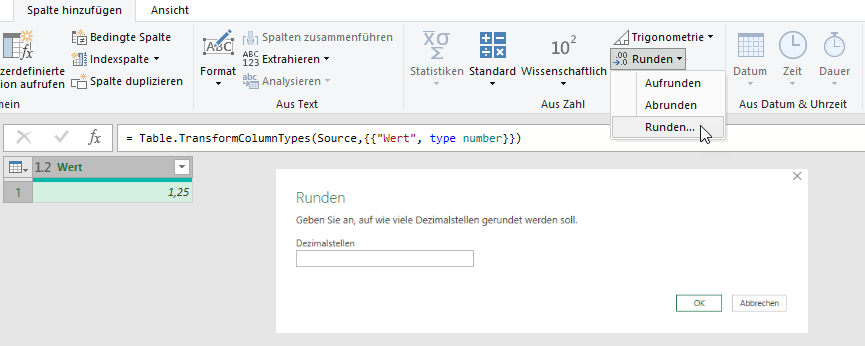
Im zweiten Schritt kann man über Transformieren / Dauer / Jahre gesamt diese Spalte in eine Jahreszahl verwandeln:
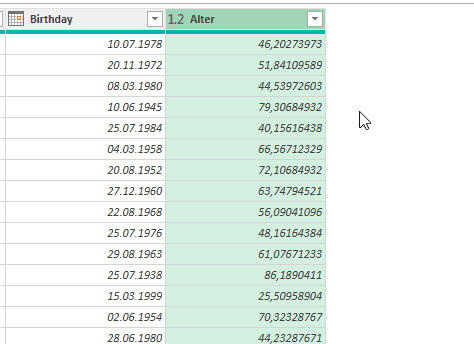
Das Ergebnis: Dezimalzahlen
Diese müssen abgerundet werden – hier hilft Transformieren / Runden / Abrunden:
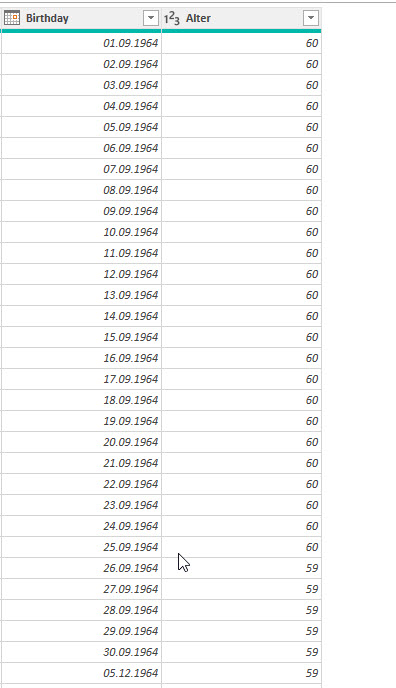
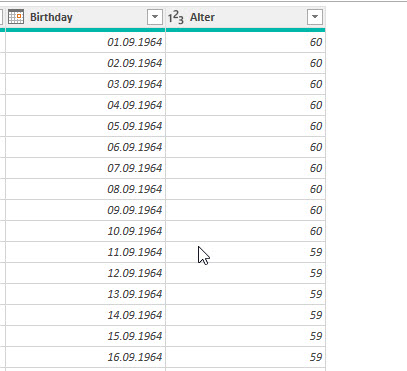
Aber ist das Ergebnis korrekt? Ich stutze. Wir probieren es. Heute ist der 10. September. Ich trage einige Geburtsdaten ein – vom 01.09 bis zum 30.09:
Bis zum 25. September sind diese Personen 60 Jahre als. Das ist falsch. Warum?
Ein Blick in den Code hilft. Power Query berechnet das Alter:
= Table.TransformColumns(#"Eingefügtes Alter",{{"Alter", each Duration.TotalDays(_) / 365, type number}})
Power Query teilt die Dauer durch 365. Dadurch werden Schaltjahre nicht berücksichtigt. Bei einem 60jährigen macht dies eine Differenz von 60/4 = 15 Tage aus. Wir versuchen den Code anzupassen:
= Table.TransformColumns(#"Eingefügtes Alter",{{"Alter", each Duration.TotalDays(_) / 365.25, type number}})
Wir teilen durch 365.25
Das Ergebnis ist besser:
Oder man muss eine eigene Funktion für dieses Problem erstellen.
Im Power Query kann man natürlich mit der Bildlaufleiste den Ausschnitt der Tabelle nach oben oder unten fahren. Markiert man eine Zelle, kann man ebenso mit der [Leertaste9 nach unten scrollen.
Umgekehrt scrollt die Tastenkombination [Shift] + [Leertaste] nach oben:
Beides zusammen scheint jedoch nicht zu funktionieren: erst runter dann rauf. Oder umgekehrt.
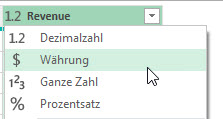
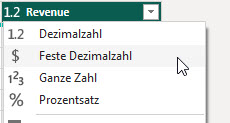
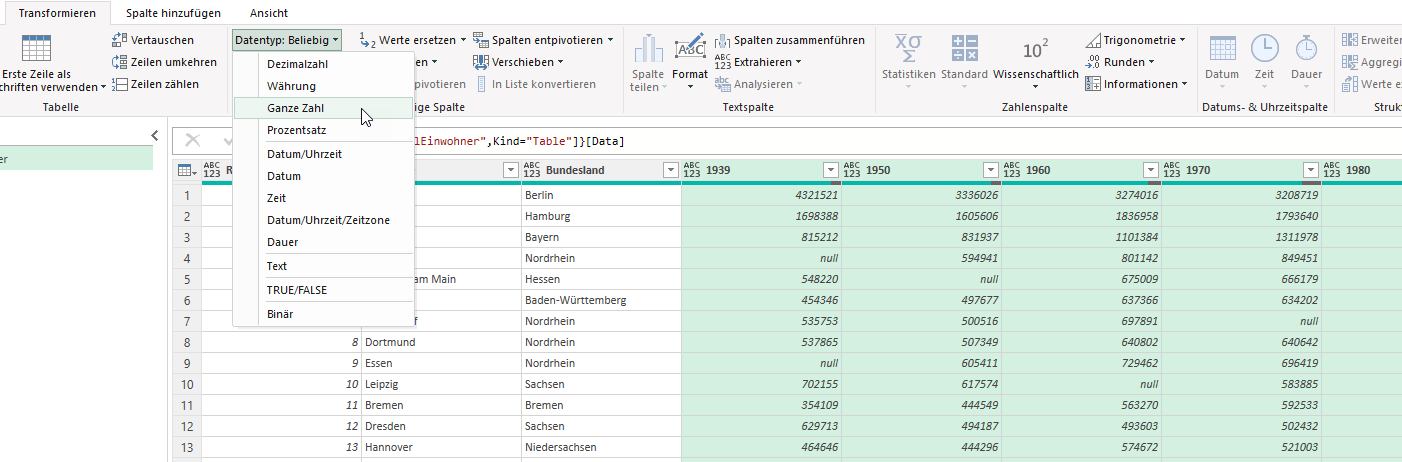
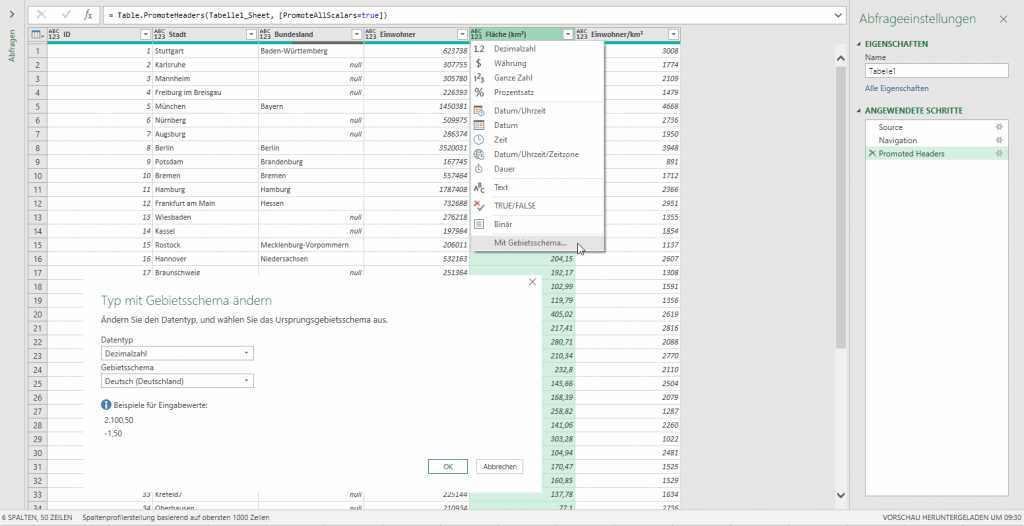
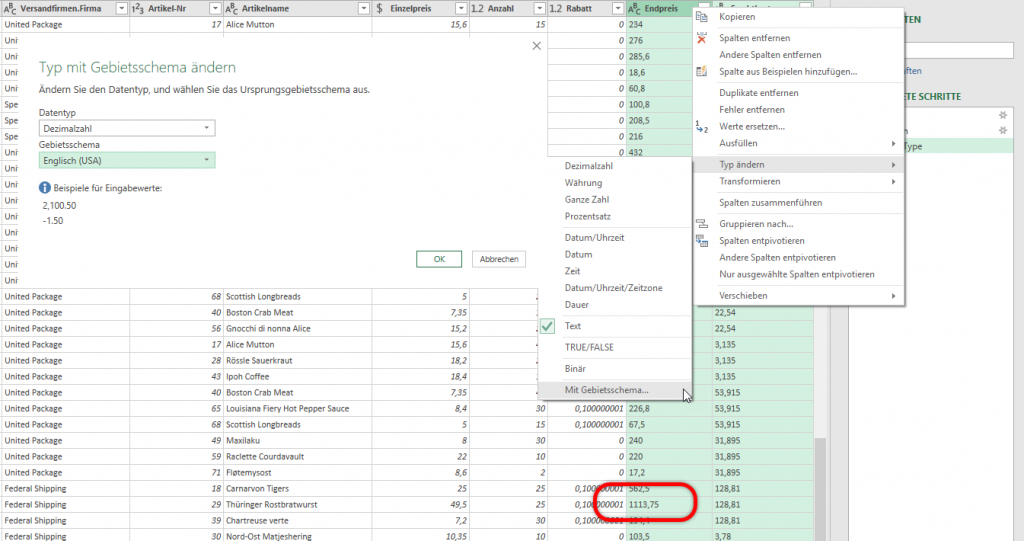
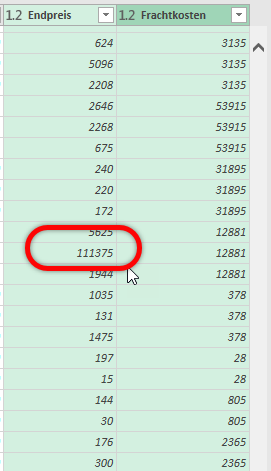
Hat man in Power Query zwei Spalten vom Datentyp Dezimalzahl oder Dezimalzahl und Prozentzahl und multipliziert sie und lässt dich das Ergebnis in einer benutzerdefinierten Spalte anzeigen, ist das Ergebnis – anders als Excel, wo das Zahlenformat Währung übernommen wird: Prozent * Währung -> Währung – nicht vom Zahlentyp Dezimalzahl, sondern vom Datentyp „beliebig“ (123 ABC). Fatal. Das sollte immer geändert werden.
In Power Query in Excel heißt das Zahlenformat „Währung“.
In PowerBI jedoch „Feste Dezimalzahl“
Beide Begriffe sind etwas „schräg“. Allerdings: eine genaue Definition „Dezimalzahl mit exakt vier Nachkommastellen für die Verwendung als Währungsformat“ oder ähnliches, wäre zu lang geworden.
Importiert man in Power Query aus einer Datenquelle, in der die Datentypen nicht festgelegt wurden (also beispielsweise aus Excel, einer Text- oder CSV-Datei), werden die Werte vom Datentyp beliebig festgelegt.
Das Symbol ABS 123 zeigt den Datentyp „beliebig“ an. Wandelt man ihn in ganze Zahlen um, werden die Werte verändert – klar!
Wendet man den Datentyp Währung an, werden zwei Nachkommastellen angezeigt:
jedoch nur vier gespeichert, wie man leicht feststellen kann, wenn man anschließend den Datentyp Text oder Dezimalzahl verwendet – die anderen Nachkommastellen werden so gelöscht!
In der letzten Power Query-Schulung erkläre ich, dass man in Power Query keine Zahlen formatieren kann. „Dezimal“ bedeutet die Fähigkeit Nachkommastellen zu verwenden, Währung bedeutet mit maximal vier Nachkommastellen. Ein Währungssymbol ist dagegen nicht möglich.
Ein Teilnehmer fragt, warum der Zahlentyp „Währung“ ein Tausendertrennzeichen und exakt zwei Nachkommastellen anzeigt; Dezimalzahl jedoch nicht.
Ich weiß es nicht.
Dennoch: formatiert wird in Excel respektive PowerBI.
Greift man mit Power Query auf eine Excel-Arbeitsmappe zu, kann man mehrere Tabellenblätter auswählen. Diese Option muss jedoch explizit aktiviert werden:
In Power Query in PowerBI ist dies jedoch nicht nötig:
Ich habe keine Ahnung, warum sich diese beiden Dialoge unterscheiden.
Diana Sperber hat zu Recht darauf hingewiesen: Fügt man in eine Excelmappe eine Tabelle ein, die auf einer Power Query-Abfrage beruht und schützt das Tabellenblatt, so kann man die Tabelle nicht mehr aktualisieren.
Letzte Woche auf dem Excelstammtisch hat uns Diana gezeigt, wie man in den automatisch generierten Code von Power Query eingreifen kann. Beispielsweise: greift man auf eine Excelmappe zu, dann schreibt Power Query folgende Zeile:
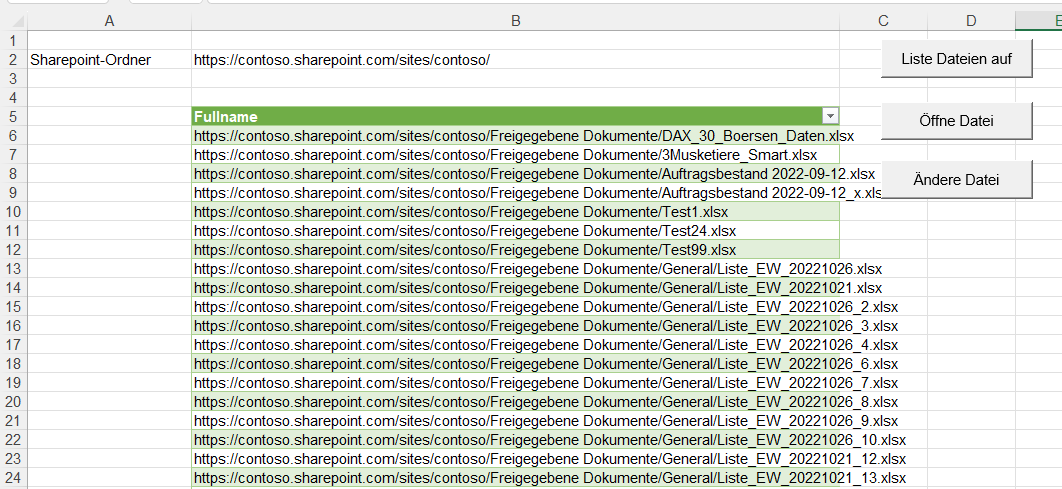
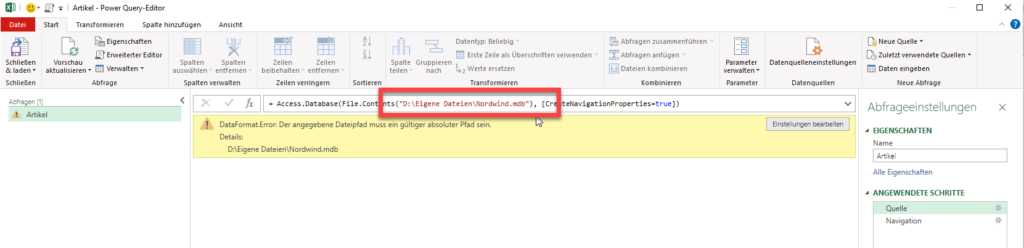
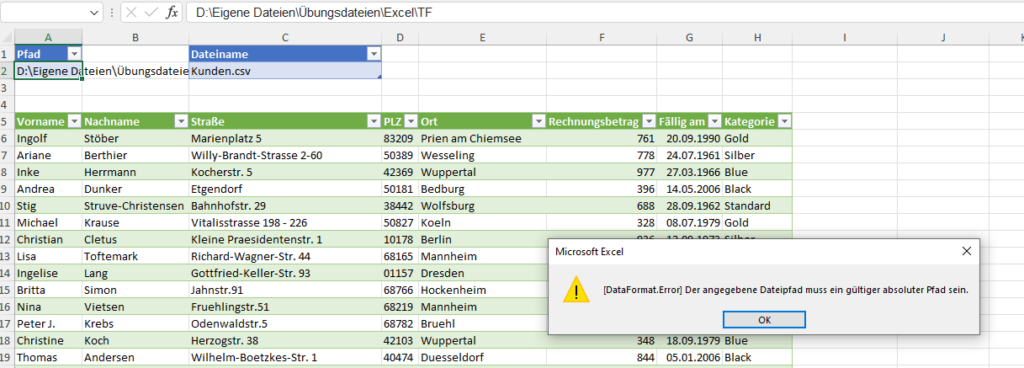
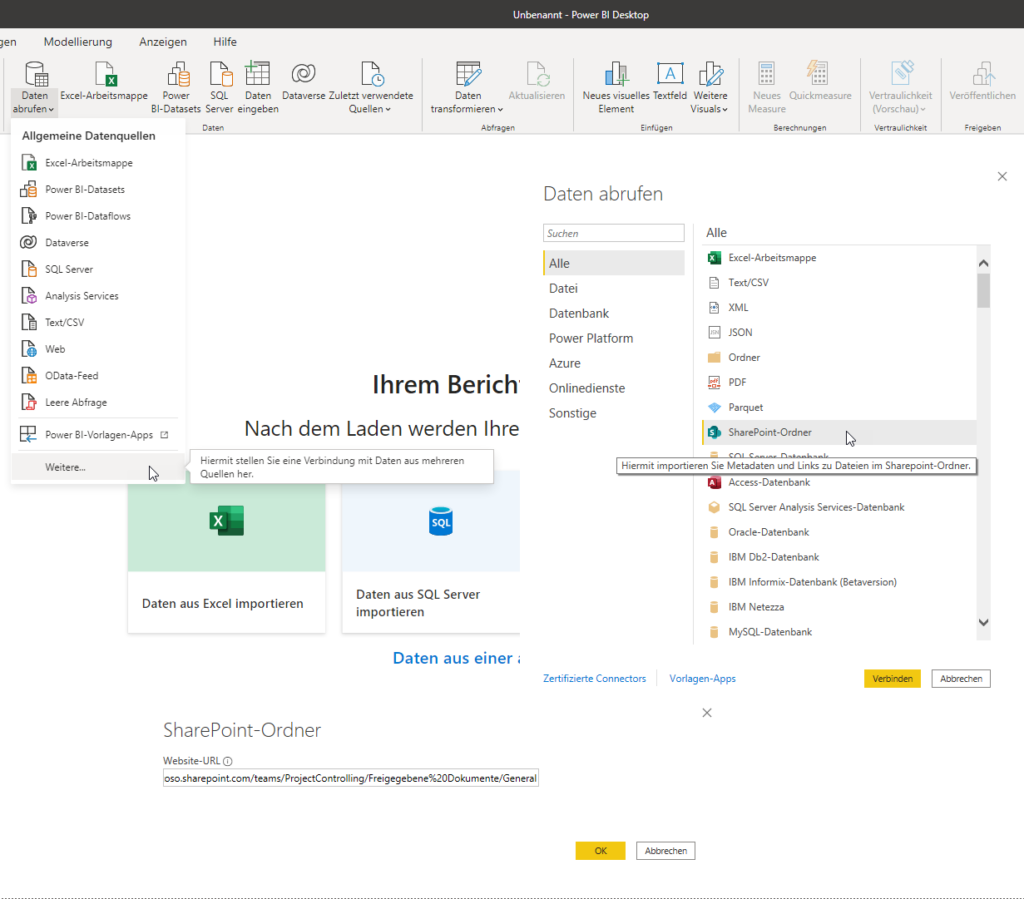
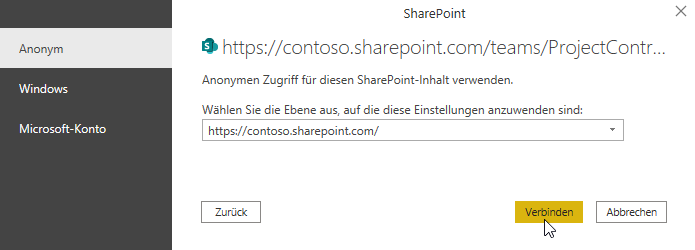
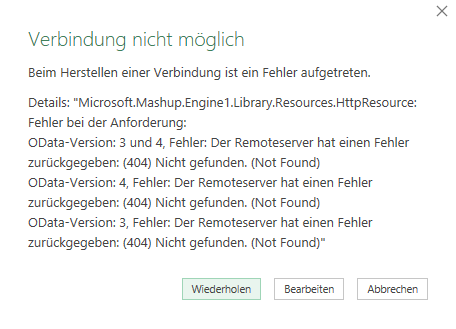
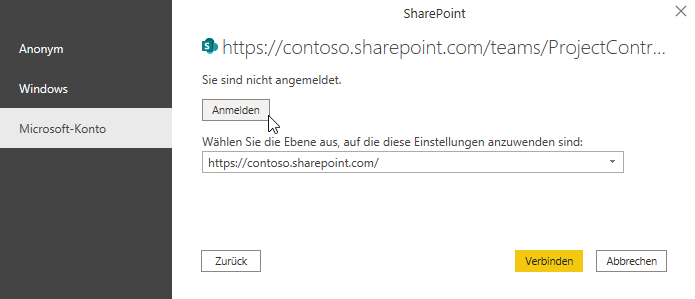
es ist schon eine Weile her, dass Sie uns bei der Entwicklung unserer Excel-Tabellen für die Kaufpreissammlung des Kommunalreferats geholfen haben. Ihr Ansatz, den Sie mit uns entwickelt haben, hatte die Arbeit der Fachabteilung maßgeblich beschleunigt. Mittlerweile habe ich den Arbeitgeber gewechselt und wollte nun das Einlesen des Pfades zu einer Datei auch hier so etablieren, dass wir kleine intelligente Tabellen haben, in welche der Pfad und in andere der Dateiname eingetragen werden kann. Allerdings scheint Excel ein Problem zu haben, wenn der Pfad auf einen SharePoint führt und nicht zum Explorer. Es erscheint die Fehlermeldung, dass es kein absoluter Pfad sei. Haben Sie evtl eine Idee, wie man Excel dazu bringen kann, einen SharePoint Pfad wie einen Explorer Pfad zu verwenden? Ich habe Ihnen die Datei, die wir damals entwickelt haben, angehängt, in der Hoffnung mein Problem damit erständlicher zu machen.
Ich würde mich freuen, wenn Sie mir einen Tipp geben könnten, der mich zur Problemlösung bring.
Herzliche Grüße,
Hallo Frau I.,
sorry, Ihre Mail ist etwas nach unten gerutscht. Das ist nicht meine Art, nicht zu antworten.
Zu Ihrer Frage:
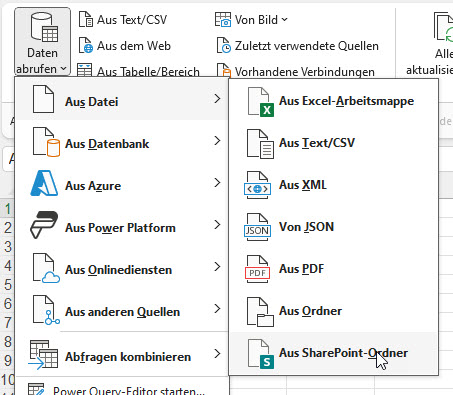
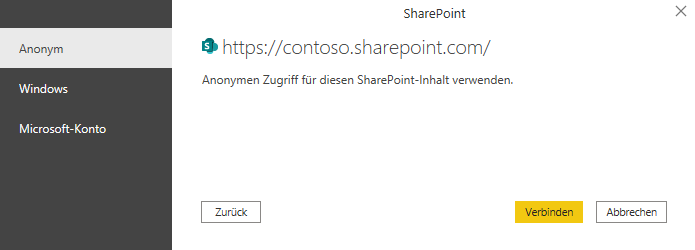
ja, wenn eine Excelmappe auf SharePoint liegt, gelten wohl andere Regeln für den Zugriff:
* entweder Sie greifen mit
SharePoint.Files
auf den Ordner zu:
* oder Sie verwenden den Befehl
SharePoint.Contents
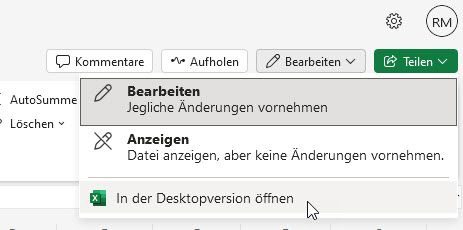
* oder Sie öffnen die Datei in der Desktop-Version:
Gestern war Excelstammtisch. Diana Sperber erzählte uns einige spannende Dinge über Power Query. Sehr interessant!
Beim Thema „Schutz“ musste ich schlucken.
Wenn man in Excel in Microsoft 365 eine Arbeitsmappe schützt, kann man zwar die Tabelle aktualisieren, aber nicht mehr den Code verändern und einsehen:
DOCH!
Man kann den Code kopieren und in einem Editor eingefügt anzeigen lassen:
Code einsehen geht – Code manipulieren natürlich nicht.
ich hatte am 15.05.204 mit viel Freude Ihren Kurs „Daten abrufen und vergleichen (Power-Query)“ besucht. Nun bastele ich gerade an einer PQ mit Web-Abruf und hätte folgende Rückfrage:
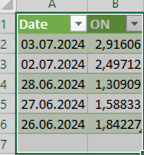
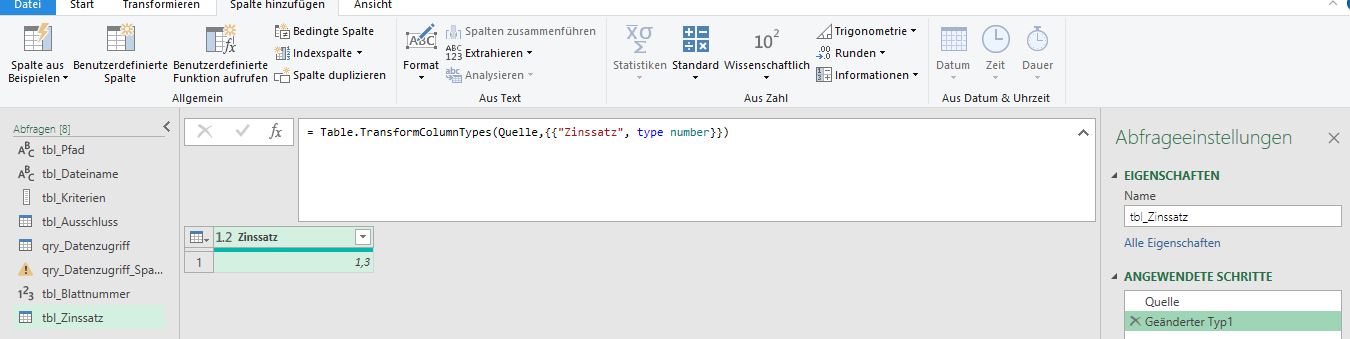
Ausgangslage: Auf einer Webseite werden stets aktuell für die letzten 5 Tage Zinssätze veröffentlicht. Wir möchten von einem der Zinssätze eine Zinssatzhistorie in Excel aufbauen.
Anbei mein PQ-File dazu, das jedoch tgl. nur Zinssätze für die letzten 5 Zinsstage anzeigt.
Wie kann ich die tgl. abgerufenen Zinsdaten historisieren?
Gestern wurden z.B. folgende Werte ausgegeben:
Gibt es einen Job-scheduler, der das PQ tgl. aktualisiert?
Über Ihre Expertise zu meinen Fragen würde ich mich sehr freuen 😊. Gerne können wir auch TEAMSen.
Beste Grüße
###
Hallo Frau S.,
die Antwort zur ersten Frage lautet: das geht mit Power Query nicht. Der Gedanke von PC ist es, die Daten zu aktualisieren.
Wenn Sie eine Historie erstellen möchten, müssen Sie die Daten per Power Automate oder VBA an eine andere Stelle schreiben. Oder per Hand kopieren / Inhalte einfügen – als Werte einfügen.
Ein Kollege von mir wollte mal Benzinpreise von Tankstellen vergleichen (Preise stehen im Internet), um dann einen Trend festzustellen – er hat die Daten mit VBA gespeichert.
In den Eigenschaften findet sich die Option „Aktualisieren beim Öffnen“:
Auch hier: wenn Sie die Datei jeden Tag aktualisiert haben möchten, müssen Sie mit Power Automate oder VBA (oder einer anderen Programmiersprache) die Aktualisierung erzwingen.
Wenn ich Power Query unterrichte, erzähle ich, dass es – anders als in Excel – keine Tastenkombinationen gibt, um Befehle aufzurufen. Ich werde diesen Satz in den nächsten Schulungen modifizieren. In den letzten Tagen bin ich im Internet über mehrere Listen von Shortcuts in Power Query gestolpert. Allerdings: einige der Tastenkombinationen funktionieren nur in der englischen Oberfläche – in der deutschen gibt es andere. Und: einige funktionieren in DAX-Editoren oder in Power Query in Power BI, aber nicht in Power Query in Excel. Ich habe hier einige der Tastenkombinationen für Power Query in Excel aufgelistet (und werde sicherlich weiter sammeln) und auf unserem Excelstammtisch im Juli vorstellen.
Viel Spaß damit, die Arbeit mit Power Query mit folgenden Kombis zu beschleunigen:
Wenn ich Power Query unterrichte, erzähle ich, dass es – anders als in Excel – keine Tastenkombinationen gibt, um Befehle aufzurufen. Ich werde diesen Satz in den nächsten Schulungen modifizieren. In den letzten Tagen bin ich im Internet über mehrere Listen von Shortcuts in Power Query gestolpert. Allerdings: einige der Tastenkombinationen funktionieren nur in der englischen Oberfläche – in der deutschen gibt es andere. Und: einige funktionieren in DAX-Editoren oder in Power Query in Power BI, aber nicht in Power Query in Excel. Ich habe hier einige der Tastenkombinationen für Power Query in Excel aufgelistet (und werde sicherlich weiter sammeln) und auf unserem Excelstammtisch im Juli vorstellen.
Viel Spaß damit, die Arbeit mit Power Query mit folgenden Kombis zu beschleunigen:
Power Query-Tipps & Tastenkombinationen
5.) Codeeingabe [Strg] + [entf] lösche ab Cursorposition bis Ende des Wortes [Alt] + [klick] Multicursor
6.) Bearbeitungsleiste Vor dem Schreiben der Klammer den Befehl/die Befehle markieren – Klammer „ummantelt“ vorhandenen Befehl
Wenn ich Power Query unterrichte, erzähle ich, dass es – anders als in Excel – keine Tastenkombinationen gibt, um Befehle aufzurufen. Ich werde diesen Satz in den nächsten Schulungen modifizieren. In den letzten Tagen bin ich im Internet über mehrere Listen von Shortcuts in Power Query gestolpert. Allerdings: einige der Tastenkombinationen funktionieren nur in der englischen Oberfläche – in der deutschen gibt es andere. Und: einige funktionieren in DAX-Editoren oder in Power Query in Power BI, aber nicht in Power Query in Excel. Ich habe hier einige der Tastenkombinationen für Power Query in Excel aufgelistet (und werde sicherlich weiter sammeln) und auf unserem Excelstammtisch im Juli vorstellen.
Viel Spaß damit, die Arbeit mit Power Query mit folgenden Kombis zu beschleunigen:
Wenn ich Power Query unterrichte, erzähle ich, dass es – anders als in Excel – keine Tastenkombinationen gibt, um Befehle aufzurufen. Ich werde diesen Satz in den nächsten Schulungen modifizieren. In den letzten Tagen bin ich im Internet über mehrere Listen von Shortcuts in Power Query gestolpert. Allerdings: einige der Tastenkombinationen funktionieren nur in der englischen Oberfläche – in der deutschen gibt es andere. Und: einige funktionieren in DAX-Editoren oder in Power Query in Power BI, aber nicht in Power Query in Excel. Ich habe hier einige der Tastenkombinationen für Power Query in Excel aufgelistet (und werde sicherlich weiter sammeln) und auf unserem Excelstammtisch im Juli vorstellen.
Viel Spaß damit, die Arbeit mit Power Query mit folgenden Kombis zu beschleunigen:
2.) Umgang mit Spalten im Editor [Strg] + [A] alle Spalten markieren Pos1/Ende wechsle zur ersten Spalte/letzten Spalte oder zum Anfang/Ende der Tabelle Pfeiltaste wenn Spalte markiert ist: weitere Spalten auswählen [Umschalt] + [Pfeiltaste] mehrere nebeneinander liegende Spalten auswählen [Strg] + [Pfeiltaste] / [Strg] + [Leertaste] mehrere nicht zusammenhängende Spalten markieren [Alt] + [Pfeil unten] Filter [Menütaste] Kontentmenü der Spalte erste Spalte / [Pfeil links] / [Enter] öffnet Kontextmenü der Tabelle [Leertaste] verschiebt den Bildschirm, ohne die Cursorposition zu verändern [Strg] + [Leertaste] wechselt zwischen Zelle markieren und Spalte markieren
Wenn ich Power Query unterrichte, erzähle ich, dass es – anders als in Excel – keine Tastenkombinationen gibt, um Befehle aufzurufen. Ich werde diesen Satz in den nächsten Schulungen modifizieren. In den letzten Tagen bin ich im Internet über mehrere Listen von Shortcuts in Power Query gestolpert. Allerdings: einige der Tastenkombinationen funktionieren nur in der englischen Oberfläche – in der deutschen gibt es andere. Und: einige funktionieren in DAX-Editoren oder in Power Query in Power BI, aber nicht in Power Query in Excel. Ich habe hier einige der Tastenkombinationen für Power Query in Excel aufgelistet (und werde sicherlich weiter sammeln) und auf unserem Excelstammtisch im Juli vorstellen.
Viel Spaß damit, die Arbeit mit Power Query mit folgenden Kombis zu beschleunigen:
Power Query-Tipps & Tastenkombinationen
1.) Editor allgemein [Alt] + [F12] Editor öffnen [Alt] + [F4] Editor beenden [F2] editieren/umbenennen: Abfrage, Spaltenüberschrift, Schritt [Tab] Zwischen den einzelnen Elementen wechseln
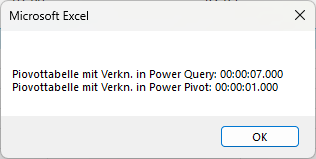
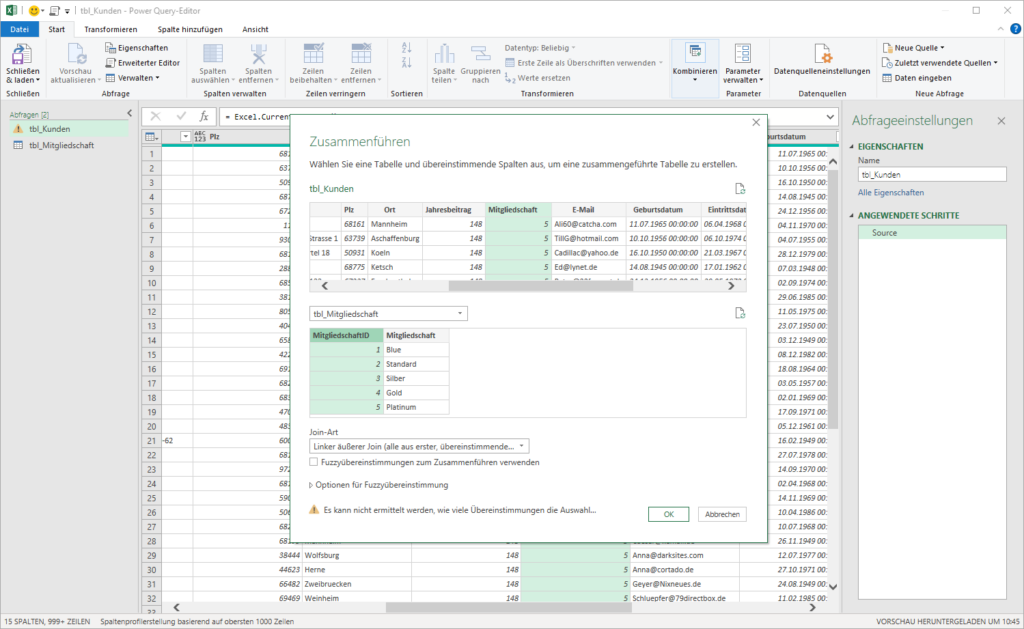
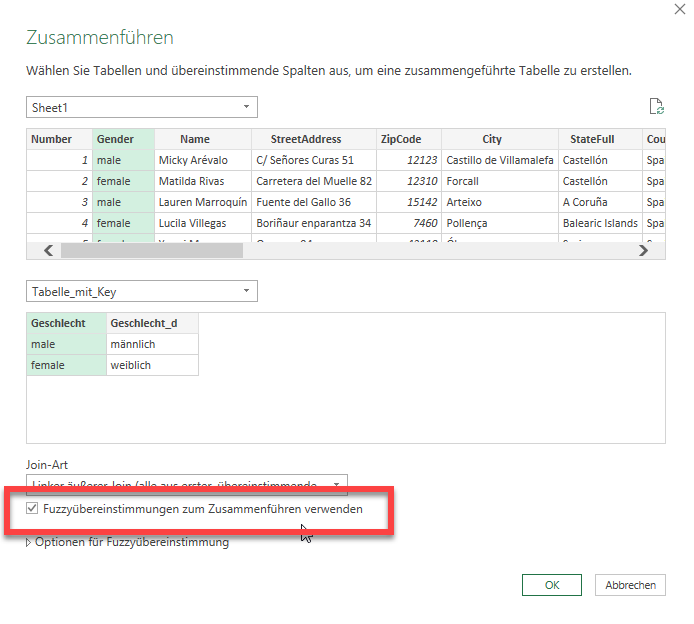
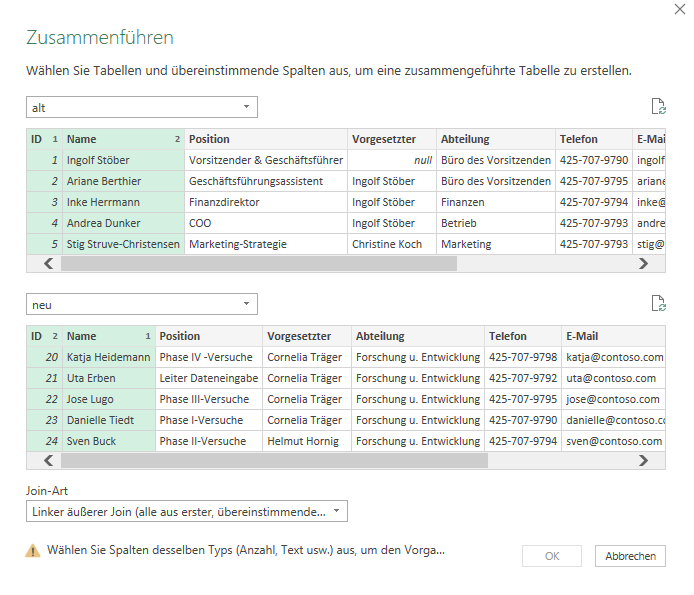
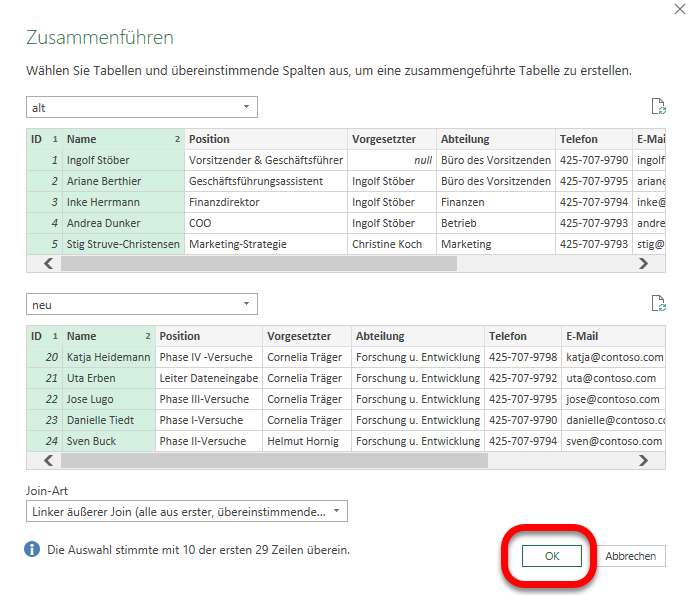
Ich hätte eine Frage, du bist der Power Query Experte, macht es einen Unterschied von der Performance ob ich eine Abfrage in PQ zusammenführe oder ob ich eine Beziehung in PP herstelle? LG
Hallo Christoph, die Frage kann ich SO nicht ganz beantworten. Wenn du in PQ verknüpfst, holst du eine Tabelle in eine andere Tabelle. Diese wird normalerweise extrahiert, um eine oder mehrere Spalteninformationen zu erhalten. Bei PP erstellst du lediglich eine Beziehung zwischen beiden Tabellen, welche keine Zeit in Anspruch nimmt. Jedoch: wenn du PP verwendest, lädst du die Daten ins Datenmodell – die Arbeitsmappe wird größer. Nur PQ muss man die Daten nicht ins Datenmodell laden. So bleibt die Datei kleiner. Wenn du beispielsweise mit einer Pivottabelle Informationen aus mehreren Tabellen holen willst, musst du mit PQ, wenn du das Datenmodell nicht verwenden willst, die Daten nach Excel laden. Beim Aktualisieren werden die Daten nach Excel geschrieben und die Spaltenbreite neu berechnet – DAS kostet Zeit. Pivottabelle auf Basis der Daten im Modell ist schneller. Ich habe letzteres mal getestet mit 300.000 Datensätze – hier das Ergebnis, das mit VB liefert. PP gewinnt gegenüber PQ, weil kein Schreiben in eine Tabelle nötig ist.
Wyn Hopkins ist genervt, dass der Zugriff auf SharePoint-Ordner mit Power Query so langsam dauert. Er schlägt vor, statt des Befehls SharePoint.Files den Befehl SharePoint.Contents zu verwenden.
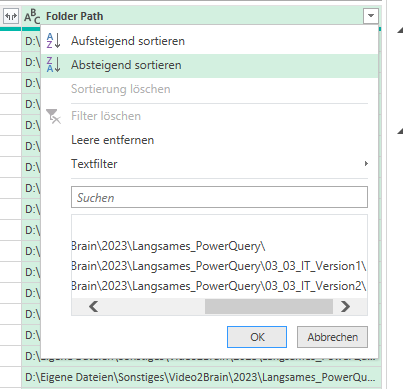
Wyn Hopkins ist genervt. Greift man in Excel mit Power Query auf einen Ordner zu, wird die letzte Spalte „Folder Path“ sehr schmal angezeigt. Man kann sie nicht verbreitern und sieht auch nicht den gesamten Pfad.
Er schlägt vor, diese Spalte nach links zu verschieben und dort zu verbreitern:
Löscht man diesen Schritt ist die Spalte „Folder Path“ breiter. Cleverer Tipp – danke Wyn.
Allerdings: Ich habe sie an einer Datei mit 300.000 Zeilen getestet und festgestellt, dass sie zirka 40% mehr Zeit benötigt als mehrere verschachtelte If-Funktionen …
Folgendes Problem: in einem Ordner befindet sich eine Datei.
Aus dieser Datei werden einige Spalten in einer anderen Datei benötigt. Dies kann prima mit Power Query umgesetzt werden.
Hinter dieser Datei werden weitere Informationen eingefügt:
Damit man die Originaldatei verändern kann, aber auch die in die Zieldatei neu eingetragenen Daten, geht man mit Power Query wie folgt vor:
Die intelligente Tabelle wird als zweite Abfrage in Power Query abgerufen:
Und mit der ersten Abfrage verknüpft:
Die eindeutige ID bildet hier die E-Mail-Adresse.
Die überflüssigen Spalten, die hier nun doppelt angezeigt werden, werden gelöscht
Klappt: die Originaldatei kann verändert werden (die Aktualisierungen werden in der Zieldatei angezeigt) und auch die Daten der neuen Spalten der Zieldatei können angepasst werden oder die Liste kann sortiert werden, ohne, dass die Aktualisierung etwas zerstört.
(danke an Hans-Peter Pfister für diesen Hinweis)
ABER:
Befinden sich die neuen Spalten INNERHALB der Datei, also beispielsweise so:
Wird nun diese intelligente Tabelle nach Power Query gezogen und dort mit der importierten Tabelle verknüpft:
Werden nach der Aktualisierung die Verknüpfungen zerstört:
Ich habe noch keinen Weg gefunden, dass die Zuordnungen korrekt bleiben – nach Sortieren und Ändern der Daten.
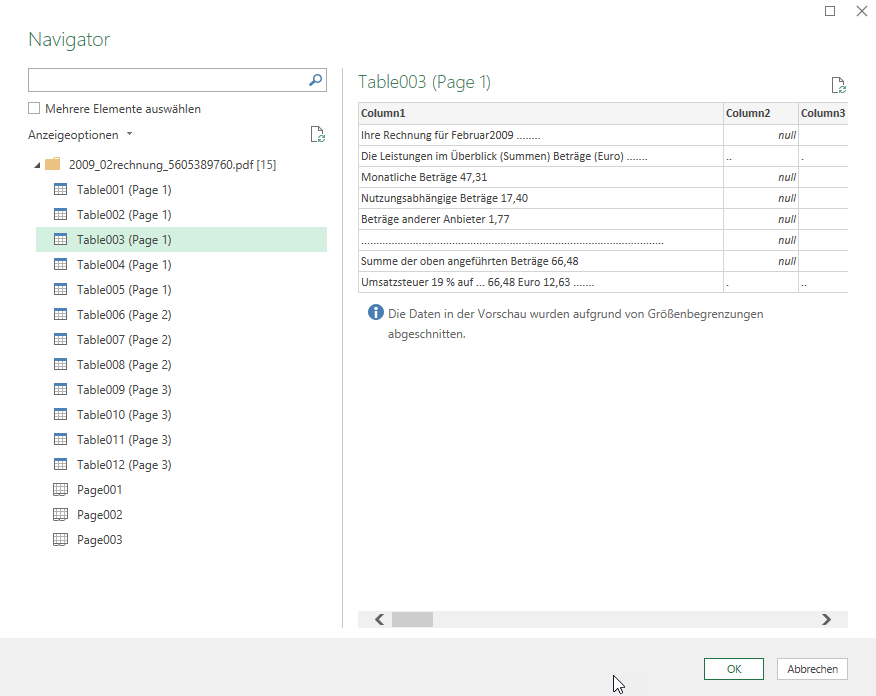
Ich kenne Power-Queri damit habe ich aber noch nie eine PDF hereingezogen. Geht denn das auch mit gescannten PDF’s? wie gesagt, es geht hier um das was die Kunden uns zu stellen. Und das ist wirklich sehr unterschiedlich.
Aber das schaue ich mir gerne an.
####
Hallo Herr S.,
1. Schauen Sie doch mal nach: Haben Sie in Excel Daten / Daten abrufen / aus Datei / Aus PDF?
Klicken Sie mal auf eine Rechnung? Bei meinen (alten) Telekom-Rechnungen hat es funktioniert. Vor Kurzem war ich in einer Firma – dort hatte auch jemand das Problem – Rechnungen als PDF … ging auch mit Power Query.
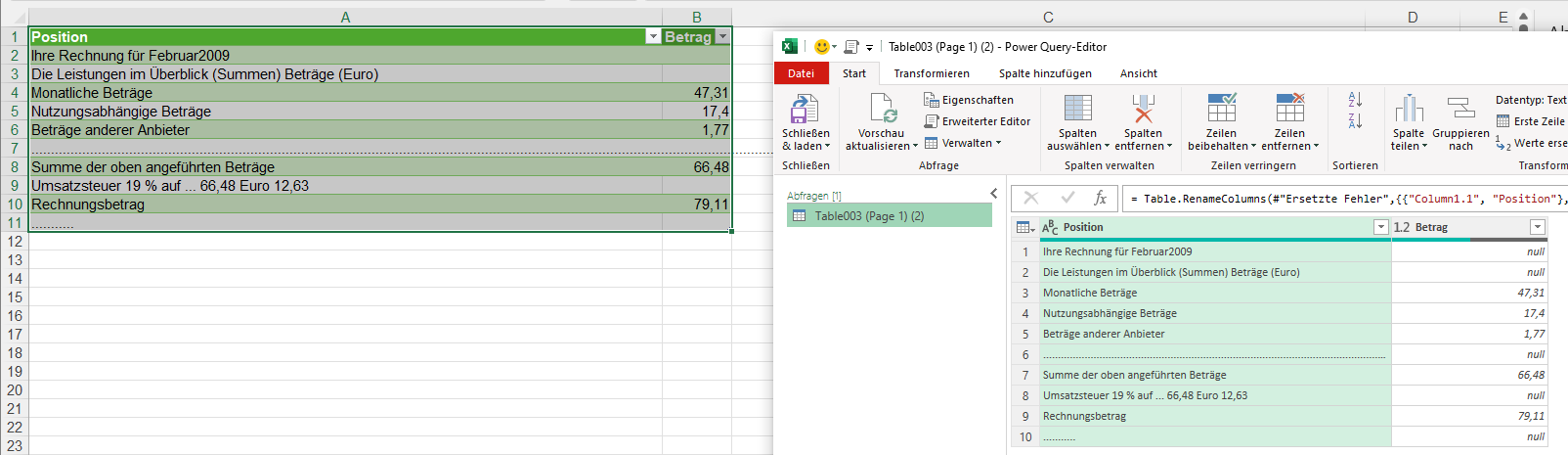
und dann muss ich (bei der Telekom) noch ein bisschen transformieren:
„Wir werden Änderungen an den Funktionen zum Abrufen und Transformieren von Daten (auch bekannt als Power Query) in Excel vornehmen.Anmerkung: Wenn Sie Power Query nicht verwenden, können Sie diese Meldung schließen.
Wann das passieren wird:
Ab dem 11. März 2024 werden wir wichtige Änderungen an den Funktionen zum Abrufen und Transformieren von Daten (auch bekannt als Power Query) in Excel einführen.
Wie wirkt sich das auf Ihre Organisation aus:
Jeder Benutzer, der versucht, Power Query nach dem 11. März 2024 zu verwenden und unter eines der folgenden Szenarien fällt, erhält eine entsprechende Fehlermeldung. Da wir die Benutzeroberfläche zum Abrufen und Transformieren von Daten (auch bekannt als Power Query) in Excel für Windows modernisieren, erfordern einige der Funktionen zum Abrufen und Transformieren von Daten Microsoft Edge WebView2 ( Microsoft Edge WebView2 | Microsoft Edge Developer), die auf dem Clientcomputer installiert werden soll. In Zukunft erfordern alle Funktionen zum Abrufen und Transformieren von Daten in Excel für Windows Microsoft Edge WebView2, daher empfehlen wir, diese Bibliothek jetzt zu installieren. Um unseren Kunden die beste Verschlüsselung ihrer Klasse zu bieten, planen wir außerdem, die Unterstützung von TLS (Transport Layer Security) 1.1 oder niedriger in Get & Transform Data (auch bekannt als Power Query) auf allen Plattformen einzustellen. Wenn eine bestimmte externe Datenquelle, mit der ein Benutzer eine Verbindung herzustellen versucht, nur TLS Version 1.1 oder niedriger unterstützt, kann er nicht über die Tools zum Abrufen und Transformieren von Daten in Excel auf die relevante Datenquelle zugreifen.
Was Sie tun müssen, um sich vorzubereiten:
Sie müssen: Installieren Sie das Microsoft Edge WebView2-Framework für bevorstehende Features zum Abrufen von Daten. Stellen Sie sicher, dass alle externen Datenquellen , die Sie mit Power Query verwenden, TLS Version 1.2 oder höher unterstützen – für Power Query im Allgemeinen.Bitte informieren Sie Ihren Helpdesk und aktualisieren Sie die Dokumentation entsprechend.Weitere Informationen finden Sie unter:Informationen zum Abrufen und Transformieren (Power Query) in ExcelVorbereiten von TLS 1.2 in Office 365 und Office 365 GCC | Microsoft Learn Aktivieren von Transport Layer Security (TLS) 1.2 auf Clients – Configuration Manager | Microsoft Learn
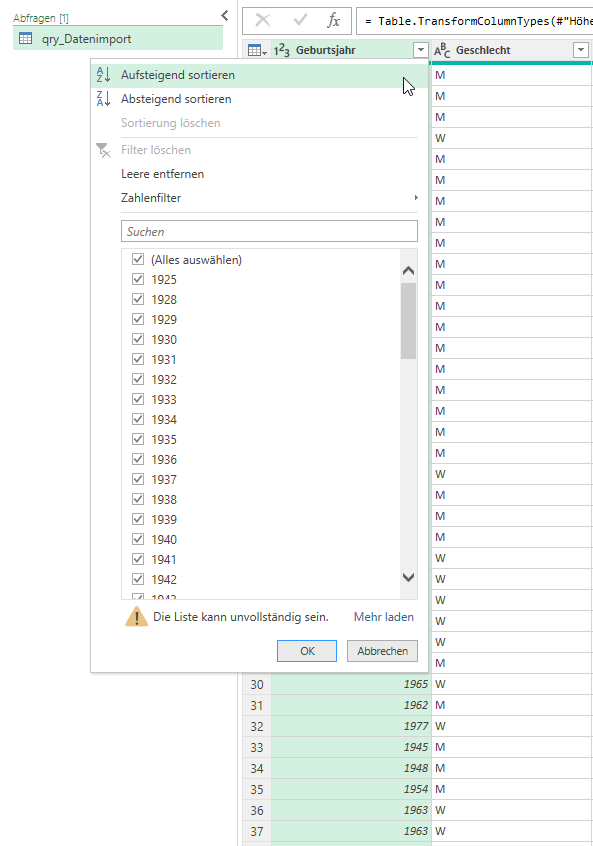
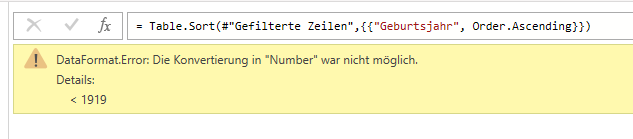
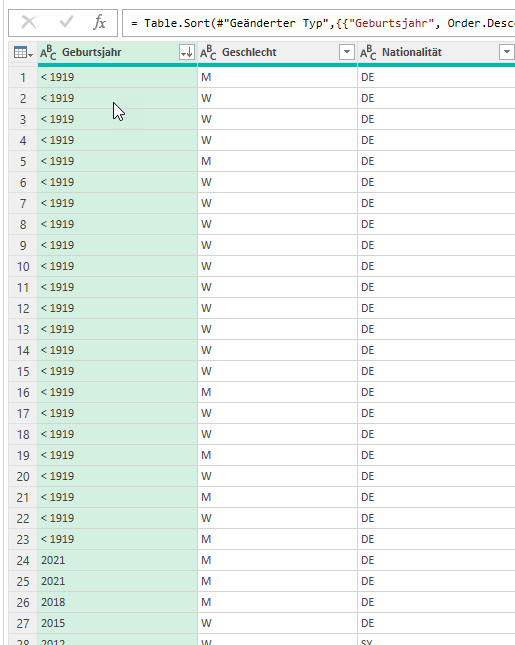
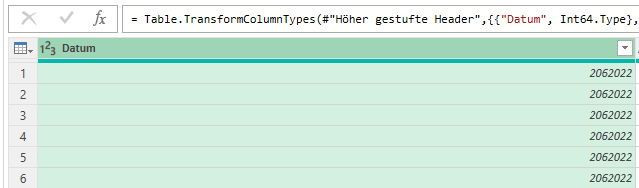
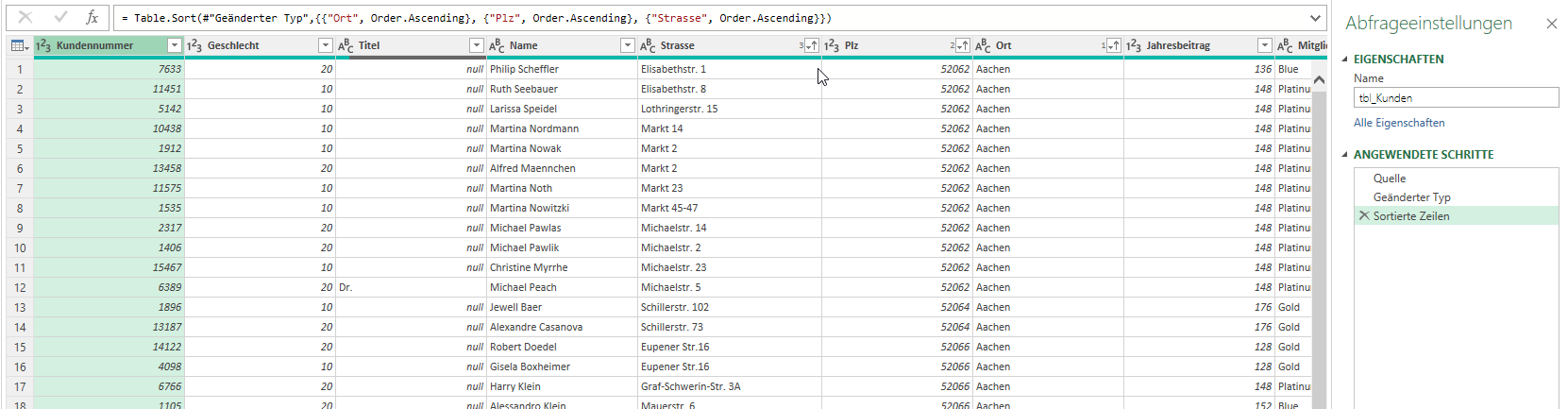
Es fällt mir ein: in der Liste befinden sich mehr als 140.000 Datensätze – einige enthalten die Information „< 1919“. Da nur die ersten 1.000 Zeilen ausgewertet werden, ist dieser Fehler nicht in Power Query sichtbar.
Das heißt: der Datentyp der Spalte muss korrekt in Text verwandelt werden
Dann funktioniert die Sortierung:
Frage: Wer macht denn so etwas? – Zahlen und Texte in einer Spalte mischen? Seltsames Datenbanksystem, das hier verwendet wurde …
Bekomme beim Aktualisieren der Abfragen (255 angefügte Abfragen)
in Power Query immer den Hinweis ‚unerwarteter Fehler‘ zu lesen.
Die 255 Abfragen habe ich mir vom Internet nur als Verbindung heruntergeladen. Nach mehreren Versuchen wird die Abfrage doch aktualisiert.
Hallo Peter,
verstehe ich dich richtig: du kommst über den Fehler drüber, aber er nervt dich?
Du hast mehr als 220 Abfragen, die ALLE auf diese Internetseite zugreifen. Und alle liegen in einer Datei!
Frage: Gibt es keine Datenbank, die man direkt anzapfen kann? Ich habe mir die Seite angesehen – die Ergebnisse stehen wirklich auf jeder einzelnen Seite. Ich vermute, dass sie im Hintergrund per Programmierung (PHP?) erzeugt werden.
Ich habe mehrmals über das Thema «langsames Power Query» referiert – ich denke, Power Query schafft es nicht so schnell ALLE Abfragen zu aktualisieren und «verheddert» sich.
Ich fürchte die viele, viele Mühe, die du dir gemacht hast, führt zu dieser Fehlermeldung:
Benötigst du alle Abfragen?
Ich habe übrigens festgestellt, dass zu viele Abfragen – vor allem Abfrage auf Abfrage auf Abfrage auf … Power Query in die Knie zwingen. Lieber flach halten!
Hilft das?
Hallo Renè,
vielen, vielen Dank.
Ja, deine Information hat mir geholfen.
Bin zufrieden, dass der Fehler nicht bei mir liegt.
Dass Power Query viel Zeit benötigt um alle Abfragen zu aktualisiern
ist klar.
Nicht bedacht habe ich, dass es sich dabei ‚verheddern‘ könnte.
Alle Abfragen benötige ich.
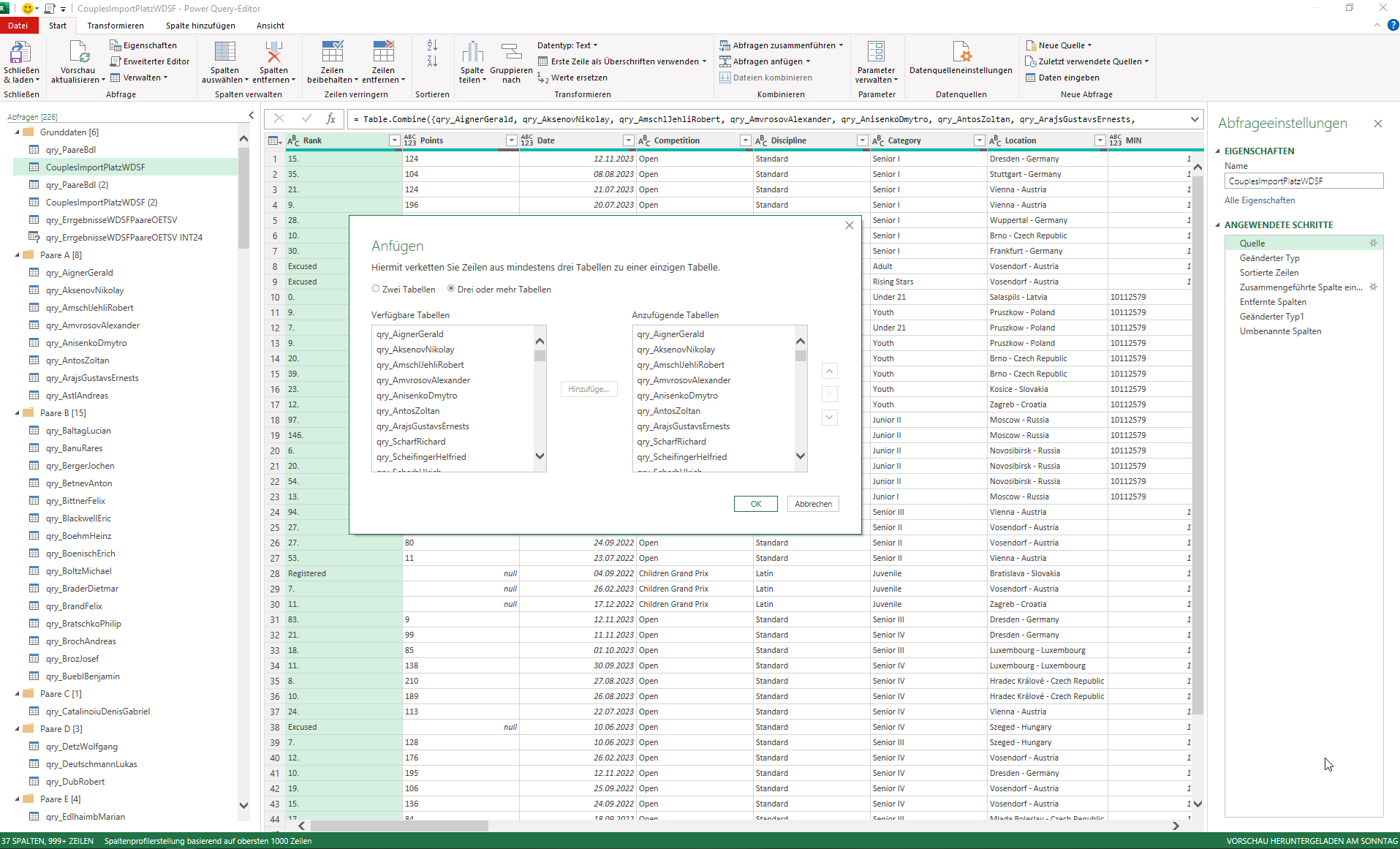
Es gibt bedauerlicherweise viele Paare, die sich an die Verpflichtung
das Ergebnis innerhalb von drei Tagen zu melden, nicht halten.
Der Verband bönigt die Infdormationen der Platzierungen für die
Entscheidung bei Entsendungen zu Turnieren.
Anderer Ansatz.
Eine Tabelle für jedes Paar hatte ich mir schon überlegt, aber verworfen
da ich dachte, dass das mehr Zeit benötigt.
Erstelle nun Abfragen für jedes Paar einzeln.
Frage beim Verband nach, ob sie eine Abfragemöglichkeit bei WDSF
bekommen, bei der die gesamten Ergebnisse abzufragen sind.
Davon sprechen sie bei jedem Meeting seit Jahren. :-(((
Auf einem Tabellenblatt befindet sich eine Liste. Sie soll an anderer Stelle mit PowerQuery wieder angezeigt – das heißt: per Power Query verknüpft werden. Das heißt: die Liste liegt nicht als intelligente Tabelle vor und soll auch nicht in eine (intelligente) Tabelle konvertiert werden.
Also greife ich mit Power Query auf die gleiche Datei zu und hole die Daten, die transformiert werden:
Ich teste und ändere eine Information. Das Aktualisieren funktioniert allerdings nicht!?!
Klar! Ich muss die Datei vor der Aktualisierung speichern!
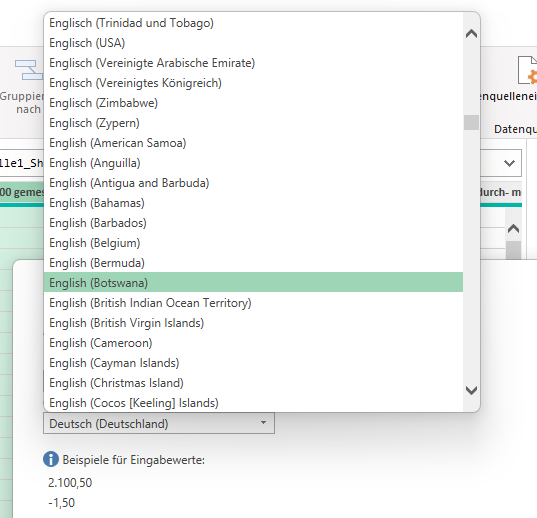
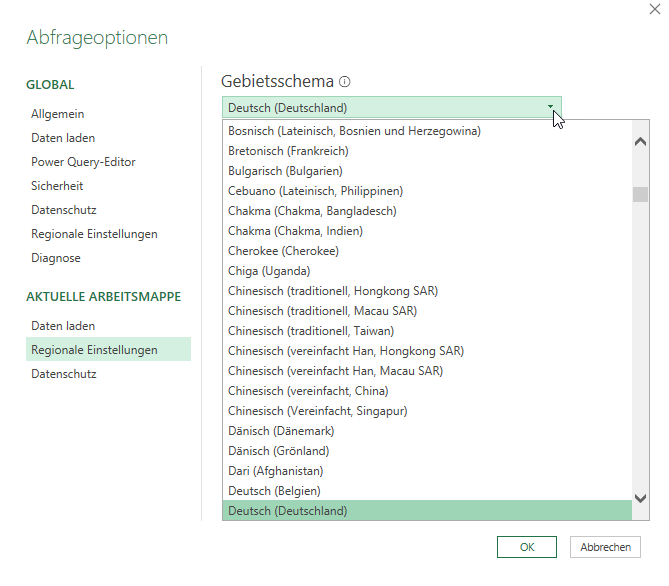
Erstaunlich: Manchmal – nicht immer – stehen die „englischen“ Länder zwei Mal untereinander im Gebietsschema bei Power Query. Nach Zypern beginnt die Liste neu mit American Samoa. Das wäre nicht so schlimm – jedoch: Englisch (USA) steht nur einmal in der Liste – im oberen Teil. Ich weiß nicht, wann das passiert und wie man das wegbekommt …
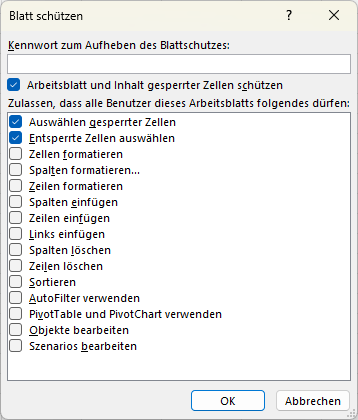
wenn du bei deinen Kunden eine Excel-Datei im Einsatz hast, die dann mit PowerQuery ausgestattet ist, wie lege ich die Schutzoptionen im Dialog fest, dass bei geschütztem Blatt die Option
Ich habe in einer Datei 46 Abfragen programmiert. Wenn ich die Abfragen manuell einzeln aktualisiere funktioniert das einwandfrei.
Wenn ich aber alle Daten aktualisieren lasse, dann stürzt mein Excel aufgrund zu wenig Ram ab.
Gibt es eventuell Einstellungen die ich ändern muss um Ram zu sparen?
Ich nutze aktuell eine 32 Bit Version von Excel. Laut unserer IT könnte ich eine 64 Bit Version bekommen. Liegt es eventuell daran?
Problem ist nur, dass später andere Personen die Datei nutzen sollen die unter Umständen keine 64 Bit Version nutzen.
Vielen Dank
####
Ich schaue es mir an: in verschiedenen Ordnern liegen Excelmappen:
Davon wird jeweils die neuste Datei verwendet, was man mit Sortieren und Zeilen beibehalten leicht erreichen kann.
Aus dieser Datei werden bestimmte Informationen (Datum, Status) ausgelesen:
Für eine Datei gibt es zwei (!) Abfragen, deren Tabellen nebeneinander stehen. Also jeweils: eine Zeile Überschrift und eine Zeile Inhalt:
Und tatsächlich: Bei Aktualisierung der Abfragen stürzt Excel auf einer 32-Bit-Maschine ab:
Die Lösung: Wir versuchen es. Wir erstellen EINE Abfrage, welche auf den übergeordneten Ordner zugreift, dort die Dateien der untergeordneten Ordner ausliest und mit geschickten Transformationen erhalten wir das Ergebnis in einer Tabelle. Diese lässt sich problemlos aktualisieren.
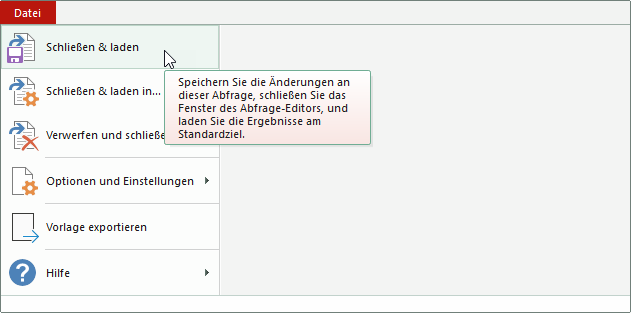
Was macht denn der? Plötzlich sind ganz viele Tabellen nach Schließen von Power Query in der Excelmappe.
Die Antwort: Er klickt im Power Query-Editor auf Datei / Schließen (wie auch in den anderen Office-Programmen).
Und so verwendet Power Query die Grundeinstellung, die man über die Abfrageoptionen ändern kann:
Ich erkläre ihm den Unterschied zwischen „Schließen und Laden“ und „Schließen und Laden in“ und empfehle ihm IMMER die letzte der beiden Varianten zu verwenden.
Manchmal sind einfache Fragen verblüffenderweise gar nicht einfach..
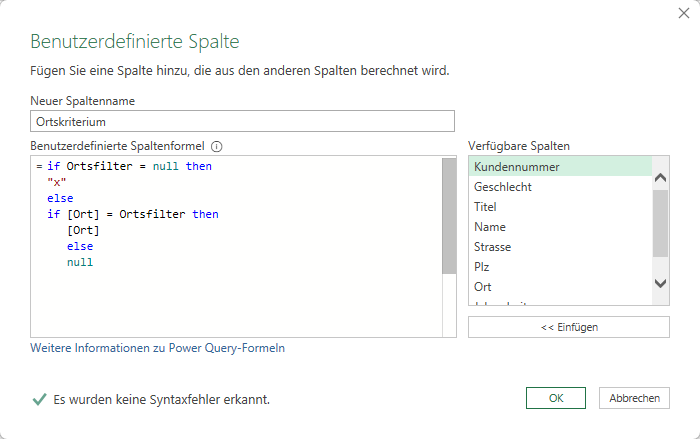
Ich zeige in der Power Query-Schulung, wie man in Excel einer Zelle einen Namen geben kann und diesen als Parameter für die Filterung einer Liste verwenden kann:
Dann kommt die Frage, wie man alle Daten sehen kann, wenn das FIlterkriterium leer ist:
Da Power Query kein If-Statement kennt, um Befehle bedingt auszuführen, also IF nicht in der Abfolge der M-Befehle kennt, sondern nur als Funktion, muss man sich mit einem Trick behelfen. Beispielsweise mit einer Funktion;
=if Ortsfilter = null then
"x"
else
if [Ort] = Ortsfilter then
[Ort]
else
null
Eine Abfrage wird mit Power Query auf Basis einer anderen Datei erstellt. Man kann in den Optionen einstellen, dass sie beim Öffnen der Datei aktualisiert wird.
Auf Basis dieser Tabelle wird eine Pivottabelle erstellt. Auch dort wird festgelegt, dass sie bei Öffnen aktualisiert wird:
Allerdings ist die Reihenfolge wichtig: zuerst muss die Abfrage aktualisiert werden und anschließend die Pivottabelle. Das ist so nicht gegeben.
Die Lösung: man muss mit dem Datenmodell arbeiten. Verwendet die Pivottabelle das Datenmodell, wird korrekt aktualisiert.
Der Auftrag hörte sich einfach an: Der Kunde wollte ein Add-In, welches alle Dateien aus allen Unterordnern vom firmeneigenen Sharepoint herunterlädt und in bestimmten Zellen Werte einfügt.
Der Knackpunkt war: Sharepoint!
Ich habe lange getüftelt, wie ich „auf den Sharepoint komme“, wie ich die Ordner und Unterordner und die dort befindlichen Dateien auslesen könne. Und herunterladen und bearbeiten.
Irgendwann kam mir die Idee: nicht mit VBA und DIR oder den FileScription-Objekt auf den Ordner losgehen, sondern mit Power Query! Damit kann man leicht alle Dateien aller Unterordner auslesen und auflisten. Der Befehl
SharePoint.Files
macht es möglich. Dieses Power Query-Skript kann leicht mit VBA aufgerufen werden (der Makrorekorder zeigt, wie das funktioniert:
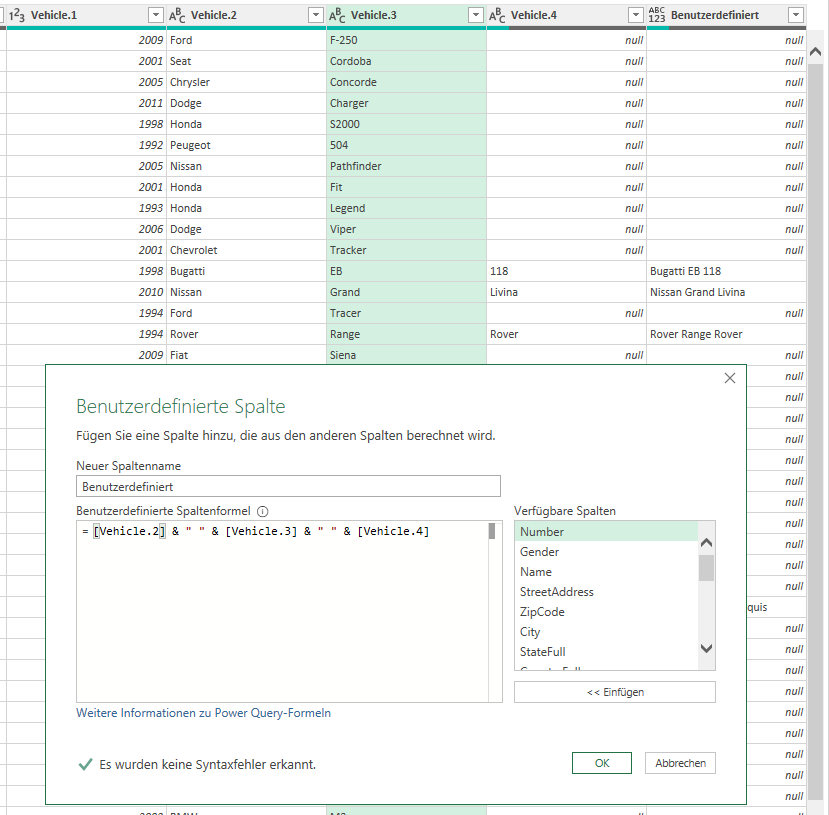
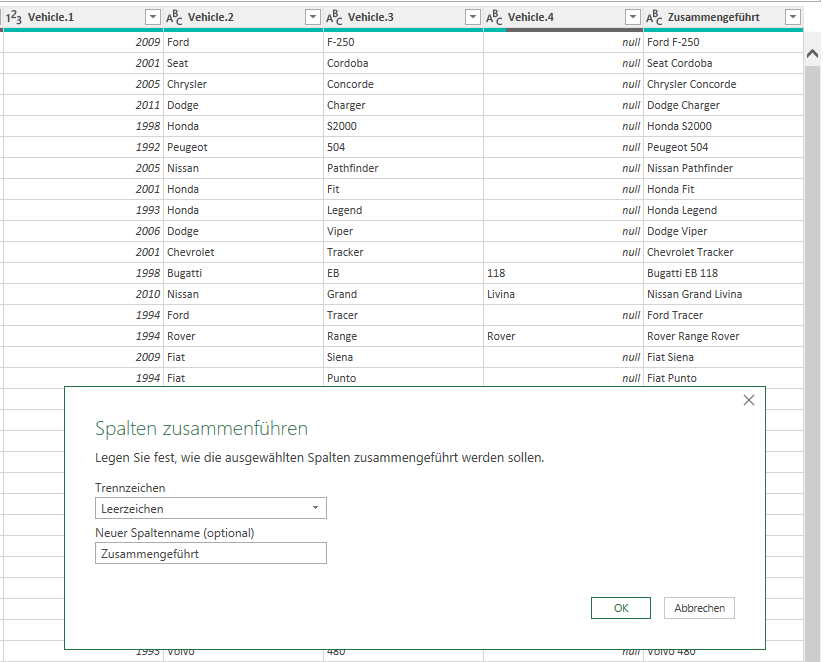
Werden in PowerQuery Spalten mit einem Verkettungsoperator „&“ zusammengefügt und befindet sich in einer der Zellen der Wert null, dann ergibt Inhalt & null -> null:
Nur wenn alle Zellen mit Text gefüllt waren, wird das Ergebnis angezeigt.
Anders dagegen der Assistent „Spalten zusammenführen“.
Amüsant, was manchen Teilnehmerinnen und Teilnehmern in Schulungen auffällt. Dinge, die ich noch nie beachtet habe oder denen ich keine Beachtung beigemessen habe.
Beispielsweise ist mir noch nie aufgefallen, dass Zahlen in PowerQuery kursiv stehen, während Texte immer „aufrecht“, also nicht kursiv im Editor dargestellt werden:
Katharina hat auf eine Differenz zwischen scheinbar gleichen, aber auf unterschiedlichen Rechner installierte Excel 2016-Version aufmerksam gemacht. Power Query hat bei der Abfrage auf einen Ordner nicht nachvollziehbare Fehlermeldungen:
Das Dialogfeld beim Zugriff auf Ordner wird gar nicht angezeigt.
Mark hat uns für eine mögliche Lösung den folgenden Link genannt:
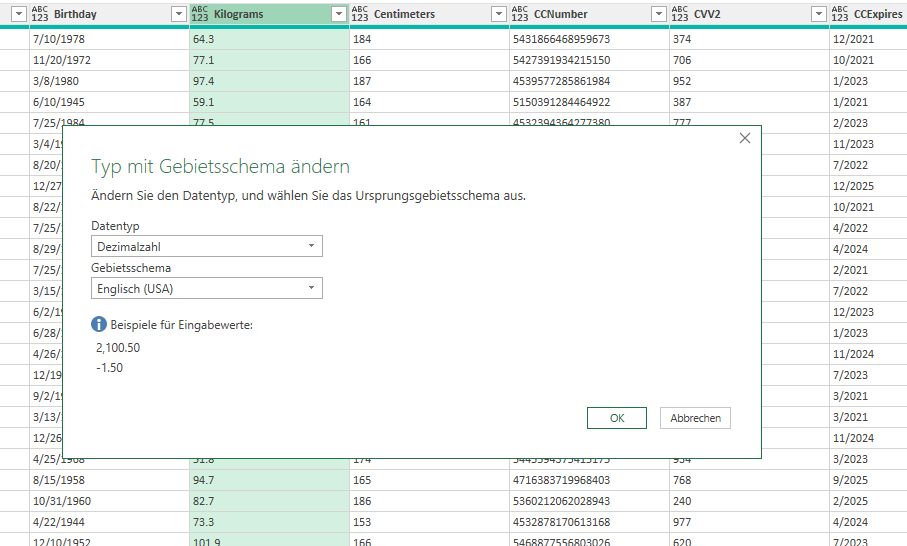
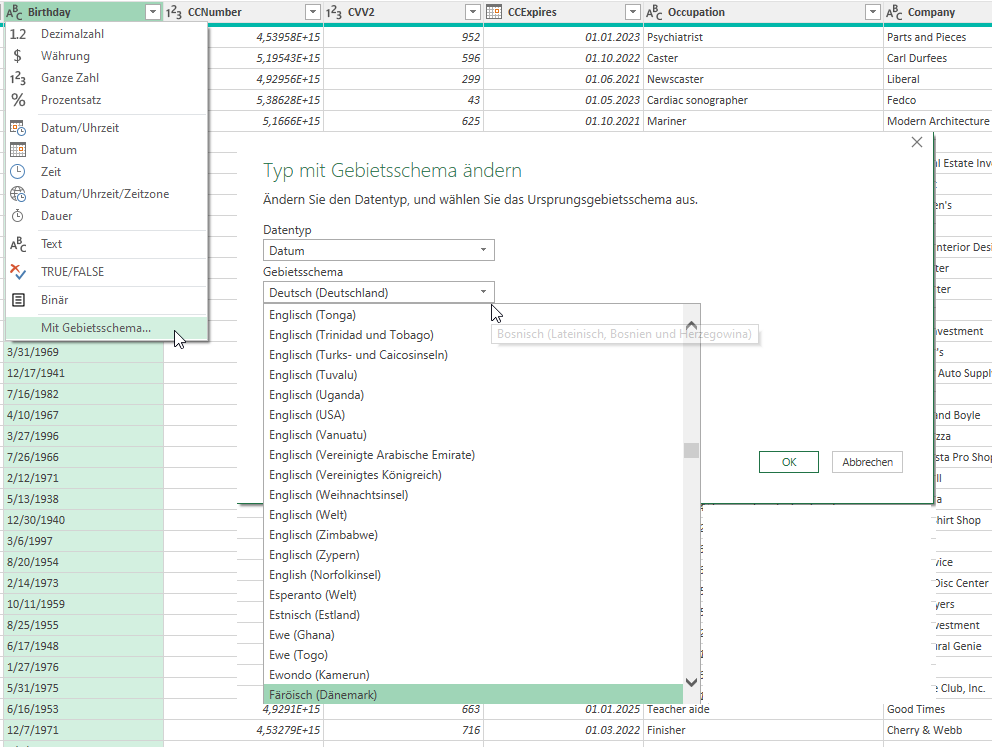
Ich unterrichte PowerQuery in einer internationalen Firma. Einige haben die englische Oberfläche eingestellt und damit auch das Dezimaltrennzeichen „.“ und die Datumsschreibweise „MM/TT/JJJJ“, einige Teilnehmer und Teilnehmerinnen „sprechen“ deutschen, also das Komma als Dezimaltrennzeichen und Datum in der Form „TT.MM.JJJJ“.
Beim Festlegen des Datentyps müssen nun einige auf „Dezimalzahl“ klicken, andere das Gebietsschema festlegen. Da ich verschiedene Übungsbeispiele mitgebracht habe, muss man entweder die eine oder andere Variante wählen:
Ich überlege: Wenn nun eine solche Datei mit einem PowerQuery-Zugriff ausgetauscht wird, wäre es doch sinnvoll IMMER das Gebietsschema der Quelle festzulegen, da es ansonsten zu Fehlern kommen kann:
VBA-Schulung. Ein Teilnehmer wollte JSON-Datein in Excel haben. Kein Problem, sagte ich und zeigte ihm PowerQuery.
Allerdings – nach einigen fragenden Blicken – stellten wir fest, dass in seinem Excel 2016 (anders als meines in Microsoft 365) noch kein JSON-Zugriff vorhanden ist.- Ärgerlich!
Mit PowerQuery wurde eine Abfrage erstellt. Diese enthält eine Liste. Wie kann man eine Dropdownliste mit einer Datenüberprüfung auf diese Liste erstellen, ohne dass die Daten nach Excel geladen werden?
Etwas irritiert bin ich schon. In einer PowerBI-Schulung erzählt mir ein Teilnehmer, dass er die Daten gerne in Excel hätte. Und dass er eigentlich gerne mit PowerQuery in Excel darauf zugreifen würde. Und nicht mit PowerBI. Aber die IT hätte ihm gesagt, dass es nicht gut ist, wenn mit PowerQuery so viele Abfragen auf die Datenbank abgesetzt werden. Besser wäre es, mit PowerBI auf die Datenbank zuzugreifen.
Ich bin mir nicht sicher, ob die Damen und Herren von der IT nicht wissen, dass PowerBI auch PowerQuery verwendet.
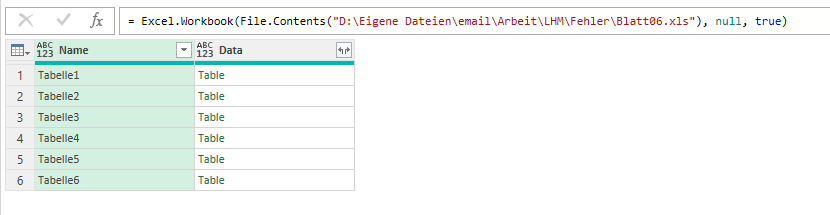
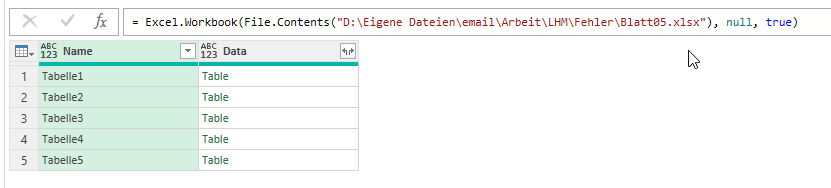
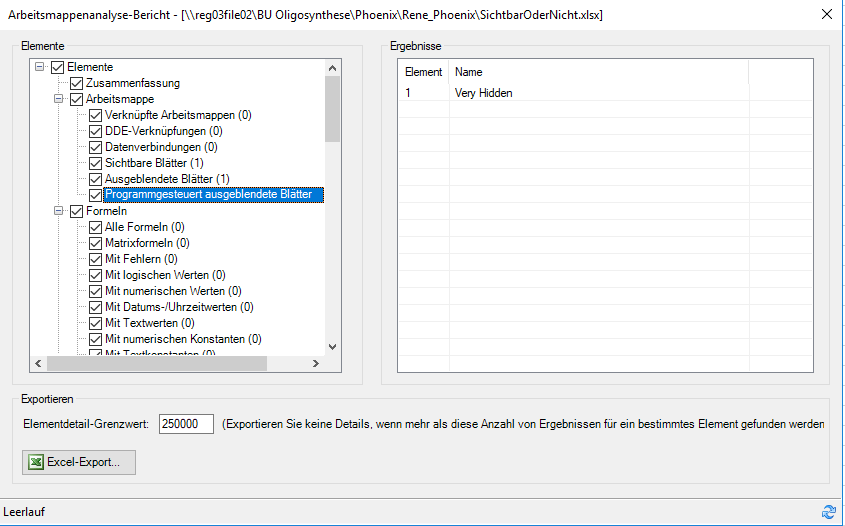
Wenn man mit PowerQuery auf eine „ältere“ XLS-Excelmappe zugreift, werden folgende Spalten angezeigt:
Beim aktuellen Dateiformat XLSX dagegen drei weitere:
Die drei Spalten (mit ihren Informationen) Item, Kind und Hidden fehlen.
Würde man eine XLS-Datei in XLSX umbenennen, wäre das Ergebnis das Gleiche wie bei XLS:
Wer macht denn so etwas? Und: DAS würde man in Excel doch sofort bemerken.
Ich erhalte vorgestern die Frage, warum das PowerQuery-Tool, das ich für die Firma erstellt habe bei einer Datei nicht läuft. Ich stelle fest – obwohl die Datei vom Format XLSX ist, werden nur die beiden Spalte Name und Date angezeigt, nicht jedoch Item, Kind und Hidden. Warum?
Ich gehe auf die Suche.
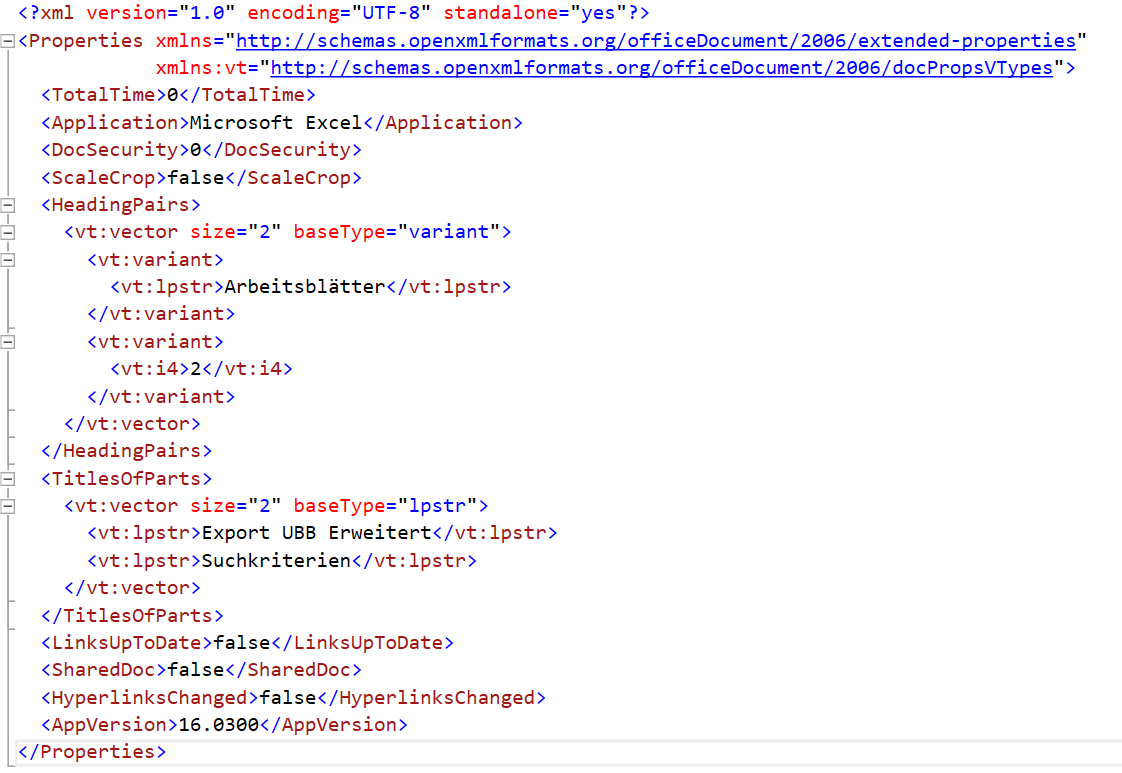
Ich stelle fest, dass die im openXML-Format verwendete interne Datei app.xml (im Ordner docProps) folgendermaßen aussieht:
Wenn ich die Datei, die von Apache POI erstellt wurde, öffne, speichere und schließe, sieht diese XML-Datei so aus:
SO jetzt jede XLSX-Datei aus, die von Excel erzeugt und in Excel gespeichert wurde.
Das bedeutet: das (umstrittene) Werkzeug Apache POI produziert XLSX-Dateien, die nicht genau der Spezifikation von Microsoft entsprechen. Ist das schlimm?
Ja, weil mein Werkzeug auf die Spalte „Kind“ zugreift und diese nicht findet …
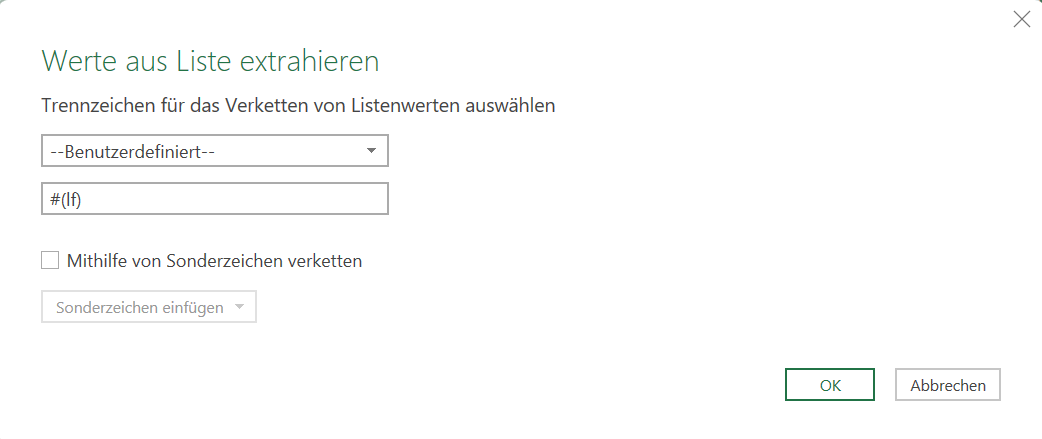
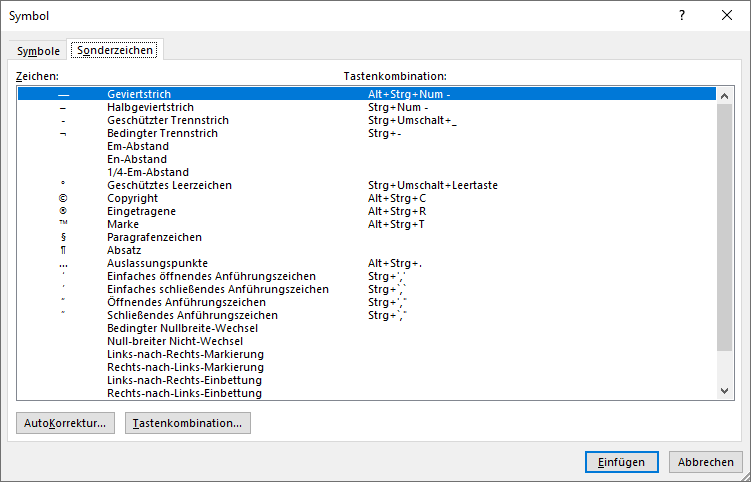
In Excel erstellt man einen Zeilenumbruch in einer Zelle mit der Tastenkombination [ALT] + [Enter]. Der dahinterliegende Code hat die Nummer 10. Importiert man eine Liste mit Zellen mit Zeilenumbrüchen nach PowerQuery, sieht man schnell, dass #(lf), also Linefeed diesem Zeichen entspricht.
Aha, denke ich mir: es wäre doch schön, wenn eine Liste nicht mit Semikola getrennt wären:
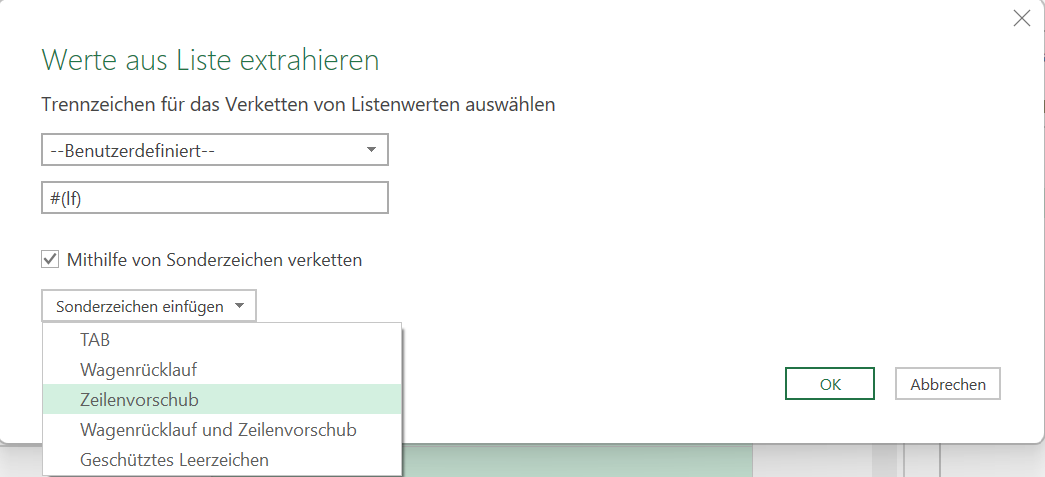
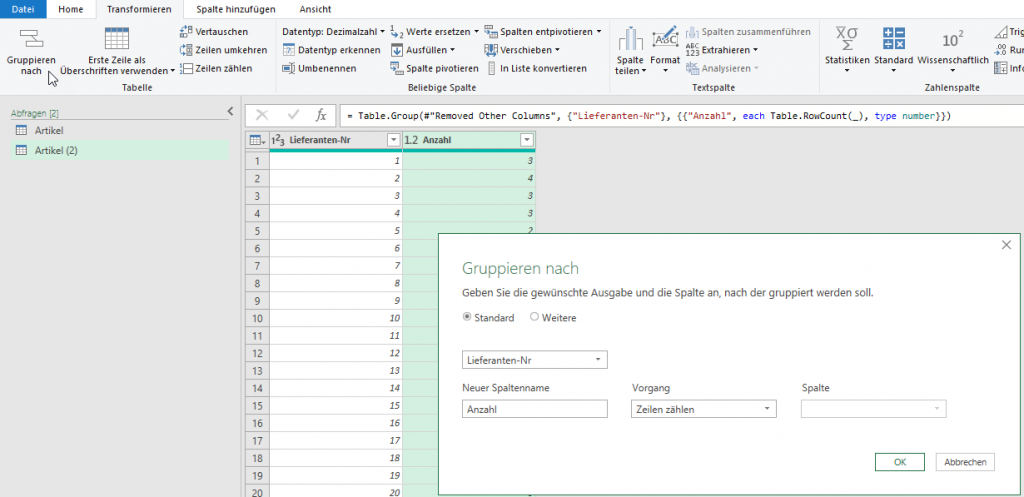
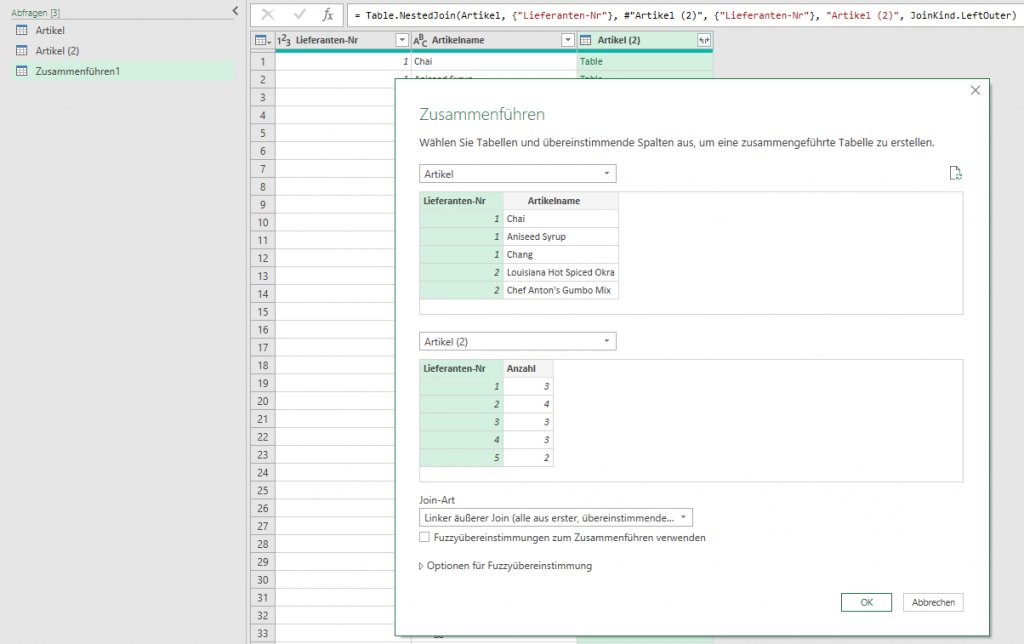
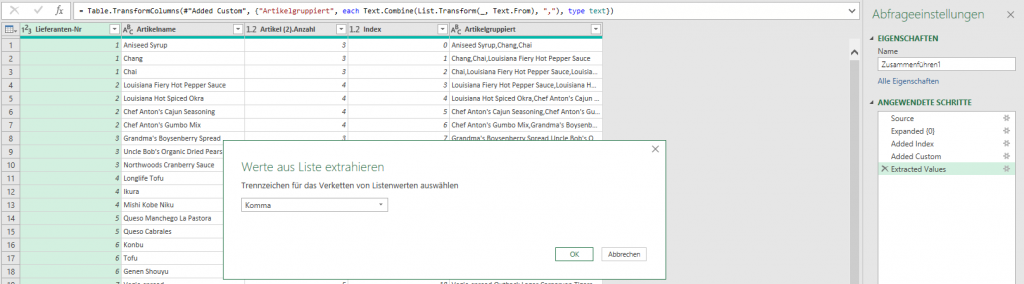
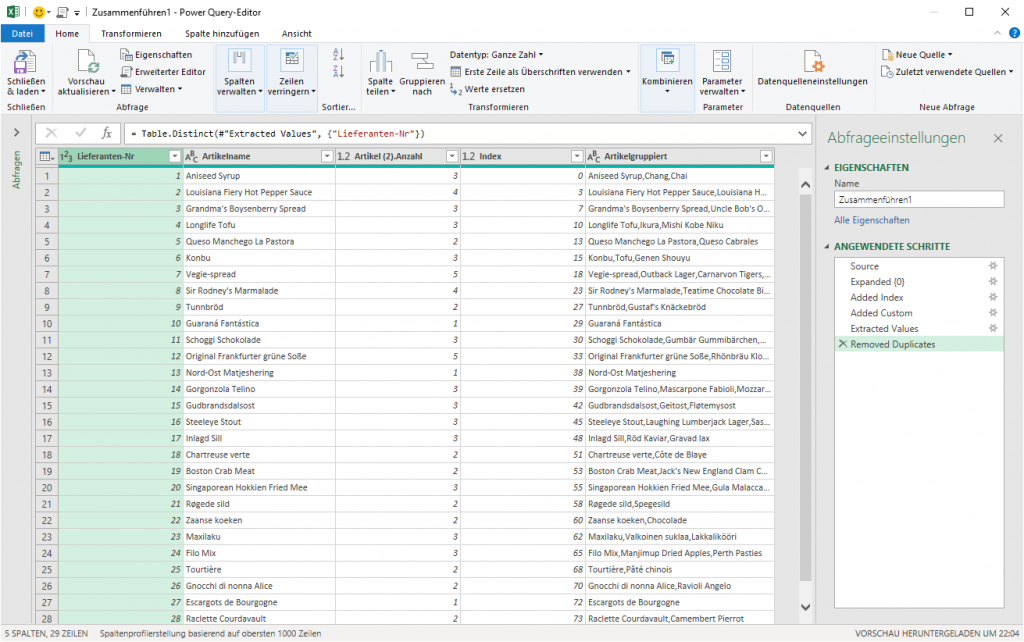
Ich öffne den Dialog und trage statt Semikolon in der Kategorie „benutzerderfiniert“ #(lf) ein;
Das Ergebnis irritiert:
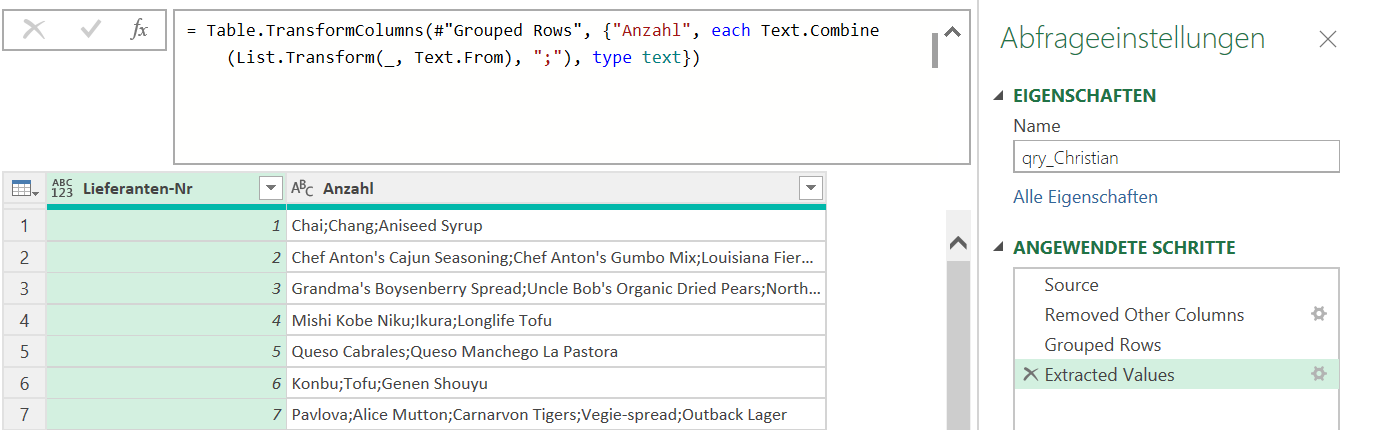
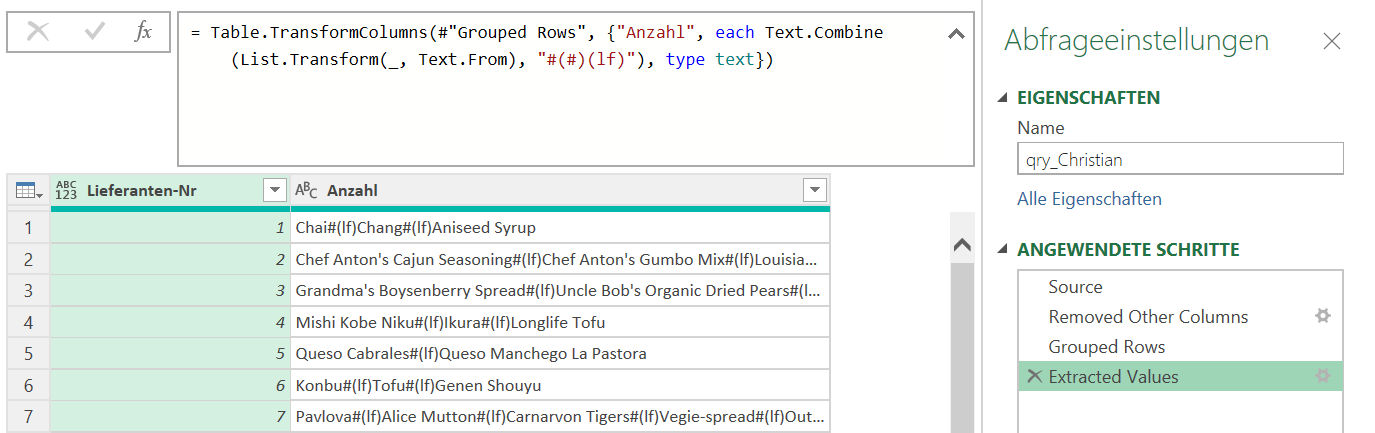
PowerQuery hat den Code geändert in:
= Table.TransformColumns(#"Grouped Rows", {"Anzahl", each Text.Combine(List.Transform(_, Text.From), "#(#)(lf)"), type text})
Natürlich könnte man es per Hand ändern in „#(lf)“
Oder durch die Funktion
Character.FromNumber(10)
ersetzen:
= Table.TransformColumns(#"Grouped Rows", {"Anzahl", each Text.Combine(List.Transform(_, Text.From), Character.FromNumber(10)), type text})
Schließlich entdecke ich, dass in der Kategorie „benutzerdefiniert“, dass man die Texte „mithilfe von Sonderzeichen verketten“ kann. Und dort findet sich auch der Zeilenvorschub. Und dieses #(lf) wird von PowerQuery auch nicht geändert.
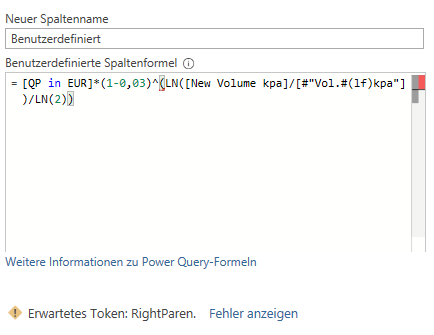
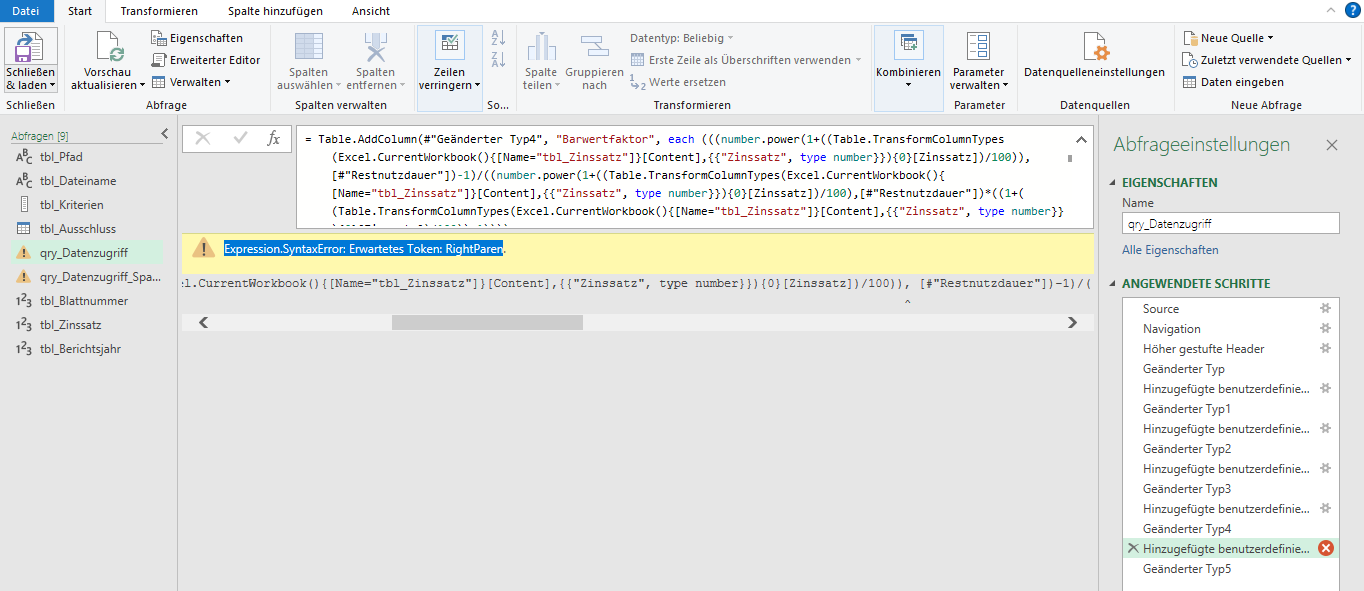
ich habe die Formel so angepasst, dass auf die richtigen Werte zugegriffen wird (d.h. es wird der Zinssatz verwendet, der als Drilldown-Liste angelegt wurde, s.u.). Leider kommt immer wieder eine Fehlermeldung, die ich nicht lösen konnte, auch nicht durch eine Internetrecherche. Den Code habe ich mit Notepade++ zusammengebaut und Ihnen angehängt. Das ist der Fehler (beim Komma):
Hallo Frau I.,
1. PowerQuery unterschiedet zwischen Groß- und Kleinschreibung.
Der Befehl lautet
Number.Power
(groß „N“, groß „P“)
2. Stimmt – ist mir später aufgefallen – ich habe die zweite Formel (P) vergessen. Und: NEIN: es gibt keine Barwert- oder andere finanzmathematische Funktion in PowerQuery
Liebe Grüße
Rene Martin
Nachtrag:
so könnte die Lösung aussehen:
Starten Sie den PowerQuery-Abfrageeditor.
Klicken Sie auf die Funktion fnBarwert.
Klicken Sie auf Ansicht / Erweiterter Editor.
Dort sehen Sie die Berechnung:
let
Barwert = (Zins as number, Restnutzdauer as number) as number =>
let
q = 1 + Zins / 100,
Ergebnis = (Number.Power(q , Restnutzdauer) - 1) / (Number.Power(q , Restnutzdauer) * (q-1))
in
Ergebnis
in Barwert
Ist der Zins bei Ihnen eine Zahl oder eine Prozentzahl – also 3 oder 3%? Ist die Restnutzungsdauer in Jahren oder Monaten?
Tragen Sie einfach die entsprechenden Zahlen links ein – rechts wird der Barwert berechnet. Korrekt?
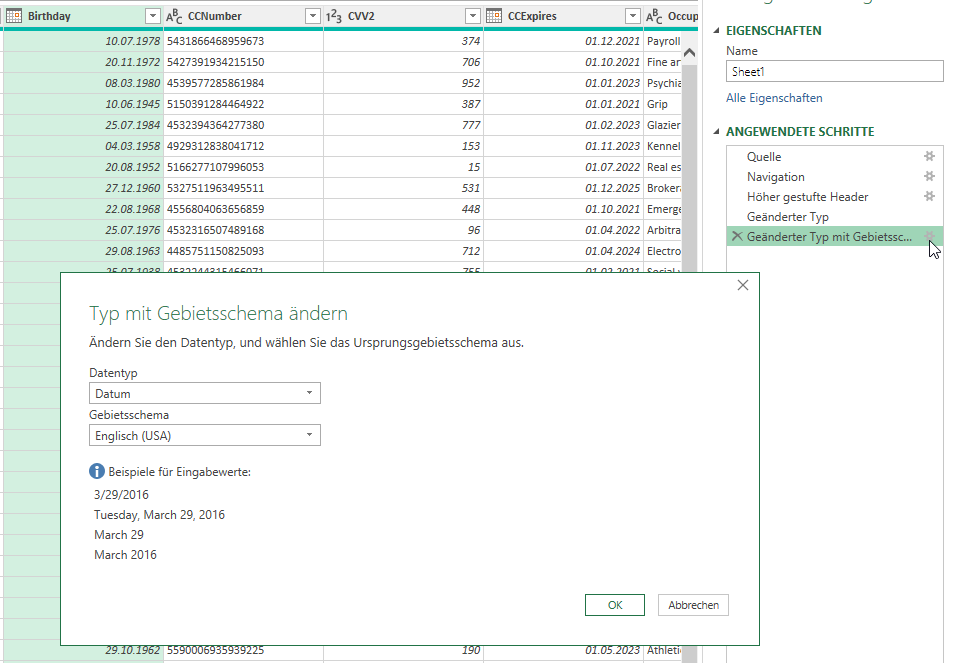
Wenn ich den Datentyp über das Gebietsschema ändere (beispielsweise Englisch (USA), habe ich die Möglichkeit mit einem Klick auf Zahnrad-Symbol hinter dem Schritt den Schritt zu ändern:
Wenn allerdings für sehr viele Spalten der Datentyp geändert wurde, gibt es für DIESEN Schritt kein Zahnradsymbol. Was macht man nun, wenn einer der Datentypen einer Spalte falsch ist?
Die einfachste Möglichkeit: Man markiert die Spalte und ändert den Datentyp in den richtigen Typ. Dann wird dieses Element ersetzt.
Natürlich kann man auch in der Bearbeitungsleiste den Teil per Hand korrigieren:
Oder: man löscht den ganzen Schritt und erstellt ihn neu. Letztere Variante ist natürlich wenig sinnvoll …
haben Sie vielen Dank, das hat prima funktioniert!
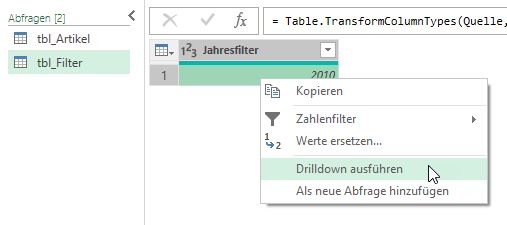
Nun soll aber im Tabellenblatt ein Wert manuell eingegeben werden, auf den dann die Berechnung der Spalte zugreift (ähnlich der Eingabe bei den Filterkriterien). Geht das?
#####
Hallo Frau I.,
Wenn Sie Werte auslagern möchten, dann „ziehen“ Sie die Daten nach PowerQuery, wählen den korrekten Datentyp (Text oder Zahl) und machen ein Drilldown, so dass nur noch ein Wert übrig bleibt.
Erstellen Sie eine neue Spalte, rechnen dort zuerst mit einem „harten“ Wert (beispielsweise +5) und ersetzen dann die zahl durch Ihre Variable (hier: + tbl_Plus)
Hilft das?
Hallo Herr Martin,
haben Sie vielen Dank!
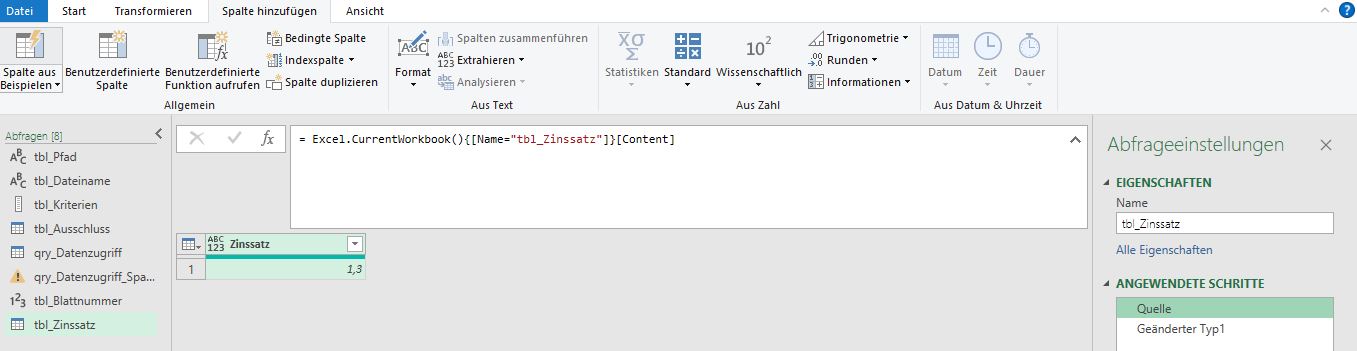
Ich habe ein bisschen damit herum probiert. Sofern ich bei einer Tabelle neue Spalten aus derselben Tabelle hinzufüge, klappt alle prime. Allerdings erhalte ich einen Fehler beim Hinzufügen einer Spalte in die Tabelle qry_Datenzugriff, die sich berechnen soll aus „Bodenwert“ (Spalte mit vielen Werten der Tabelle qry_Datenzugriff) mal „Zinssatz“ (Spalte der Tabelle tbl_Zinssatz mit nur einem Wert). Wie kann ich das lösen?
Hallo Frau Issel,
die ersten beiden Schritte sind richtig: Sie laden die Tabelle nach PowerQuery; Sie wandeln den Typ in Dezimalzahl (oder Prozentzahl) um.
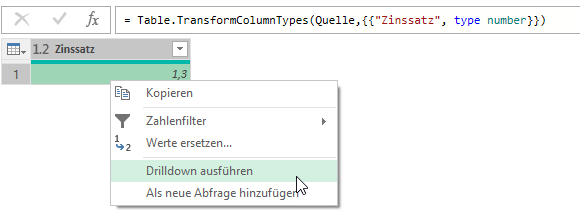
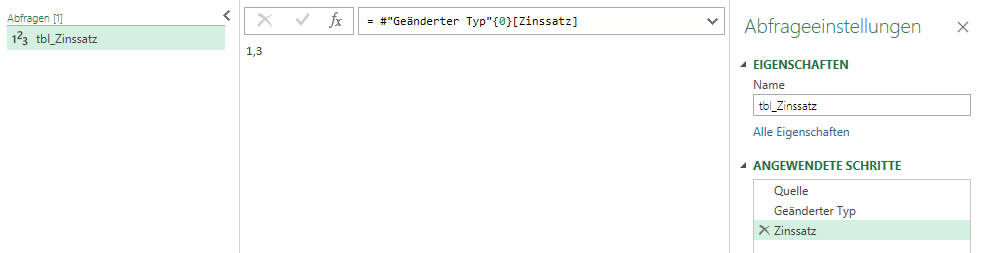
Aber dann fehlt der Drilldown: Sie müssen den Wert der Zelle in einen Wert verwandeln. Klicken Sie mit der rechten Maustaste auf die Zelle und führen den Drilldown durch:
Das Ergebnis sieht so aus:
Kann in einer Zeile geschrieben werden:
= Table.TransformColumnTypes(Excel.CurrentWorkbook(){[Name="tbl_Zinssatz"]}[Content],{{"Zinssatz", type number}}){0}[Zinssatz]
Und diese lange Formel können Sie nun in Ihrer Berechnung verwenden, also statt:
Table.AddColumn(#“Geänderter Typ“, „angemessener Zins“, each [#“Bodenwert €“]* 1.3)
Schreiben Sie:
Table.AddColumn(#“Geänderter Typ“, „angemessener Zins“, each [#“Bodenwert €“]* Table.TransformColumnTypes(Excel.CurrentWorkbook(){[Name="tbl_Zinssatz"]}[Content],{{"Zinssatz", type number}}){0}[Zinssatz] )
haben Sie vielen Dank, das hat prima funktioniert!
Nun habe ich eine neue Herausforderung: ich möchte weitere Spalten mit unterschiedlichen Berechnungen hinzufügen, bei denen neue Spalten auf Werte von zuvor hinzugefügte Spalten zugreifen. Das sollte möglich sein, vermute ich.
#####
Hallo Frau Issel,
zu Ihren Fragen: klar können sie mit einer berechneten Spalte weiterrechnen: Sie fügen eine benutzerdefinierte Spalte ein: MWST = [Netto] + 0.07
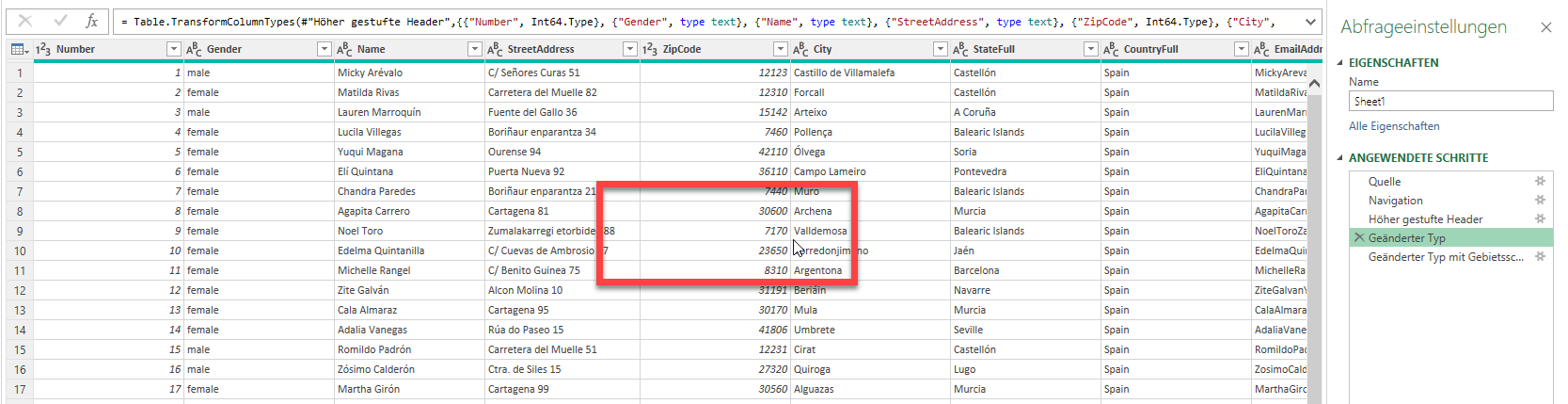
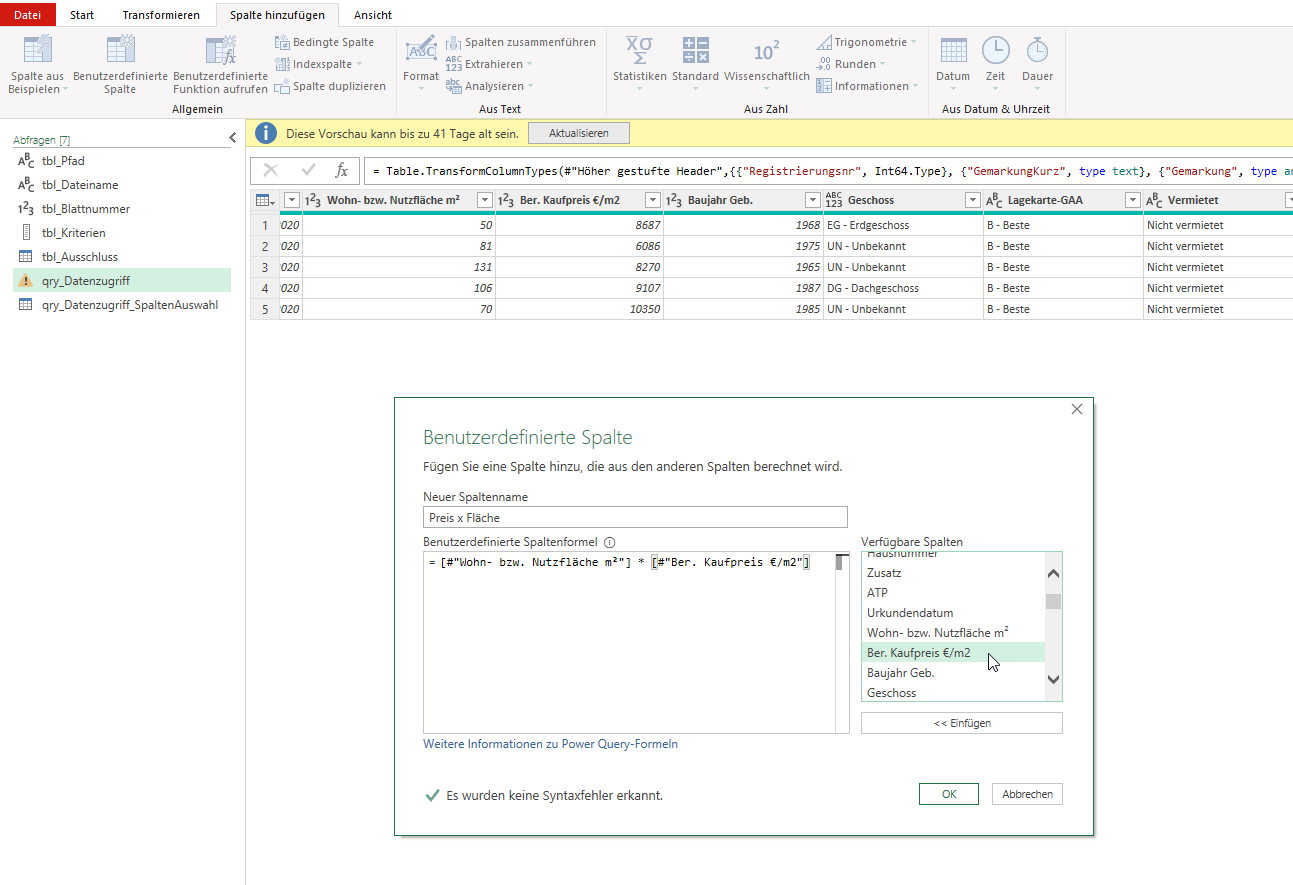
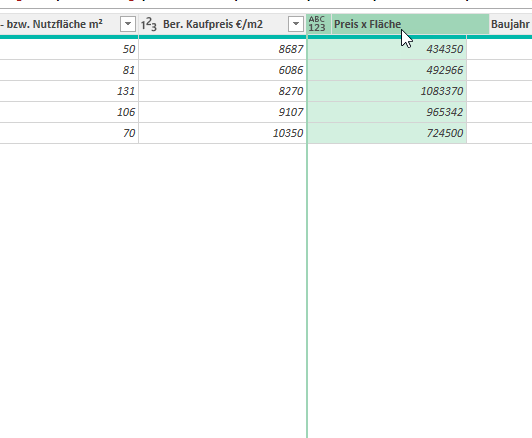
ich möchte aus den Werten von 2 Spalten Werte für eine 3. Spalte berechnen lassen und damit dann weiter rechnen. Kann ich das in PowerQuery erreichen?
Bspw. im Dokument Report09f.xlxs die Werte der Spalte K mal die der Spalte L. Anschließend möchte ich darüber Min, Max, Mittelwert berechnen, analog zu den Spalten, die im Exportdokument schon vorhanden sind.
Viele Grüße,
####
Hallo Frau I.,
in PowerQuery können Sie über „Spalte hinzufügen“ / Benutzerdefinierte Spalte eine Berechnung hinzufügen. Geben Sie dort den Namen der neuen Spalte an und die Berechnung, indem Sie auf diese langen Feldnamen doppelklicken!
Diese Spalte wird ans Ende der Tabelle gesetzt; Sie können sie schnell (über das Kontextmenü) an den Anfang verschieben:
Und dann per Hand etwas nach rechts:
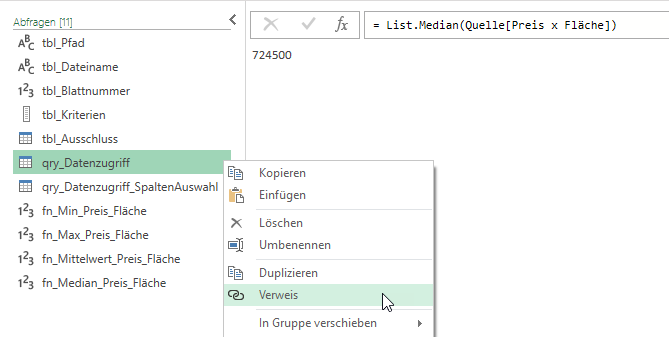
Für die Aggregatfunktionen: erstellen Sie einen Verweis auf die Tabelle
Markieren die Spalte und wählen aus Transformieren / Statistiken die gewünschte Funktion aus.
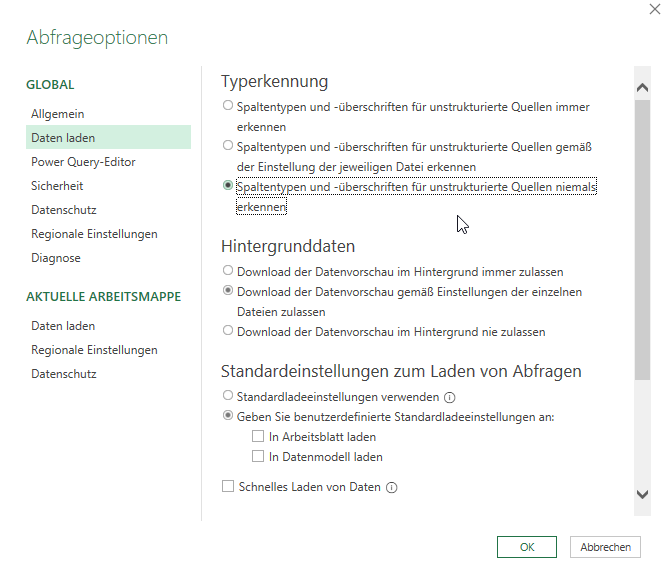
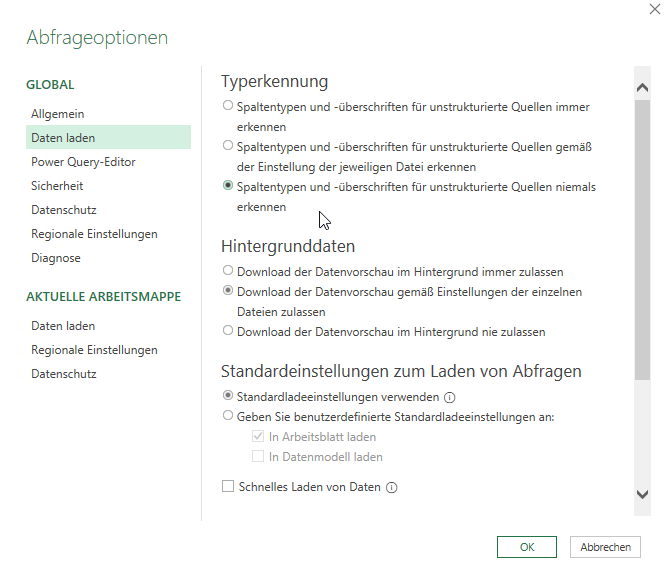
In PowerQuery-Schulungen empfehle ich die Option „Spaltentypen und -überschriften für unstrukturierte Quellen niemals erkennen.“ einzuschalten. Warum? Beim Import von Textdateien und CSV-Dateien werden Datumsinformationen in Zahlen konvertiert, wie folgende Screenshots zeigen:
Diese Option steht in Microsoft 365 – jedoch nicht in Excel 2016 zur Verfügung:
Allerdings: in einem Ordner befinden sich eine Reihe gleichförmig aufgebauter Excelmappen:
Greift man mit PowerQuery auf den Ordner zu und lässt sich den Content anzeigen, dann wird die erste Zeile nicht als Überschrift erkannt und in die Liste eingefügt:
Natürlich kann man die erste Zeile zur Überschrift machen und die übrigen Zwischenzeilen löschen. Ist aber nervig. Was tun?
Ich weiß es nicht?
Sich an der Variante orientieren, die man häufiger verwendet: Zugriff auf Ordner oder Zugriff auf Text/CSV-Dateien?
Vor dem Zugriff die entsprechende, geeignete Variante einschalten, beziehungsweise ausschalten?
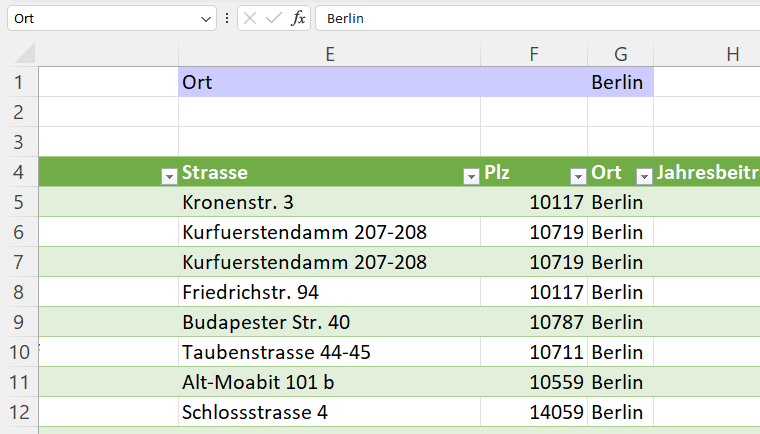
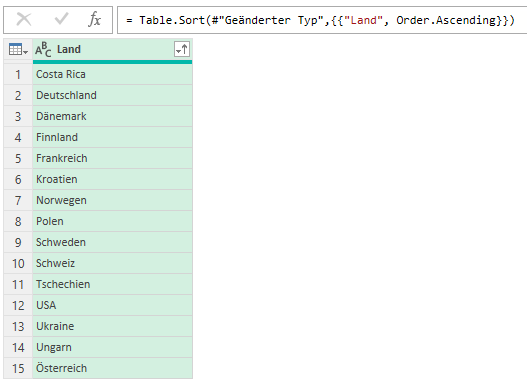
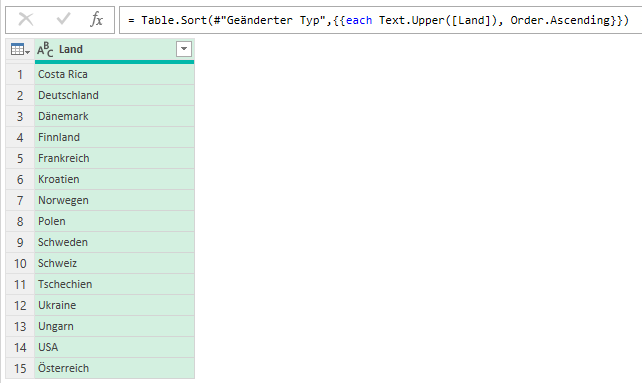
Schöne Frage in der letzten PowerQuery-Schulung: wo befindet sich das (auch Excel bekannte) Symbol, das erlaubt nicht nur eine Spalte zu sortieren, sondern nach mehreren:
Die Antwort: ein SYMBOL hierfür gibt es nicht – man muss die Spalten in der gewünschten Sortierreihenfolge anklicken und sortieren, beispielsweise zuerst Ort; innerhalb eines Ortes (Aachen) nach der PLZ, innerhalb einer PLZ (beispielsweise 52062) nach der Straße, …
PowerQuery quittiert die Mehrfachsortierung mit dem Befehl
herzlichen Dank für deine Bemühungen! Das bringt mich ein großes Stück weiter. Leider funktioniert aber irgendeine Kleinigkeit noch nicht… Ich hab viel probiert, komm aber nicht auf den Fehler.
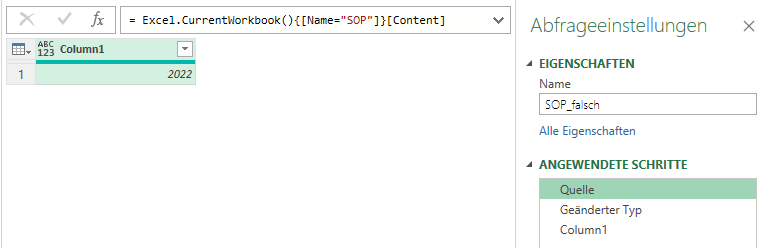
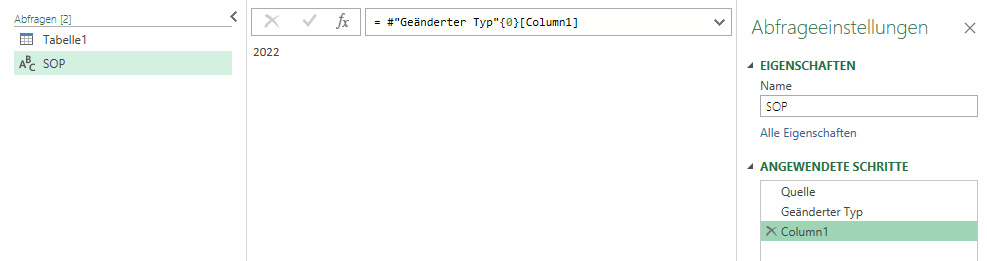
Expression.Error: Der Wert "2022" kann nicht in den Typ "Text" konvertiert werden.
Die Fehlermeldung verstehe ich nicht. Das Jahr, nach welchem gefiltert werden soll.
Hallo Nadine,
ist die Zahl 2023 in der Zelle als Text formatiert?
Und: was macht „geänderter Typ“? – in Text oder Zahl konvertieren?
Liebe Grüße
Rene
Hallo Rene,
genau, ich habe dann extra die 2023 in Text formatiert. Ursprünglich hatte ich es als Zahl, da kam allerdings auch diese Fehlermeldung, weshalb ich die 2023 dann in Text formatiert habe.
Hier die Schritte, welche ich in der Jahrestabelle ausgeführt habe:
Dort wo dann die Formel eingefügt wird, also dort, wo nacher nach diesem Jahr gesucht werden soll, sieht die Formatierung so aus:
Hallo Nadine,
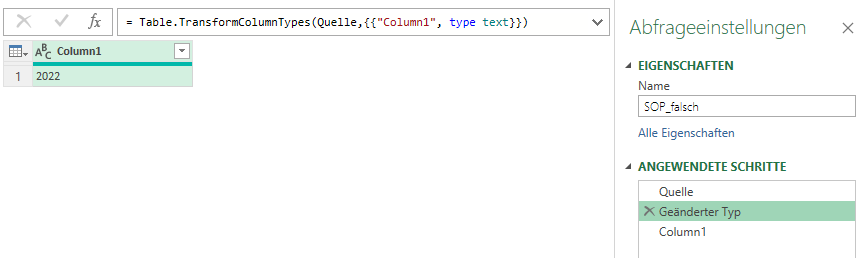
Folgende Ursache: Ich vermute in deiner Zelle stehe die Jahreszahl als ZAHL – in meiner ersten Städtedatei hatte ich sie als Text formatiert.
Damit du auch einen Text erhältst, muss dein zweiter Schritt
= Table.TransformColumnTypes(Excel.CurrentWorkbook(){[Name="SOP"]}[Content],{{"Column1", type text}}){0}[Column1]
verwendet werden
In deinem Code
= Table.SelectRows(Quelle, each (Record.Field(_ , Excel.CurrentWorkbook(){[Name="SOP"]}[Content]{0}[Column1]) <> null))
Zusammengefasst: der in Excel eingetragene Wert in eine Zahl. Die Spaltenüberschrift jedoch ein Text. Irgendwann muss die Zahl in einen Text konvertiert werden!
Ich habe schon eine Weile überlegen müssen. Folgende Frage erreichte mich:
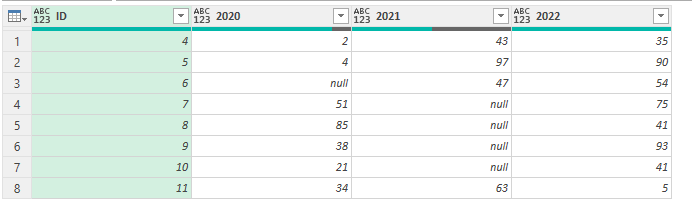
„Allerdings möchte ich nun in einer Spalte, die nicht fest definiert ist, filtern. Ist dies möglich?
Ziel: Ich möchte das es mir nur die Zeilen anzeigt, die in einer bestimmten Jahres-Spalte einen Wert haben.
Der Anwender des Tools sollte die Möglichkeit haben, ein Jahr einzugeben in einem bestimmten Feld.
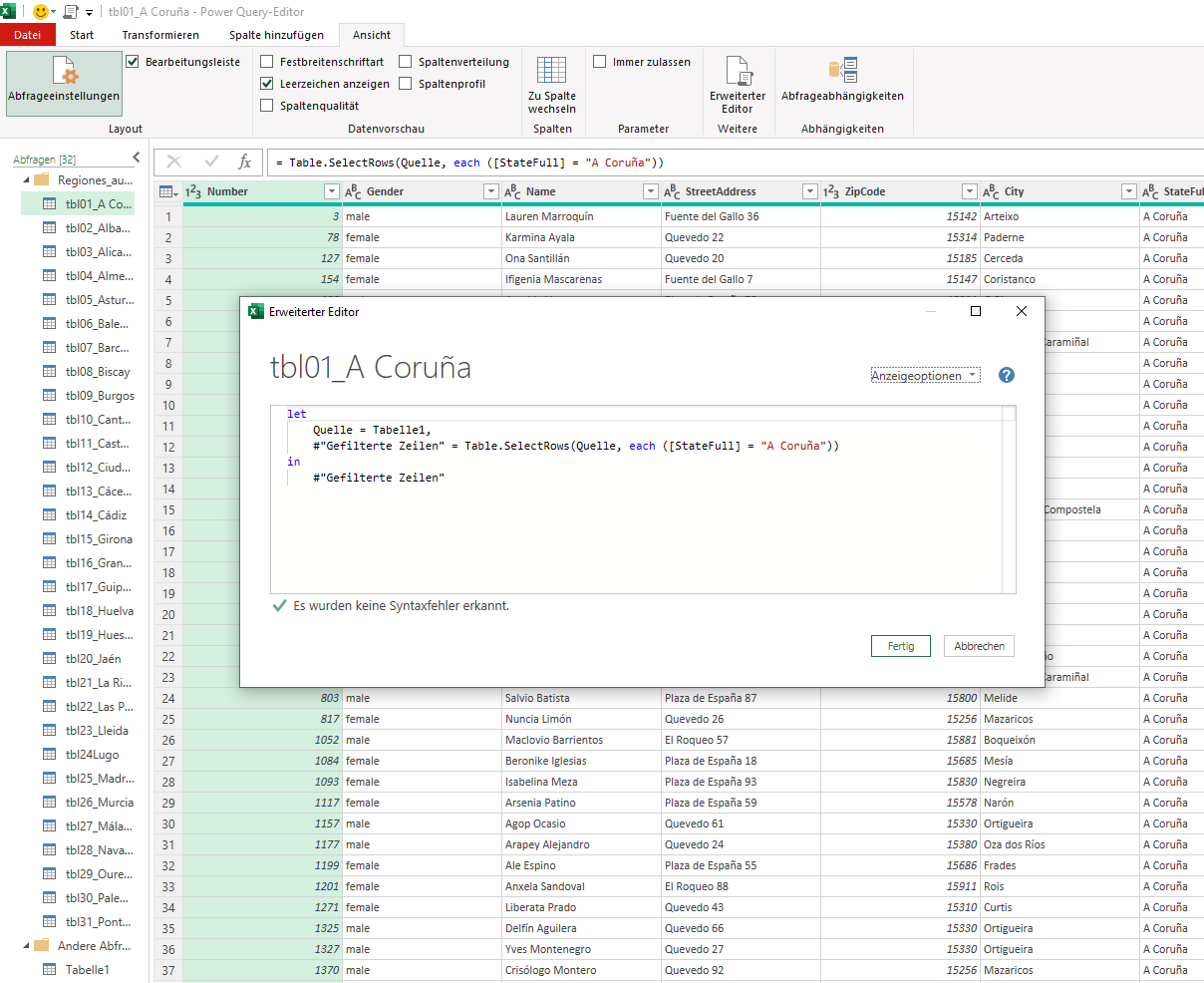
Hier wählt der Anwender das Jahr aus. Daraufhin sollte in Power Query in der Spalte, mit der Bezeichnung 2026, nach Werten <> null gefilter werden. Im Screenshot würde dann nur noch die erste Zeile erscheinen, da in der Spalte 2026 nur in der ersten Zeile ein Wert enthalten ist. Ich hab schon viel rumprobiert und bekomm es nicht hin.“
Ich ziehe das Ergebnis des Filters (versehen mit dem Namen „Jahr“) nach PowerQuery und benennen die Abfrage „Jahr“. Sie sieht folgendermaßen aus:
Kennst du das? Man möchte in PowerQuery in mehreren Spalten den Datentyp ändern. Ein Klick auf das kleine Symbol und alle Markierungen werden aufgehoben:
Abhilfe schafft der Befehl Transformieren / Datentyp. Lästig:
Die Lösung zeigt Frank Arendt-Theilen:
Man muss die [Strg]-Taste halten und zwei Mal auf das kleine Symbol klicken. Dann klappt es:
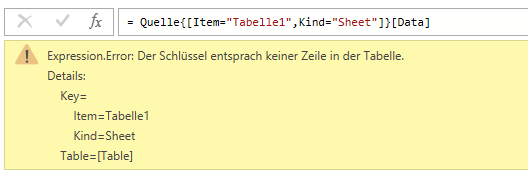
Expression.Error: Der Schlüssel entsprach keiner Zeile in der Tabelle.
Details:
Key=[Record]
Table=[Table]
nicht weiter.“
Ich schaue mir das Ganze an. Was haben wir gemacht?
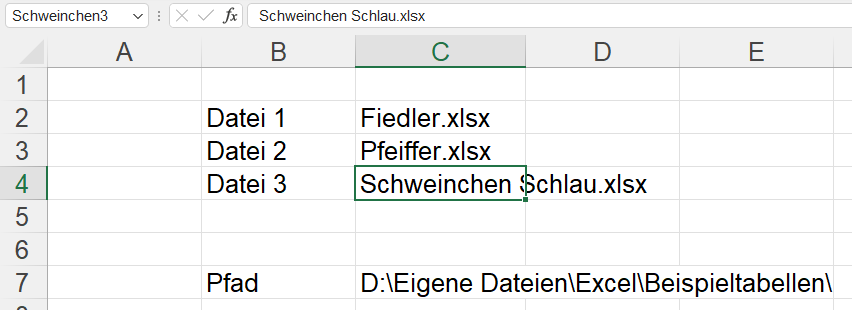
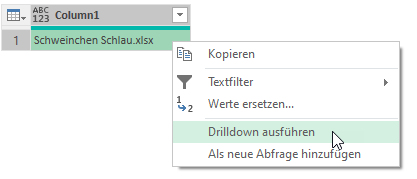
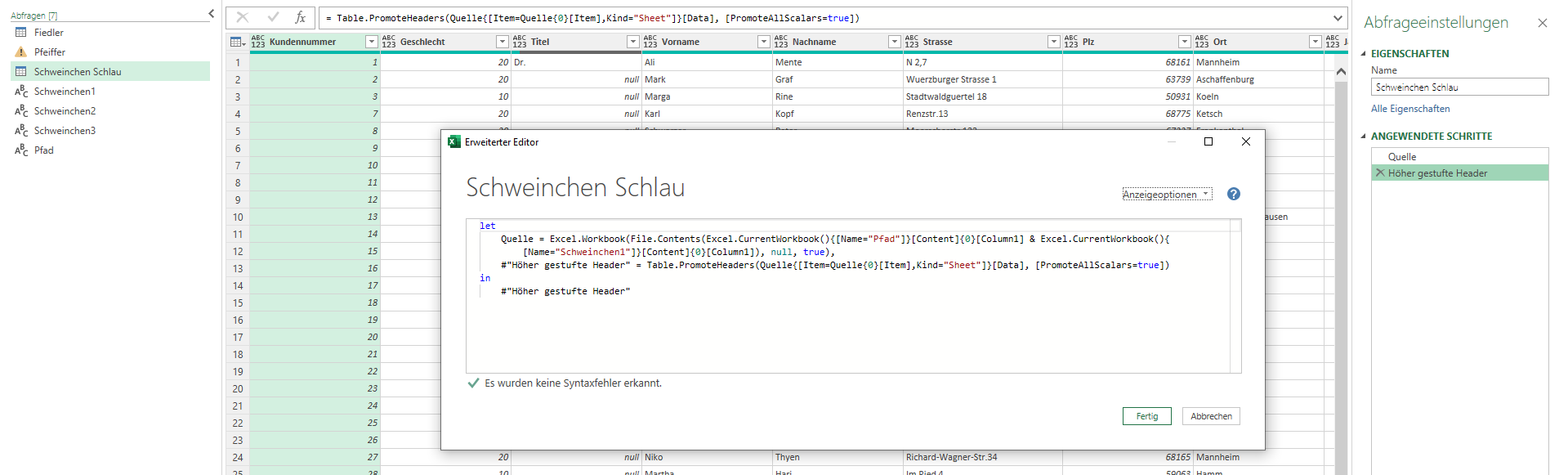
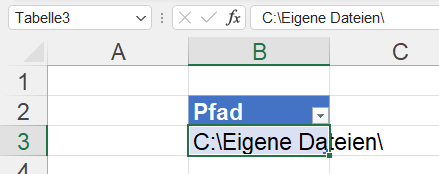
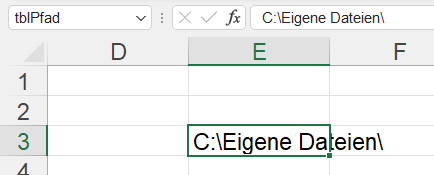
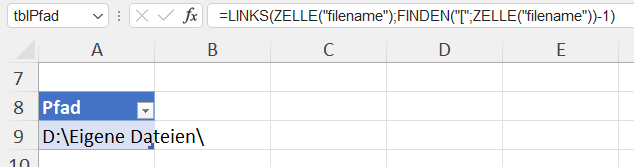
In einem Tabellenblatt werden drei Dateien aufgelistet und der Pfad, in dem sich diese Dateien befinden. Diese vier Zellen haben Namen – hier: Schweinchen1, Schweinchen2, Schweinchen3 und Pfad:
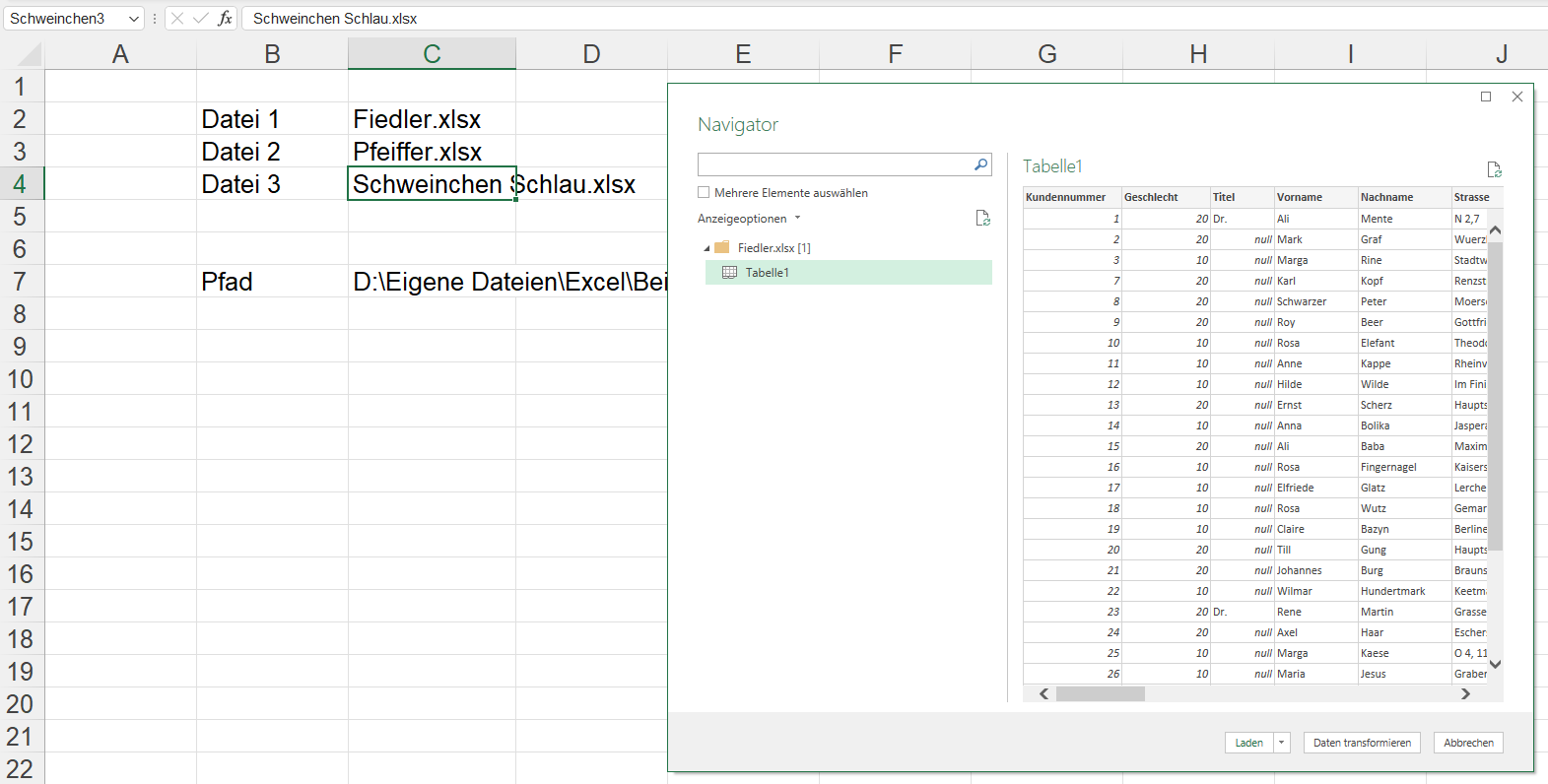
Über Daten / Daten abrufen / aus Datei greife ich auf eine der drei Dateien zu:
Die Datentypen werden nicht automatisch erkannt; übrig bleiben drei Schritte; das Ergebnis wird nach Excel zuzrückgegeben:
Eine der drei Zellen mit Namen wird über Daten / Daten abrufen / Aus Tabelle/Bereich in PowerQuery verwendet. Nach einem Drilldown erhält man den Inhalt der Zelle:
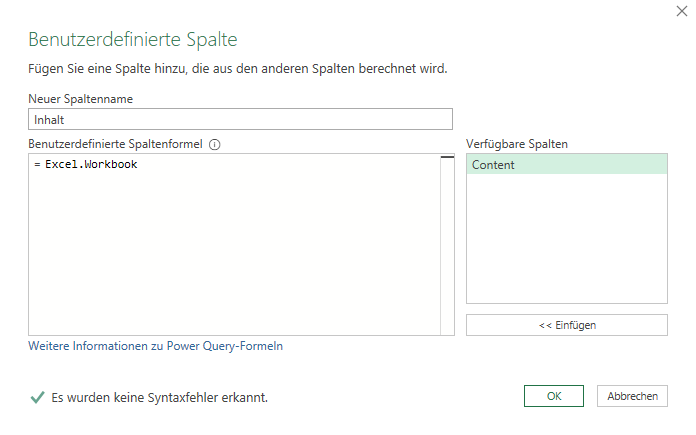
Dies wird für die übrigen Zellen wiederholt. Fügt man nun diese Variablen in den Befehl Excel.Workbook ein, so ist eine Firewall-Meldung die Folge:
Diese kann man umgehen, indem man den Code (Zugriff auf den Inhalt einer Zelle mit Namen) in eine Zeile schreibt:
Dies wird auch für die anderen beiden Dateien durchgeführt, die anschließend in Excel geladen werden:
Die Hilfsabfragen Schweinchen1, Schweinchen2, … kann man getrost löschen.
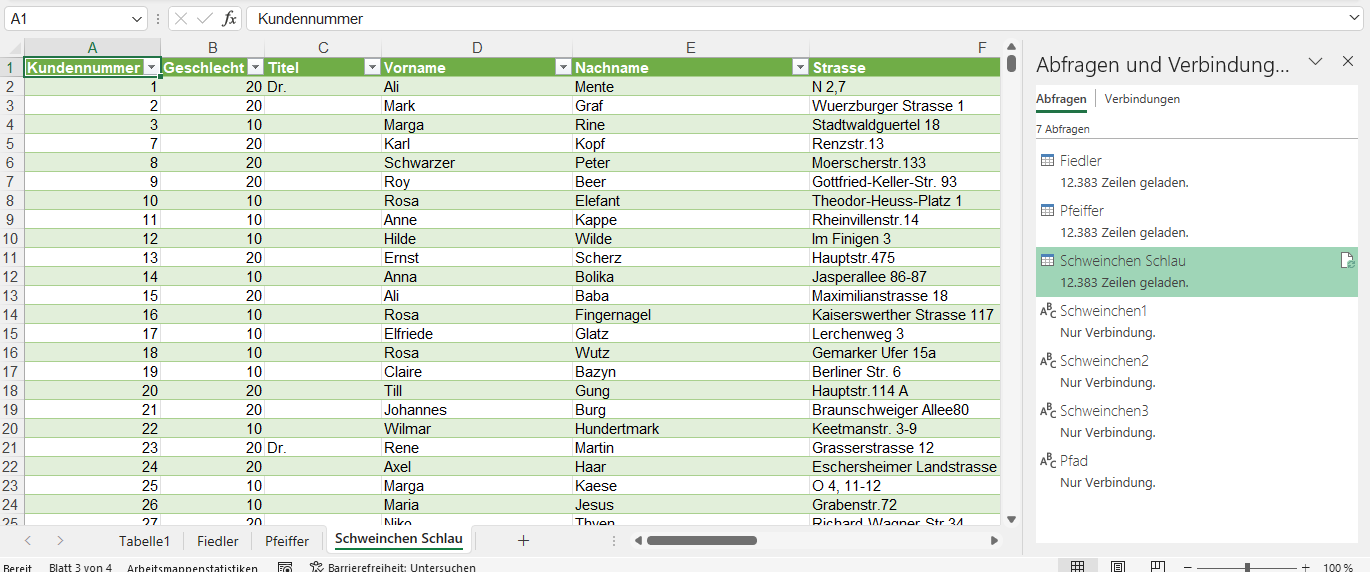
So habe ich die Vorlage erstellt. Und nun kommt die Fehlermeldung:
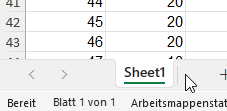
Expression.Error: Der Schlüssel entsprach keiner Zeile in der Tabelle.
Ich begebe mich auf die Suche. Der Fehler taucht beim Zugriff auf das Tabellenblatt „Tabelle1“ auf. Nachgeschaut: bei einer anderen Datei heißt das Tabellenblatt „Sheet1“:
Also muss ich auch noch den „harten“ Namen entfernen. Ich mache es so:
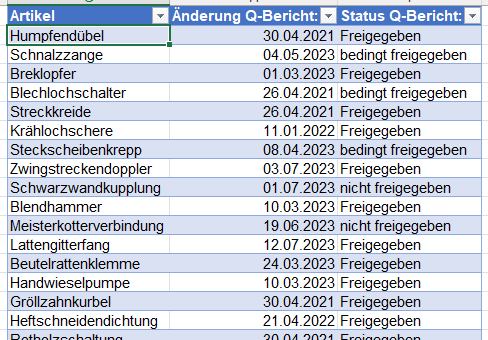
Ein Teilnehmer zeigt mir seine Tabelle. Sie hat sehr viele Spalten, in denen Informationszahlen stehen:
Seine Frage:
„Wenn ich eine Pivottabelle estelle (in der ich die vorkommenden Werte zähle), kann ich nicht die einzelnen Spalten in die Werte ziehen. Was muss ich tun?
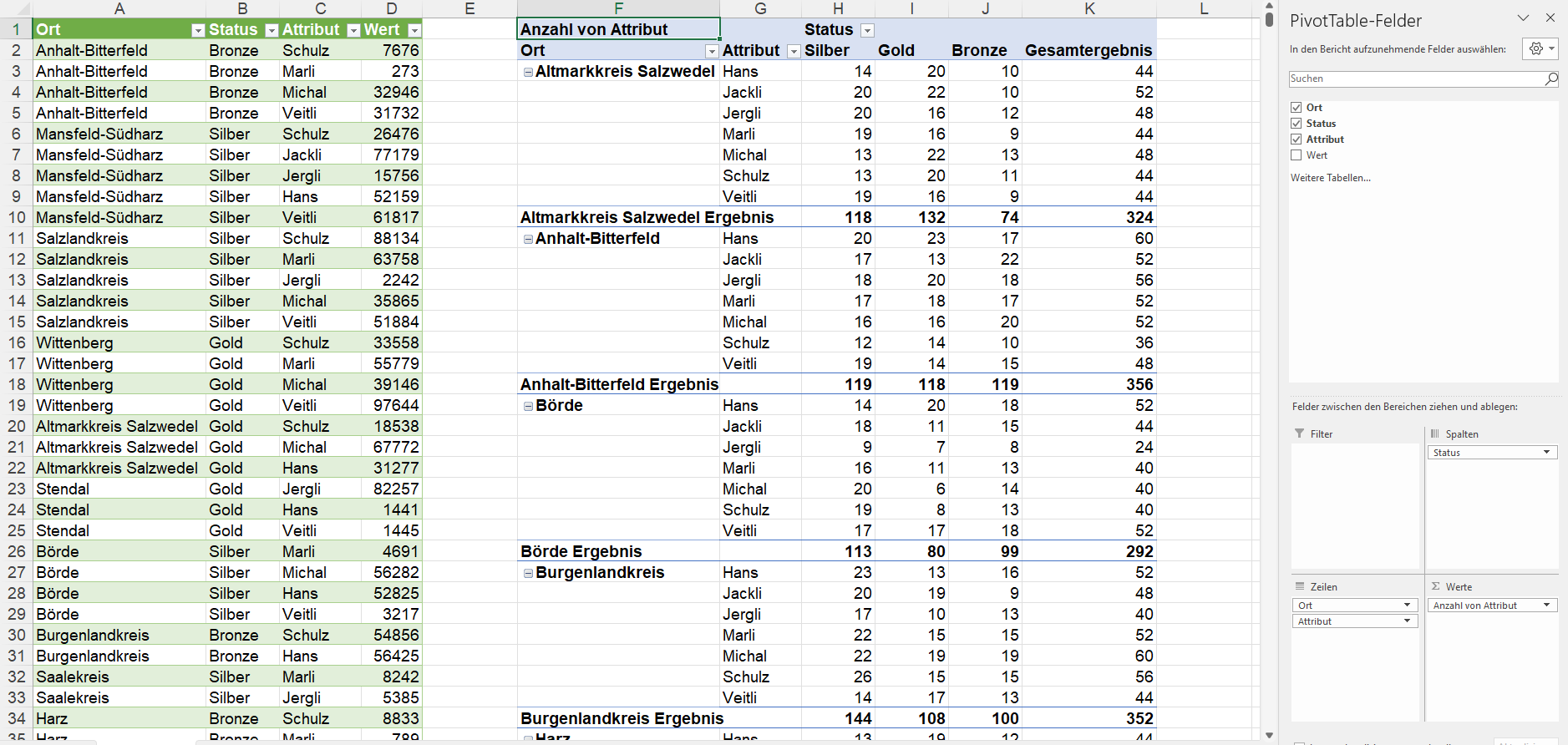
Die Aufgabe: Die Orte werden in den Zeilen gruppiert, in die Statusangaben in den Spalten. Man kann nun eine Person in die Zeilen ziehen und sich in den Werten die Anzahl der Einträge anzeigen lassen:
Jedoch: sobald eine zweite Person hinzukommt, arbeitet die Pivottabelle nicht so wie gewünscht:
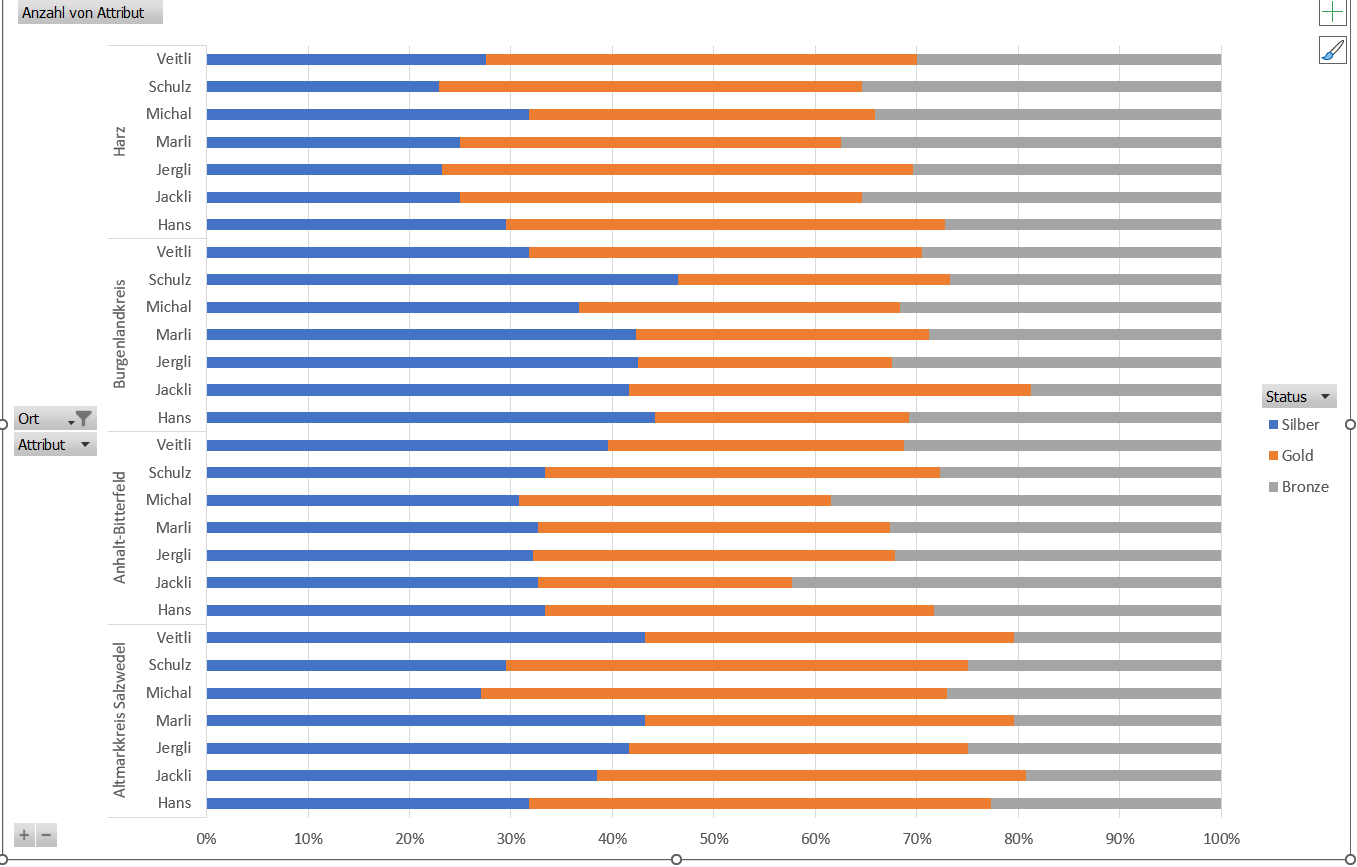
Da das Ziel war aus einer Pivottabelle ein Diagramm zu erzeugen, scheiden mehrere Pivottabellen aus.
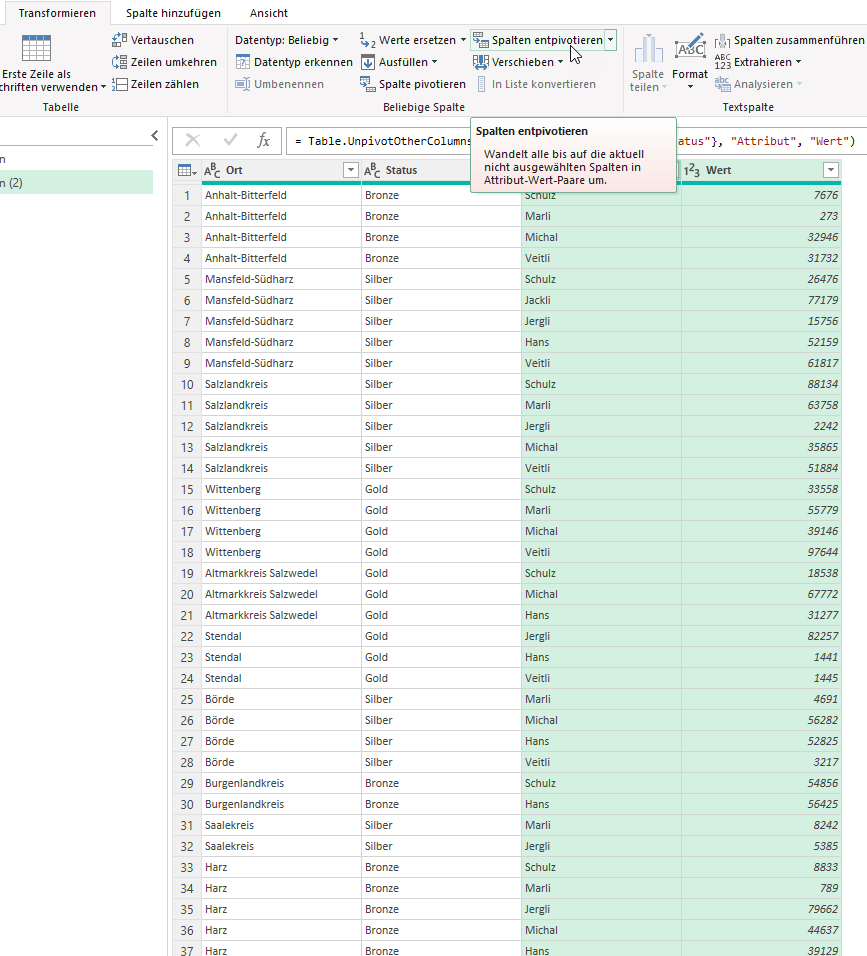
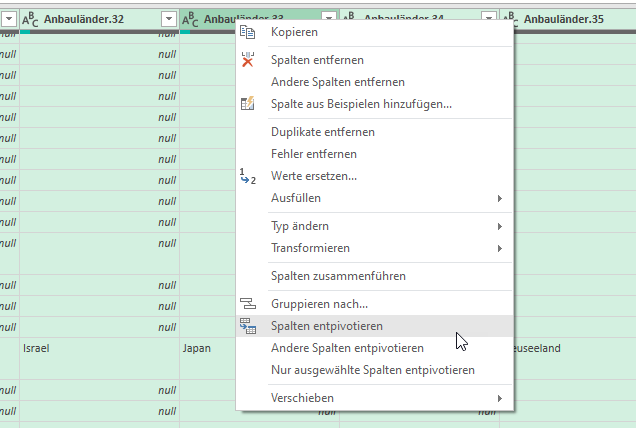
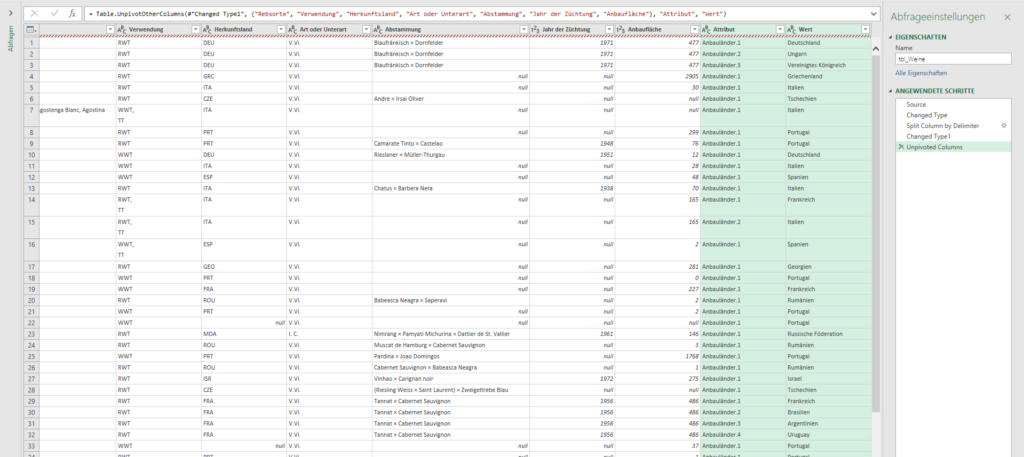
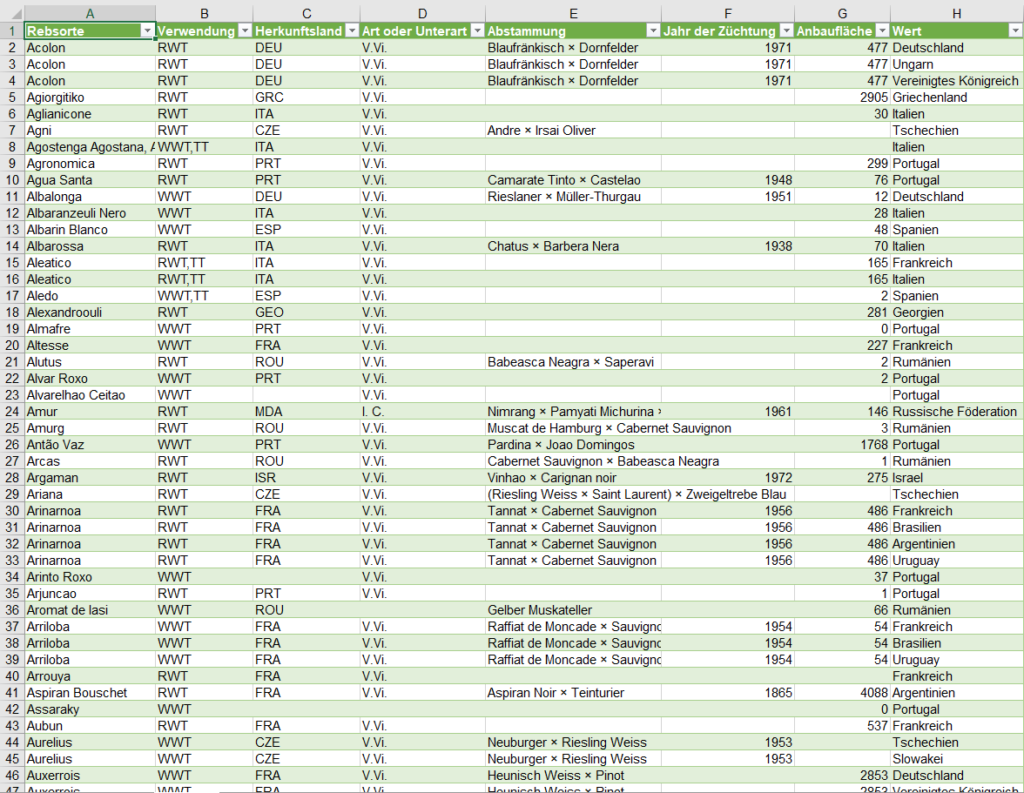
Ich überlege: die Form der Tabelle ist unglücklich gewählt. Man darf die Informationen nicht in Zeilen und Spalten abtragen. Man muss die Tabelle entpivotieren. Hier bietet sich PowerQuery an:
Gesagt, getan – die Liste wird erstellt. Eine Pivottabelle erzeugt:
Genau SO wollte er es haben! Als Basis für ein Diagramm. Er war begeistert.
Letzte Woche hat Martin Weiß (der tabellenexperte.de) auf unserem Excelstammtisch einige Tipps zu PowerQuery gegeben – damit Excel nicht mehr so nervt:
Die Möglichkeit, den Datentyp über ein Gebietsschema auszuwählen, ist hinlänglich bekannt:
(Randbemerkung: mit der Taste [F] gelangt man am schnellsten zu Englisch / USA)
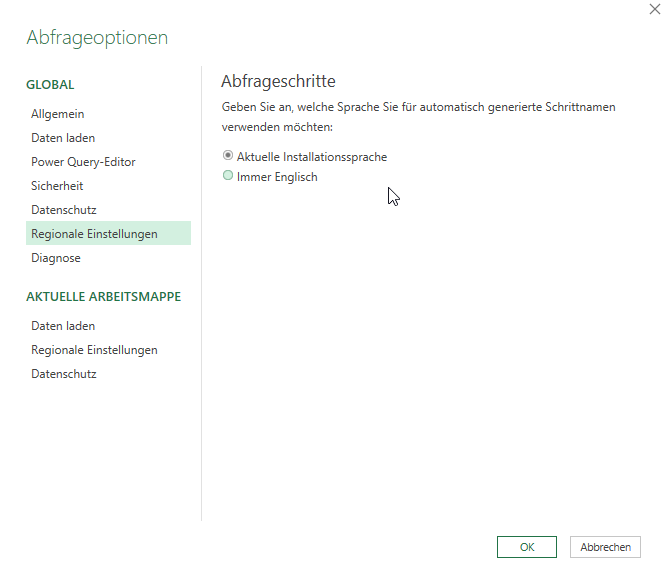
Benötigt man das andere Gebietsschema mehrmals, kann man dies in den Optionen in den Regionalen Einstellungen der Arbeitsmappe festlegen:
Hinweis: Nicht verwechseln mit den Regionalen Einstellungen, welche die Sprache der Namen der Variablen (beispielsweise Gefilterte Zeilen, Geänderter Typ, Sortierte Zeilen, …) festlegt:
Letzte Woche hat Martin Weiß (der tabellenexperte.de) auf unserem Excelstammtisch einige Tipps zu PowerQuery gegeben – damit Excel nicht mehr so nervt:
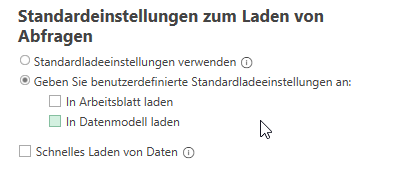
Kennt ihr das Problem? Man erstellt eine Reihe von Abfragen:
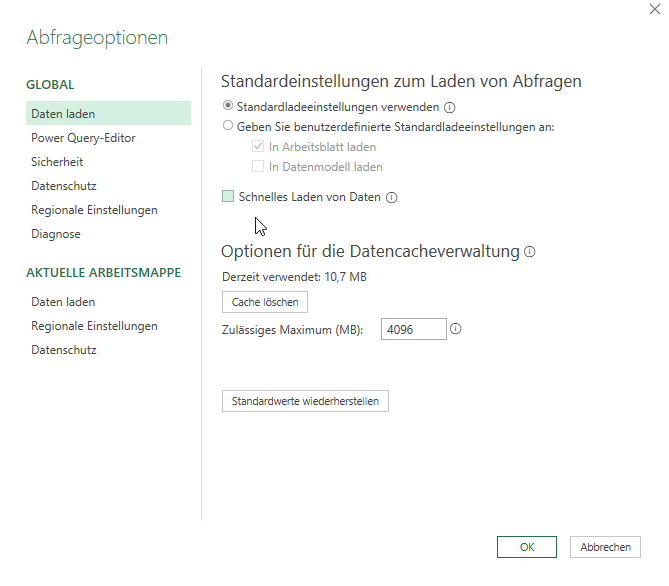
schließt den Editor, aber aus Versehen lädt man die Abfragen nicht als Verbindung, sondern als Tabelle – padautz – schon hat man 20 (ungewünschte) Tabellen.
Abhilfe schafft in den Optionen die „Standardeinstellung zum Laden von Abfragen“. Wählt man dort die Option „benutzerdefinierte Standardeinstellung“ und deaktiviert alle Kontrollkästchen, so werden die Abfragen nicht als Tabelle in Excel eingetragen.
Letzte Woche hat Martin Weiß (der tabellenexperte.de) auf unserem Excelstammtisch einige Tipps zu PowerQuery gegeben – damit Excel nicht mehr so nervt:
Beim Importieren von Daten „erkennt“ PoweryQuery den Datentyp der Spalten. Das kann nervig oder lästig sein oder auch zu Fehlern führen:
Diese Option kann man deaktivieren:
„Spaltentypen und -überschriften für unstrukturierte Tabellen niemals erkennen.“
Letzte Woche hat Martin Weiß (der tabellenexperte.de) auf unserem Excelstammtisch einige Tipps zu PowerQuery gegeben – damit Excel nicht mehr so nervt:
Wir haben drei Möglichkeiten gefunden, um Werte, die sich in Excel befinden, als Parameter in PowerQuery zu verwenden:
Die Werte stehen in einer intelligenten Tabelle:
2. Die Zellen, in denen sich die Werte befinden, werden mit einem Namen versehen:
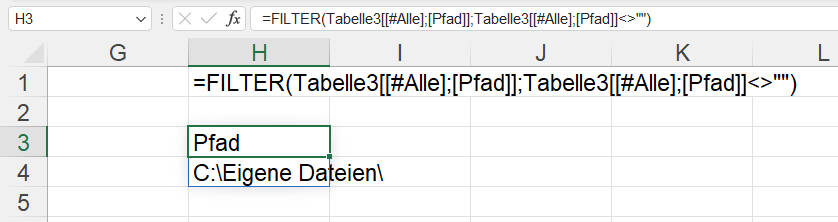
3. Die Werte sind das Ergebnis von Berechnungen von Array-Funktionen, beispielsweise FILTER oder SEQUENZ:
Letzte Woche hat Martin Weiß (der tabellenexperte.de) auf unserem Excelstammtisch einige Tipps zu PowerQuery gegeben – damit Excel nicht mehr so nervt:
Lagert man in Excel einen Datenpfad in eine Zelle, kann man den Wert in PowerQuery verwenden, wenn man einen Drilldown erzeugt hat:
Verwendet man nun diesen Wert, also diese Variable, ist eine Firewall-Meldung die Folge:
Natürlich kann man in den Optionen diese Firewall-Einstellungen ausschalten. Oder man kann das Problem umgehen, indem man den Verweis auf die Excelzelle nicht in einer getrennten Abfrage belässt, sondern in die Formel einbaut, beispielsweise so:
Ich habe ein Tabellenblatt, in dem jeden Tag neue Daten eingetragen werden und dann diese wieder gelöscht werden, da diese Daten mit einer Auswertung zusammenhängen. Da am nächsten Tag dort wieder neue Daten eingetragen werden müssen.
Und Power-Query aktualisiert ja im Normalfall nur die aktuellen.
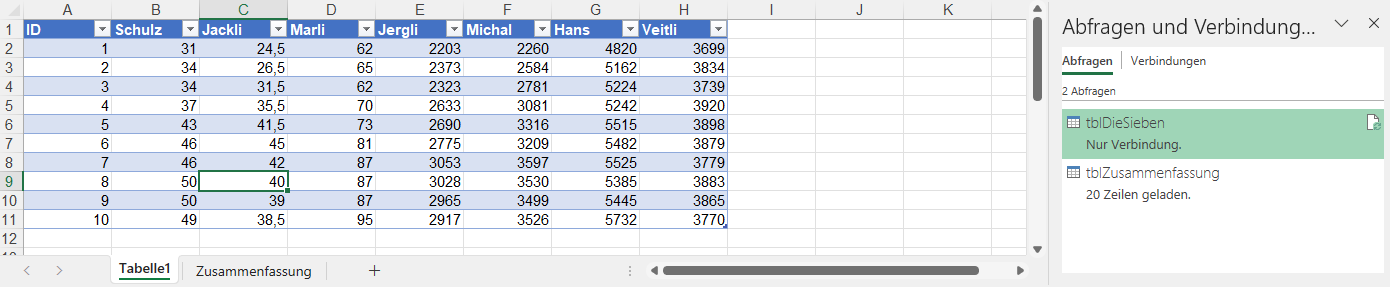
Ich habe nun folgendes versucht wie James Baylay in folgendem Beitrag:
let
Quelle = Excel.CurrentWorkbook(){[Name="tblZusammenfassung"]}[Content],
#"Geänderter Typ" = Table.TransformColumnTypes(Quelle,{{"ID", Int64.Type}, {"Schulz", Int64.Type}, {"Jackli", type number}, {"Marli", Int64.Type}, {"Jergli", Int64.Type}, {"Michal", Int64.Type}, {"Hans", Int64.Type}, {"Veitli", Int64.Type}}),
#"Angefügte Abfrage" = Table.Combine({#"Geänderter Typ", tblDieSieben}),
#"Entfernte Duplikate" = Table.Distinct(#"Angefügte Abfrage")
in
#"Entfernte Duplikate"
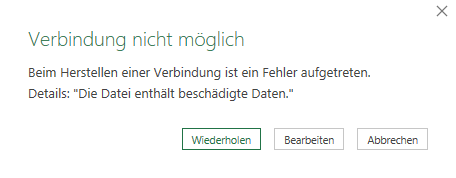
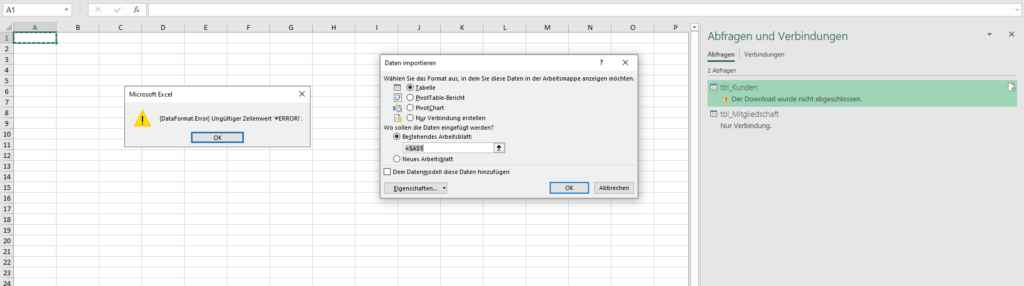
Ich habe folgendes Problem. Wenn ich bei der Abfrage «tblZusammenfassung» Laden-in / Nur Verbindung erstellen ausführe, dann kommt die untenstehende Fehlermeldung:
Vielleicht haben sie einen Tipp für mich, wie ich das Problem lösen könnte.
mir ist doch noch etwas besseres eingefallen, lässt sich aber auch nicht umsetzen…
Ich wollte jetzt direkt in Power Query filtern nach den Zeilen, welche im Jahr, welches ich im Excel Blatt auswähle, ungleich 0 sind.
Irgendwo passt was noch nicht, hoffe du kannst mir helfen 😀
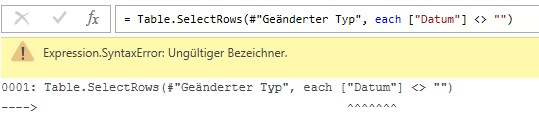
Hallo Nadine,
Wenn du Leerzeilen / Leerzellen rausfiltern möchtest, dann nicht wie in Excel mit zwei Anführungszeichen, sondern mit Null. Ähnlich wie Datenbanken hat PowerQuery einen eigenen Datentyp für leere Zellen: null:
= Table.SelectRows(#“Geänderter Typ“, each [Datum] <> null)
Und: der Feldname darf nicht in Anführungszeichen gesetzt werden – das Feld heißt: [Datum], nicht [„Datum“].
ich habe schon einiges in Power Query bearbeitet und bin gerade auf dem Stand, dass ich mir durch Filter genau die Daten aus Power Query ziehe welche ich benötige.
Aktuelles Problem: Ich möchte nur die Zeilen haben, welche in dem Jahr Werte haben, welches ich als Filter eingebe. Ich will aber nicht nur das Jahr, sondern alle Werte dann, wenn in diesem speziellen Jahr ein Wert vorhanden ist.
Den Filter „Jahr“ habe ich nicht in Power Query benutzt, da ich noch keine Lösung gefunden habe.
###
Hallo Nadine,
1.) wenn du einen Filter definierst, kannst du ihn auch in PowerQuery „reinziehen“. Danach würde ich ihn als Drilldown in einen Wert umwandeln – etwas so:
2.) Filtere ein beliebiges Datum. Es sieht dann so aus:
= Table.SelectRows(#“Gefilterte Zeilen“, each [Datum] >= #date(2020, 1, 1))
Und nun ersetze ich die Jahreszahl 2020 durch meine „Variable“ aus Schritt 1.
regex.Pattern = strMuster1
regexRaus.Pattern = strMuster1_Raus
regexRaus.Global = True
For i = 1 To ThisWorkbook.Worksheets(1).Range("A1").CurrentRegion.Rows.Count
If regex.Test(Range("I" & i).Value) = True Then
Set strTreffer = regexRaus.Execute(Range("I" & i).Value)
j = 0
For Each strFund In strTreffer
strTemp = strFund
If IsDate(strTemp) Then
If Len(Split(strTemp, ".")(2)) = 3 Or Len(Split(strTemp, ".")(2)) = 1 Then
Range("Q" & i).Offset(0, j).Value = strTemp
Range("Q" & i).Offset(0, j).Interior.Color = vbRed
Else
Range("Q" & i).Offset(0, j).Value = CDate(strTemp)
If Year(CDate(strTemp)) > Year(Date) Then
Range("Q" & i).Offset(0, j).Interior.Color = vbRed
End If
End If
Else
Range("Q" & i).Offset(0, j).Value = strTemp
Range("Q" & i).Offset(0, j).Interior.Color = vbRed
End If
j = j + 1
Next
End If
Next
Vier andere Varianten werden analog abgearbeitet. Klappt.
Warum hat VBA nicht als Standard Regex eingebunden?
Warum kennt PowerQuery keine regulären Ausdrücke?
Warum kann man keine regulären Ausdrücke beim Autofilter oder Spezialfilter eingeben?
Nachtrag: Ich habe etwas gewühlt. Imke Feldmann beschreibt, wie man über JavaScript einen Zugriff auf RegEx erhält:
Und: vor einigen Jahren hatte ich eine XML-Schulung, in der ich die regulären Ausdrücke vorgestellt hatte. Die Teilnehmerinnen kannten sie, waren damit vertraut, arbeiteten in „anderen Welten“ damit und waren begeistert. Sie wollten sich sogar T-Shirts mit dem Aufdruck „I ♥ RegEx“ drucken lassen. Haben sie aber doch nicht.
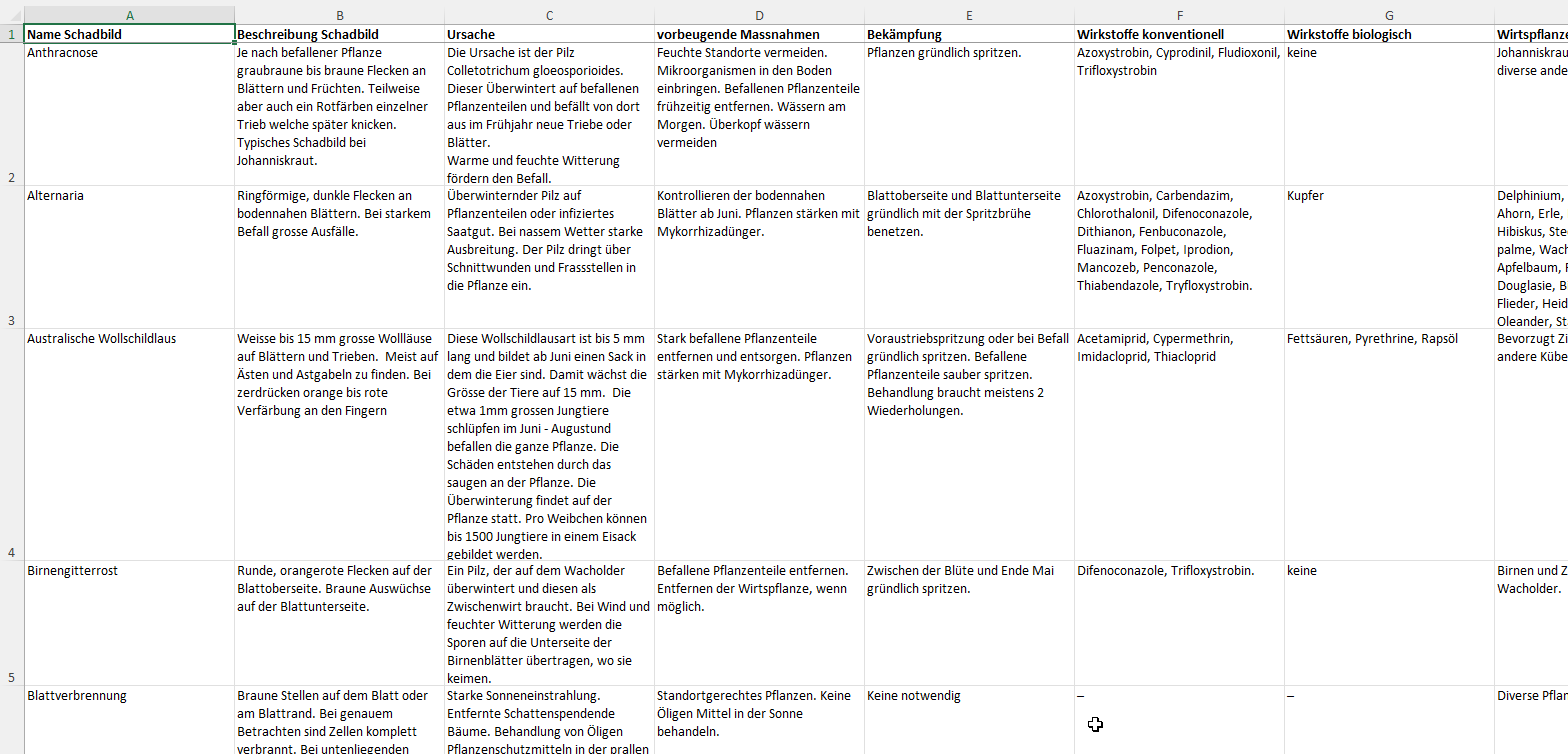
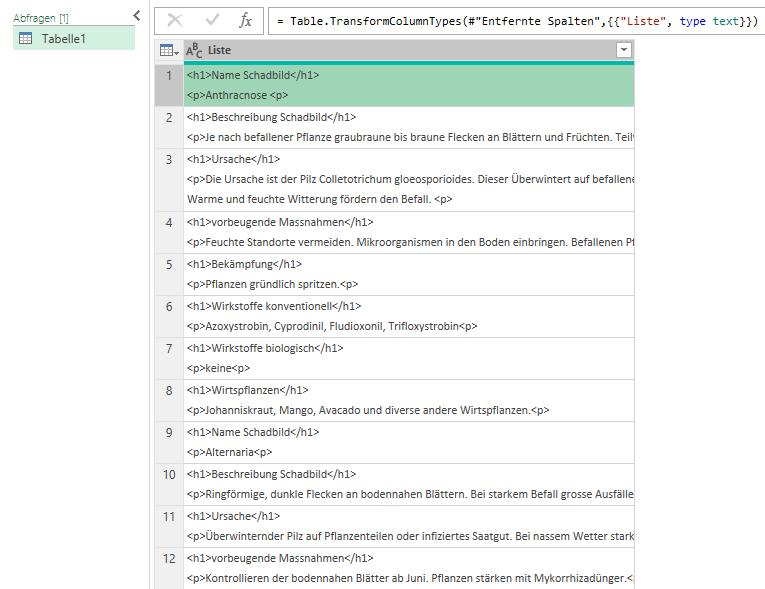
Du, ich muss mich verzweifelt bei dir melden mit einem Excel-Problem. Ich mache einen Import zu WordPress und der Kunde hat mir die Inhalte als Excel geliefert. Es geht um Schadbilder (Gärtner-Themen). Jedes Schadbild wird ein Artikel und sollte deshalb eine Zeile sein. Soweit so gut, jetzt der Kniff: Jeder Text hat Zwischentitel und diese sind aber als Spalten im Excel File angelegt. Also sind die verschiedenen Spalten nicht einzelne Felder in WordPress, sondern ein grosses Textfeld. Und die Spaltentitel sollten jeweils als Zwischentitel in diesen Texten zu finden sein. Die Zwischentitel sollten zudem ein HTML H-Tag erhalten und nicht einfach „fett und grösser“ sein.
Kannst du mir da vielleicht sagen, wie ich weiterkommen kann? Bitte sei ehrlich, wenn das deine Kapazitäten sprengt. Dann machen wir das manuell, das würde auch gehen, es sind um die 140 Artikel.
Ich gestehe – ich habe zuerst überlegt, dieses Problem mit TEXTVERKETTEN zu lösen. Als Trennzeichen hätte ich „</p><p>“ oder Ähnliches eingegeben. Aber irgendwie gefiel mir die Rechnerei nicht.
Warum nicht PowerQuery?
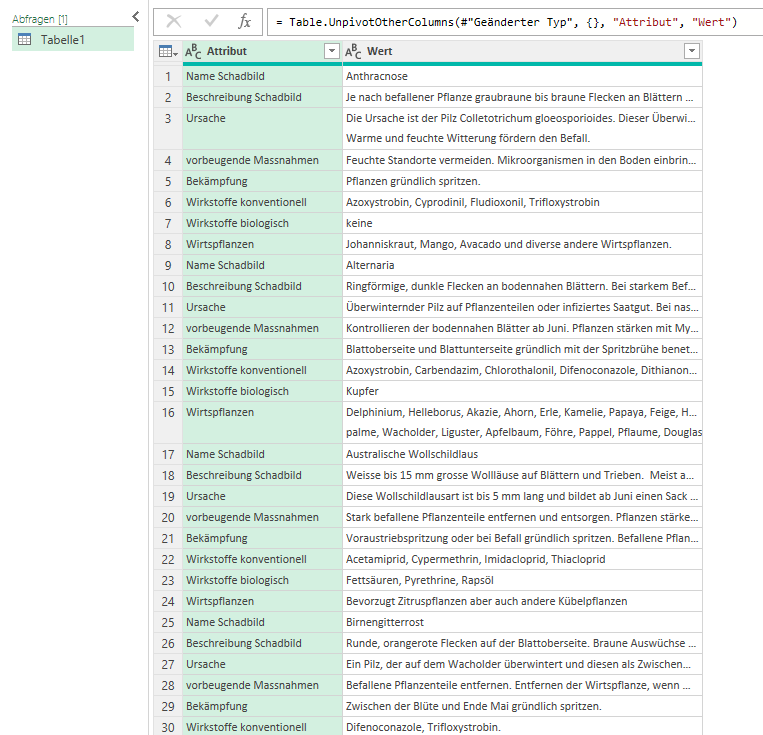
Klar: 1. Schritt: Liste in Tabelle verwandeln. Die Daten aus Tabelle/Bereich importieren:
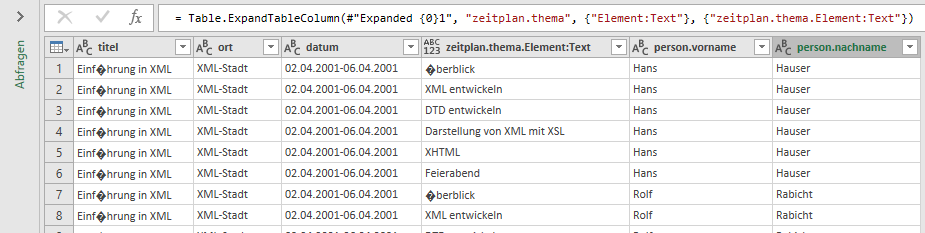
Das Zauberwort heißt „entpivotieren“. Und schon habe ich eine Tabelle mit zwei Spalten: in der ersten steht die Überschrift, in der zweite die Daten aus den entsprechenden Tabellen:
Und das kann problemlos zu einer Spalte verkettet werden:
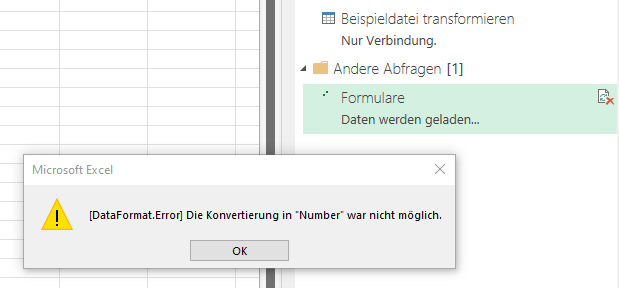
ich versuche gerade eine PowerQuery-Auswertung aus den Interviewfragebogen zu erstellen.
Ich erhalte allerdings die Fehlermeldung „Die Konvertierung in Number war nicht möglich.
Was mache ich da falsch?“
Was mache ich mit so einer Mail? Richtig: ich schlage vor, mir das Ganze über teams anzusehen. Und tatsächlich:
Okay. Langsam. Von vorne bitte. Können wir uns das Ganze mal bitte in Ruhe ansehen? Was machen Sie?
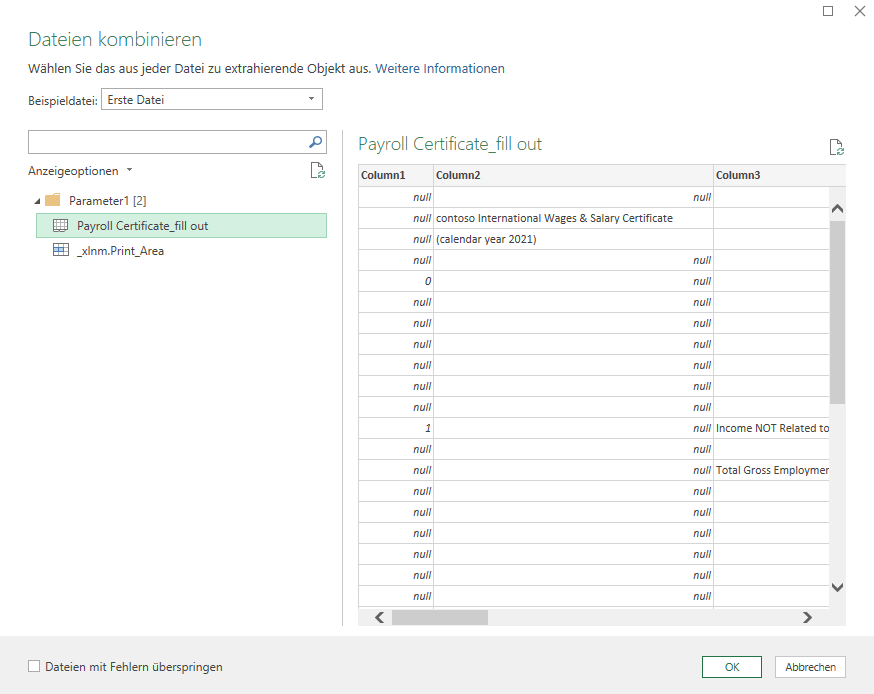
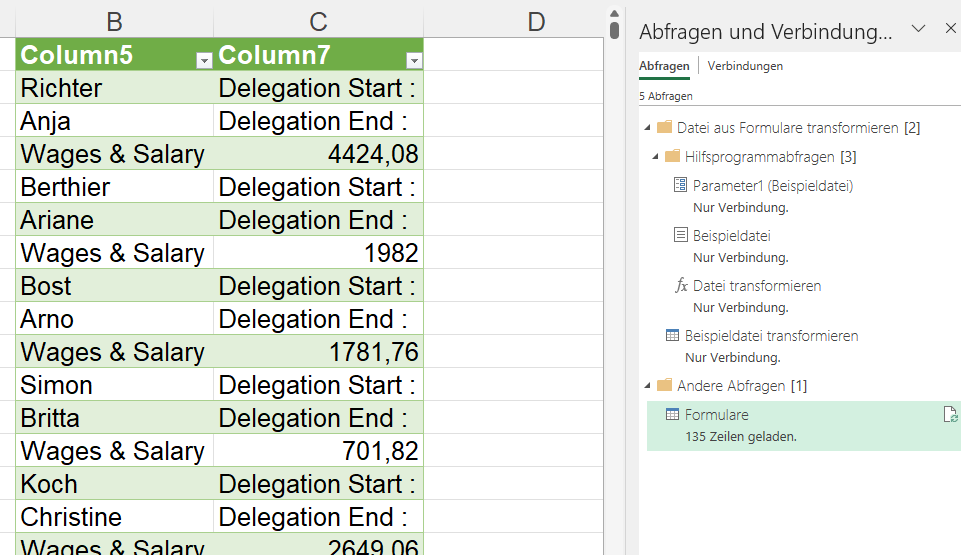
In einem Ordner befinden sich mehr als 50 Excelmappen:
Jede dieser Mappen hat folgenden Aufbau:
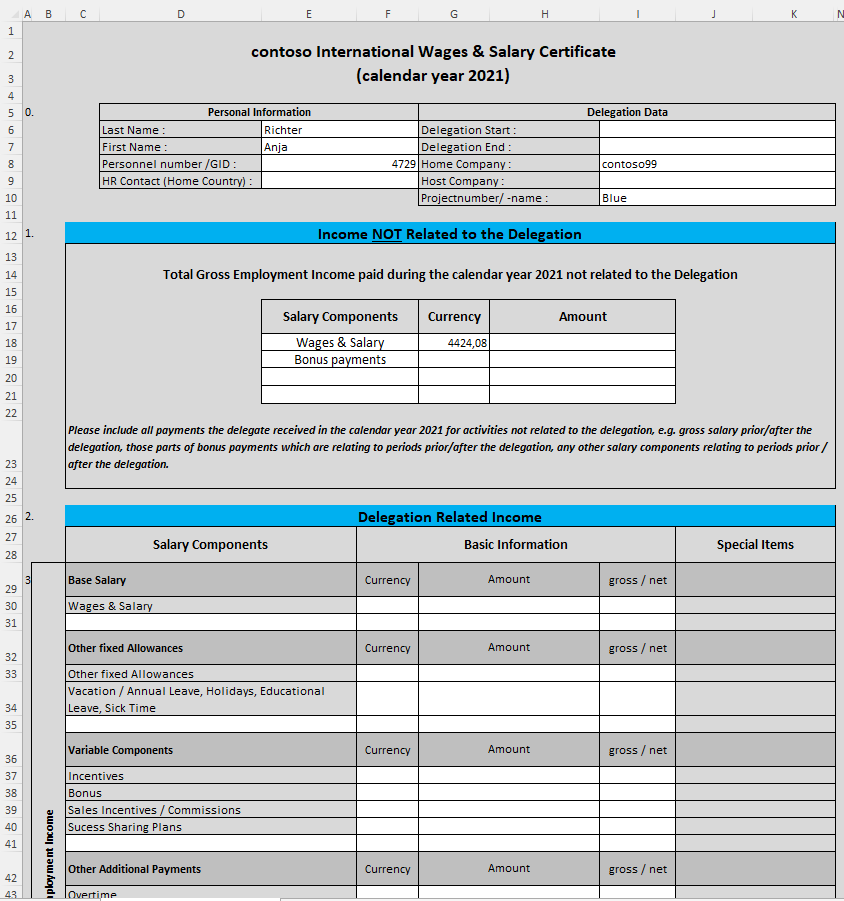
In Spalte A befindet sich in jedem Formular eine Nummer der Form 0., 1., 2., …
Aus einigen dieser Gruppen sollen Informationen ausgelesen werden. Diese Informationen befinden sich in Spalten rechts daneben. Soweit so gut – PowerQuery ist das richtige Werkzeug hierfür. Wir schauen uns das Ganze an – Schritt für Schritt:
Schritt: Leere Arbeitsmappe. Daten / Daten abrufen und transformieren / Daten abrufen / Aus Datei / Aus Ordner
2. Schritt. Der Ordner wird ausgewählt; die Daten werden transformiert.
3. Schritt: Unterordner werden ausgeschlossen; andere Dateitypen ebenso:
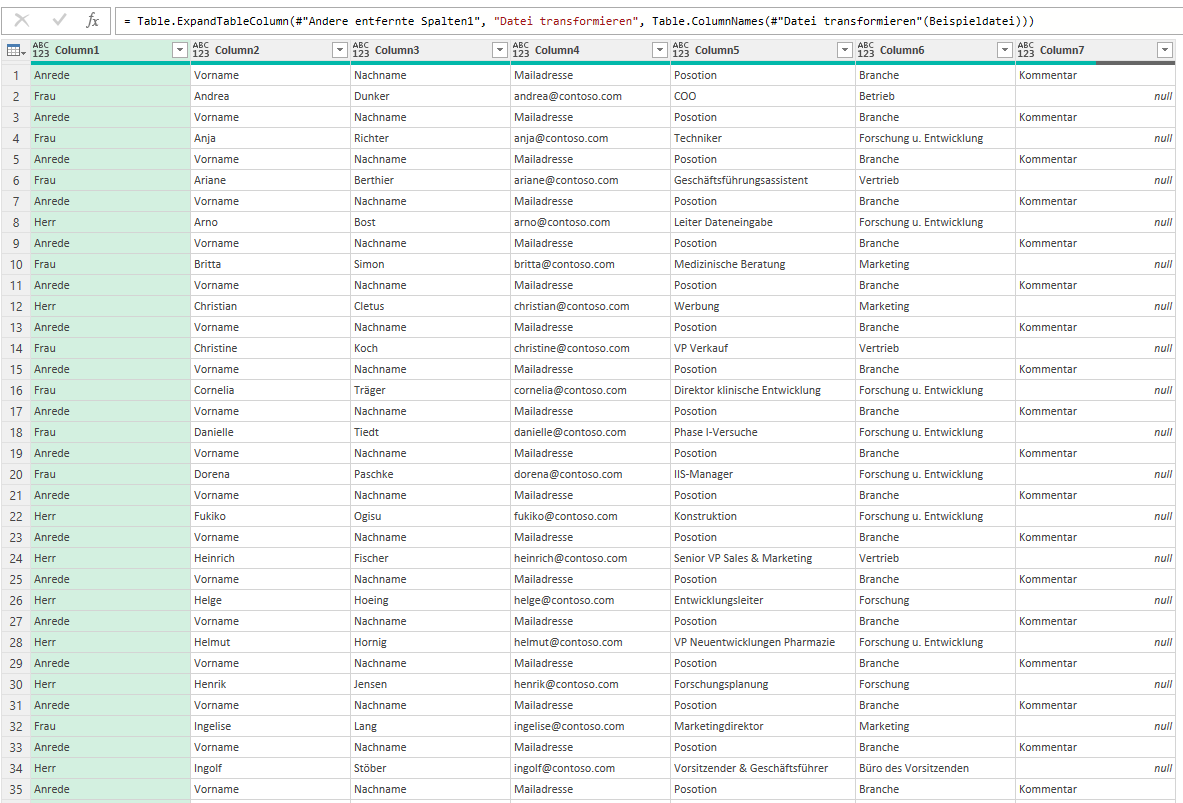
4. Schritt: In der Spalte „Content“ befindet sich der Inhalt. Da die Spalten alle den gleichen Aufbau haben, kann man die anderen Spalten löschen und diese Spalte „entpacken“:
Da alle Dateien den gleichen Aufbau und das gleiche Tabellenblatt haben, stellt dies kein Problem dar:
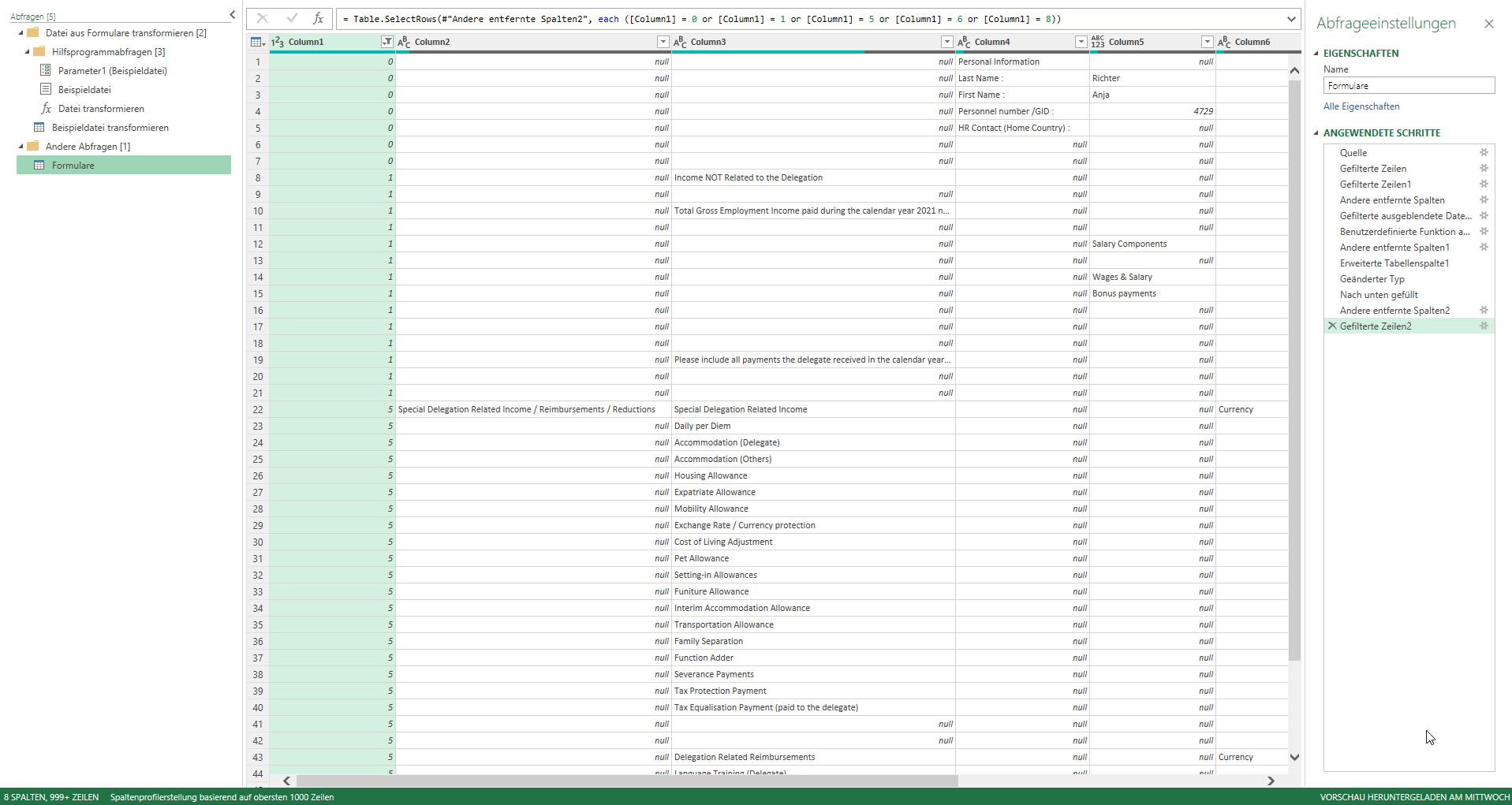
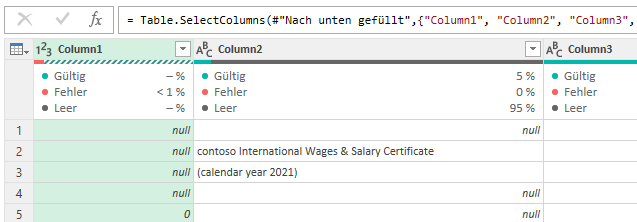
Das Ergebnis:
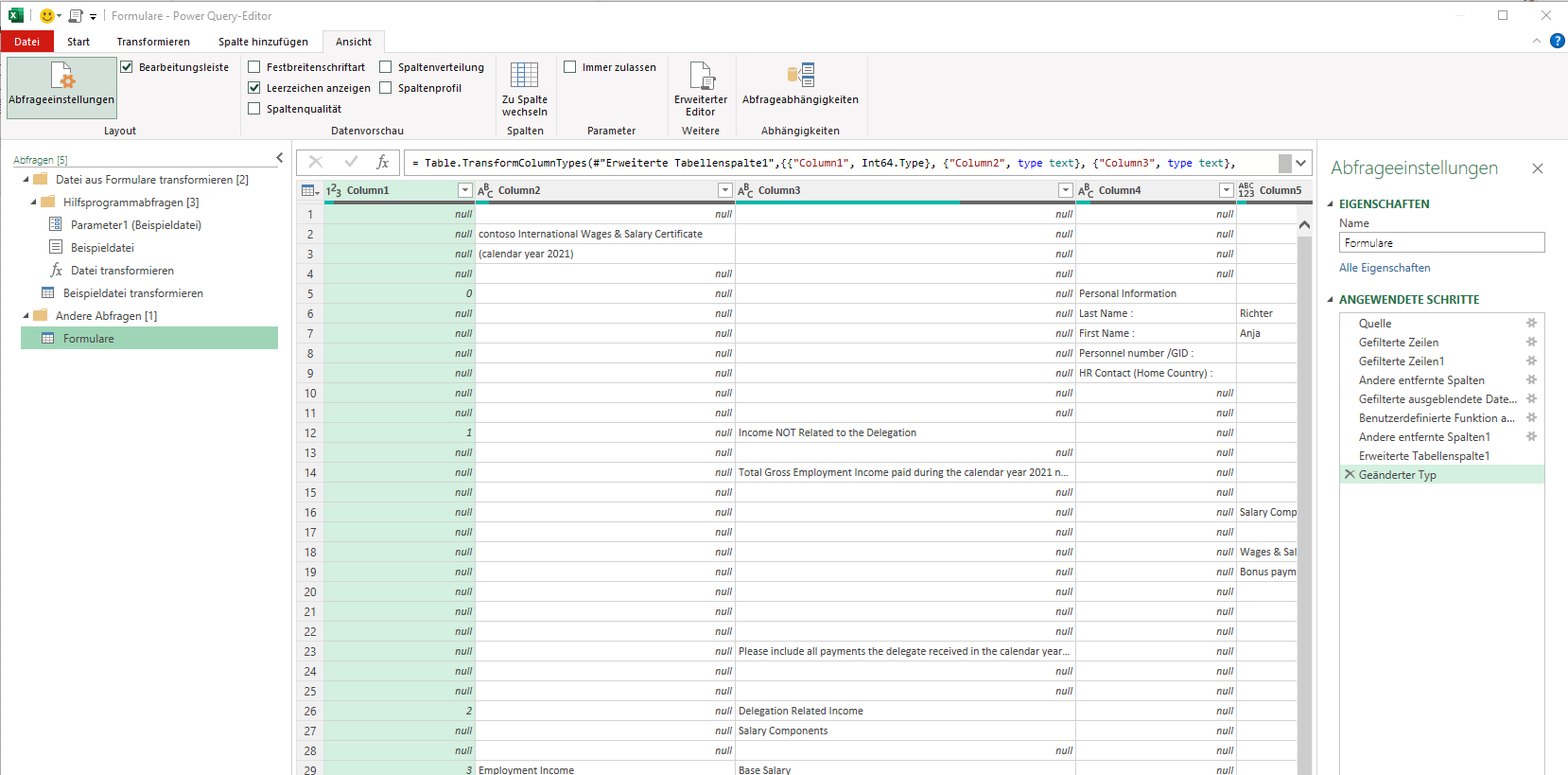
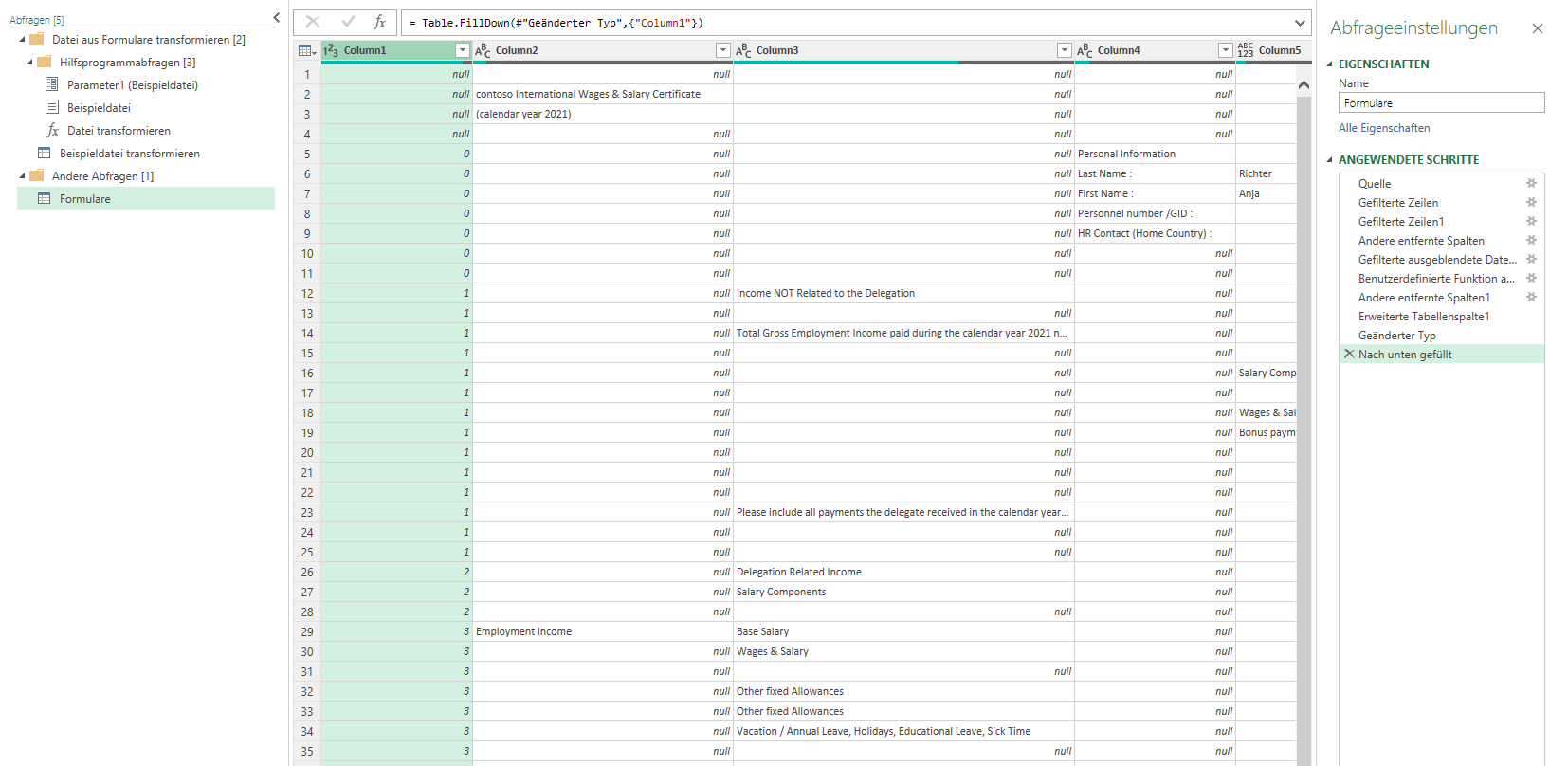
Da Informationen aus bestimmten „Gruppen“ geholt werden, wird die erste Spalte über Transformieren / Ausfüllen „nach unten gezogen“:
Einige Spalten werden gelöscht. Aus der ersten Spalte werden einige der benötigten Spalten selektiert:
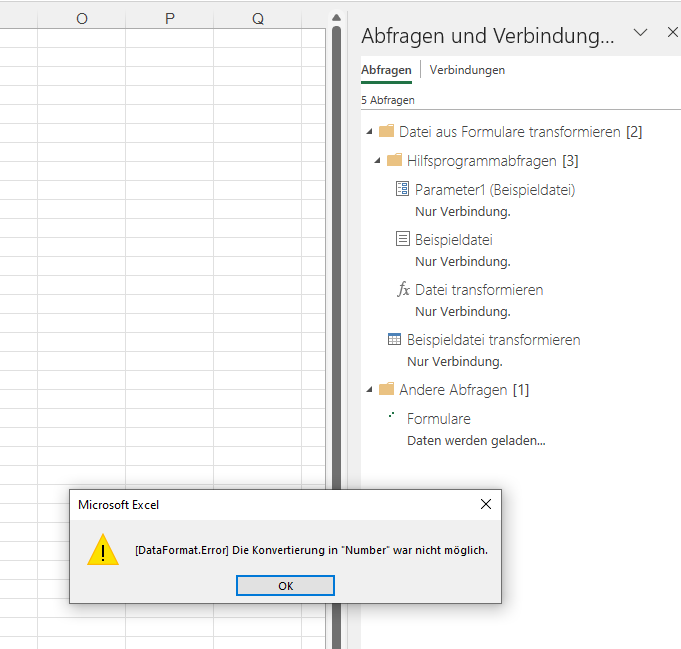
Das Ergebnis wird zurück nach Excel geschrieben (Start / Schließen & Laden / Schießen & Laden in). Obwohl die Daten in Powerquery korrekt angezeigt werden:
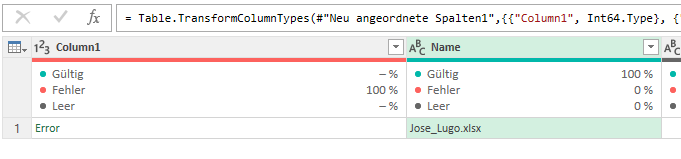
ist die Fehlermeldung die Folge:
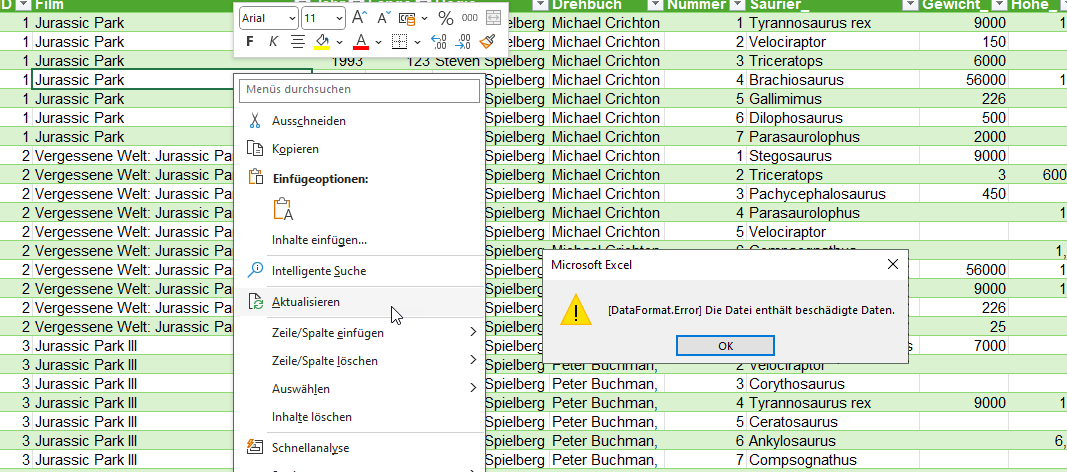
[DataFormat.Error]. Die Konvertierung in „Number“ war nicht möglich.
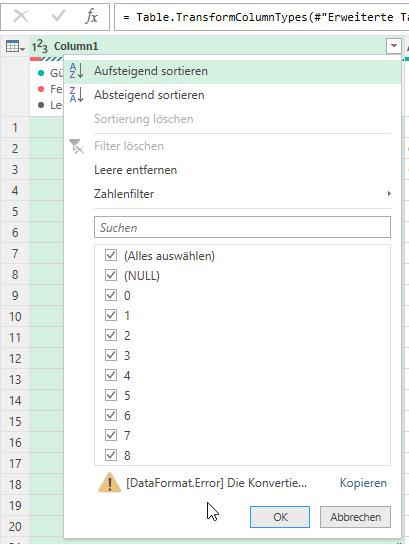
Ich stutze. Zurück zu PowerQuery. Vielleicht ist „irgend etwas“ in der ersten Spalte?!? Es sieht nicht so aus:
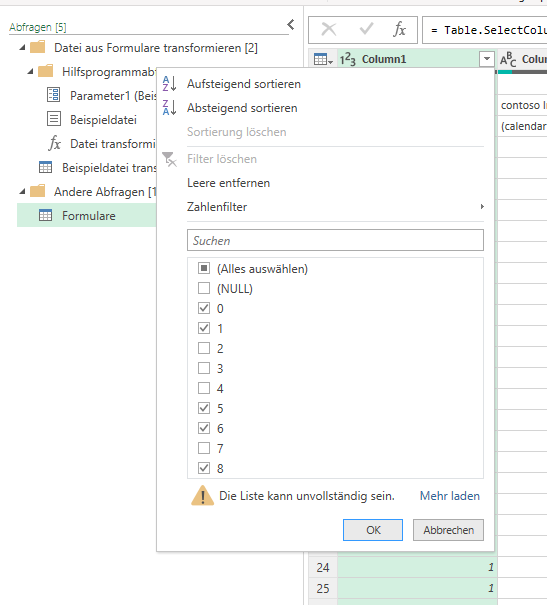
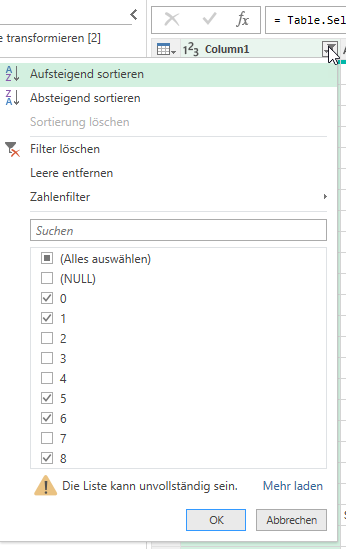
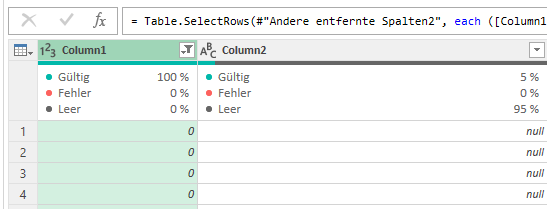
Aber: „Die Liste kann unvollständig sein.“ Ich lasse mir über Ansicht die „Spaltenqualität“ anzeigen:
Kein Fehler in der ersten Spalte!?!
Wirklich nicht?
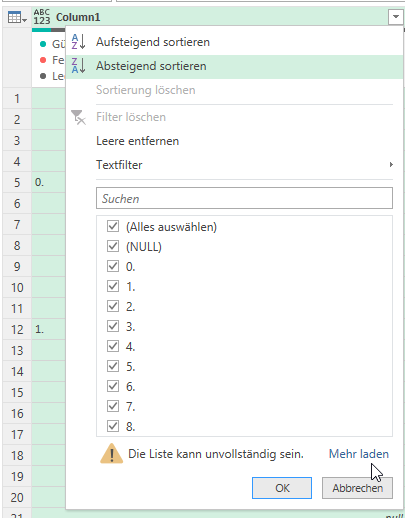
Wir wissen, dass PowerQuery zu Beginn nur 1.000 Zeilen auswertet. Bei 50 Formularen x zirka 150 Zeilen sind das 7.500 Zeilen. Okay – ich lasse ALLE Zeilen auswerten, indem ich auf der Statuszeile von 1.000 auf „alle“ wechsle:
Und tatsächlich: JETZT lautet die Beschriftung der Zeile „Spaltenqualität“
Unerwarteter Fehler.
Aha!
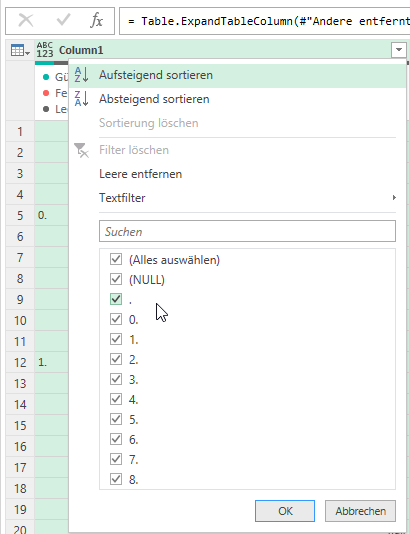
Ich gehe auf die Suche – Schritt für Schritt zurück. Schon bald ist klar, dass die Häufigkeit der Fehler unter 1% liegt:
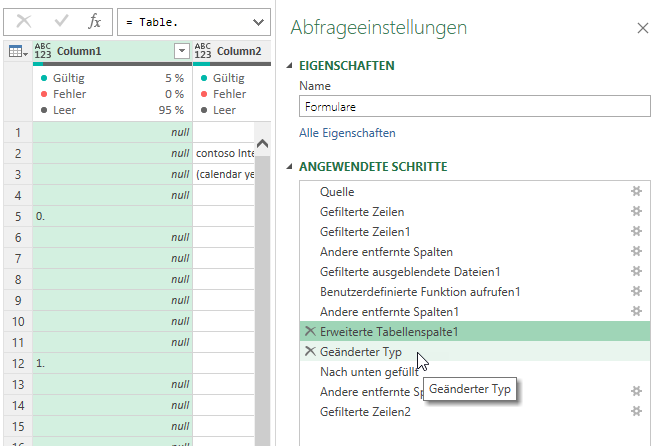
Der Fehler tritt auf, als der Typ geändert wird. Moment – DAS habe ich doch gar nicht gemacht:
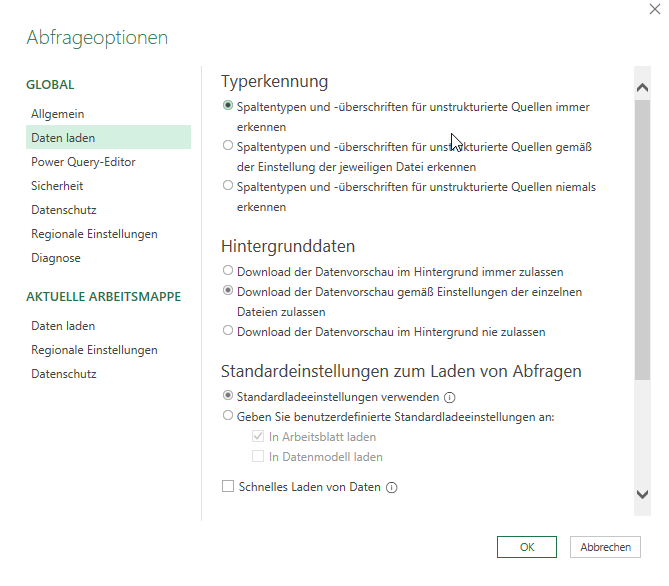
Richtig: in Datei / Optionen und Einstellungen / Abfrageoptionen lautet die Grundeinstellung:
Spaltentypen und -überschriften für unstrukturierte Quellen immer erkennen. Und richtig: Das produziert den Fehler:
[DataFormat.Error]
Aha – diese Einstellung bewirkt, dass aus 0., 1., 2., … die Zahlen 1, 2, 3, … werden. Das heißt: in einer der Dateien befindet sich wahrscheinlich in Spalte A eine andere Informationen.
Welche Datei? Zurück zum Anfang:
Ich entferne die erste und die zweite Spalte (den Dateinamen) nicht:
Bevor der Datentyp geändert wird, lasse ich mir alle Inhalte anzeigen:
und stelle fest, dass in einer (oder mehreren) Zellen ein Punkt vorhanden ist:
Da ich die Dateinamen „sehe“, kann ich die Spalte in den Datentyp „Text“ konvertieren und den Übeltäter filtern:
Als Text erzeugt der Punkt kein Problem, allerdings bei der (automatischen) Umwandlung in Zahl.
Die Lösung liegt auf der Hand: entweder man löscht den Punkt in PowerQuery raus oder man geht auf die Suche in der Datei:
Und dann funktioniert die Zusammenfassung problemlos:
Fazit: Vermeiden Sie – wenn möglich – die automatische Datenkonvertierung.
Verwenden Sie ALLE Daten bei der Fehlersuche.
Verwenden Sie die Werkzeuge der Registerkarte Ansicht, also: Spaltenqualität, Spaltenprofil und Spaltenverteilung.
PowerQuery stellt für Zahlenformate alle (nur denkbaren) Varianten auf Basis der Gebietsschemata zur Verfügung. Allerdings fehlt die ISO-Norm bei der Kalenderwoche.
Okay.
Wir haben eine Liste mit Ländernamen, die sortiert werden:
Es fällt auf, dass PowerQuery streng nach Groß- und Kleinschreibung sortiert. Deshalb steht die USA vor Ungarn:
Das kann man mit dem Befehl each Text.Upper korrigieren:
Aber: Österreich befindet sich am Ende. Das Alphabet wird US-amerikanisch sortiert. Und: der Befehl Sort stellt keinen Parameter zur Verfügung eine Länderkennung einzutragen. Im Deutschen wird a < ä < b sortiert, im Spanischen a < b < c < ch < d … < l < ll < m < n < ñ < o …
Für jedes Land, das heißt: für jede Sprache müsste man eine Hilfstabelle anlegen. Sehr mühsam!
Ich öffne im Windows-Explorer das Eigenschaftenfenster einer Datei und wechsle auf die Registerkarte „Sicherheit“. Dort finde ich den Dateinamen mit Pfad, den ich markiere und nach Excel kopiere. Achtung: Ich markiere von rechts nach links:
Ein zweites Mal – jetzt wird von links nach rechts markiert und anschließend kopiert:
Ich kopiere beide Varianten nach Excel – die erste ist oben, die zweite unten. Ich ermittle die Anzahl der Zeichen mit LÄNGE und bin erstaunt. Ich löse das erste Zeichen mit der Funktion LINKS heraus und bin wieder erstaunt:
Wandelt man das Zeichen vor dem Laufwerksbuchstaben D mit Code in den ASCII-Code um und mit ZEICHEN wieder zurück, so erhält man ein „?“
Ich bin erstaunt.
Noch schlimmer wird es, wenn man mit PowerQuery und diese Access-Datenbank zugreift
und den Pfad durch den ersten Text ersetzt:
DataFormat.Error: Der angegebene Dateipfad muss ein gültiger absoluter Pfad sein.
lautet die Fehlermeldung. Man sieht das Zeichen nicht – weder in Excel noch in Word, im Editor oder in PowerQuery. Und wundert sich über diese merkwürdige Fehlermeldung.
Da gibt es nur eine Lösung: Will man den Dateinamen mit Pfad ermitteln, muss man im Explorer über das Symbol „Pfad kopieren“ den Verzeichnisnamen und Dateinamen in die Zwischenablage kopieren. (danke an Martin Weiß für diesen Tipp)
Nennen wir ihn B. B. kann für Björn stehen. Oder für Benno. Für Benjamin oder für Boris. Egal. Wir nennen ihn B.
B. ist Teilnehmer meiner Excelschulung und stellt eine Frage zum Aufbereiten von CSV-Dateien, die er in regelmäßigen Abständen erhält. Er denkt an eine VBA-Lösung – ich schlage PowerQuery vor. Die Datei wird aufgerufen, transformiert und nach Excel zurück geschrieben.
Allerdings: der Pfad, beziehungsweise der Dateiname soll variabel sein. Eigentlich kein Problem, denke ich, und lasse B. Pfad und Dateiname in die Excelmappe schreiben, mit einer Überschrift versehen und in eine (intelligente) Tabelle umwandeln.
Beide Tabellen werden nach PowerQuery gezogen, und dort mit einem Drilldown in einen Text verwandelt. Sie werden in dem Befehl
File.Contents
verwendet; die Sicherheitsstufe dieser Arbeitsmappe wurde ignoriert. Und dann das Erstaunliche:
DataFormat.Error: Der angegebene Dateipfad muss ein gültiger absoluter Pfad sein.
Stirnrunzeln.
Probieren. Beispielsweise Pfad und Dateiname in PowerQuery (oder in Excel) zu verketten und diese Zeichenkette zu verwenden. Beides schlägt fehl:
Immer wieder die gleiche Fehlermeldung:
DataFormat.Error: Der angegebene Dateipfad muss ein gültiger absoluter Pfad sein.
In Ruhe, alleine, und ohne B. schaue ich mir die Zeichenkette genau an und probiere. Erstaunt stelle ich fest, dass das erste Zeichen nicht der Laufwerksbuchstabe ist. In Excel kann man das mit der Funktion LINKS oder TEIL ermitteln. Der ASCII-Code lautet 63 – eigentlich ein Fragezeichen.
Ich überlege, probiere und frage B. Er hat eigentlich nur den Namen des Verzeichnisses aus den Dateieigenschaften kopiert. Und ich habe ihm zugesehen.
Ich weiß nicht, wie dieses merkwürdige Zeichen in die Excelzelle gelangt ist. Ich weiß, dass Excel bei einigen Zeichen (geschützte Leerzeichen, bedingte Trennstriche, …), die man über Word, Outlook oder eine Webseite nach Excel kopieren kann, Probleme hat. Aber hier? Keine Ahnung.
Lösung des Problems: Pfad neu tippen – und dann klappt es!?!
Schöne Frage in der letzten PowerQuery-Schulung: warum kann man eigentlich keine Duplikate ermitteln lassen? Oder – wie in Excel – Duplikate löschen lassen?
Stimmt – DAFÜR gibt es in PowerQuery leider keinen Assistenten. Muss man „per Hand“ machen.
Tanja Kuhn schreibt: „Das geht beides. Duplikate löschen per Rechtsklick. Duplikate anzeigen über Gruppierung.“
Danke für den Hinweis – zur Gruppierung hätte der Teilnehme, der sich so eine Option beim Import der Daten gewünscht hatte, sicherlich angemerkt, dass man es dann auch „Duplikatensuche“ nennen sollte. Das „Duplikate löschen“ habe ich glatt übersehen / vergessen … (ich schäme mich! *lach*)
Der Teilnehmer dachte übrigens beim Verknüpfen von zwei Tabellen in einer 1:n-Beziehung an Access, bei dem beim Aktivieren der referentiellen Integrität automatisch überprüft wird, ob alle n-Elemente auf der 1-Seite vorkommen. So einen Haken oder eine Meldung hat er vermisst.
PowerQuery-Schulung. Ein Teilnehmer sagt, dass er nicht den gesamte Ordnernamen sehen kann und deshalb nicht den richtigen Ordner deselektieren kann.
„Dann schieben Sie halt die Bildlaufleiste nach rechts“, meine ich. „Geht nicht!“
Was ist pasiert?
Wir üben in der PowerQuery-Schulung den Zugriff auf Ordner:
Der Teilnehmer hat die Dateien (auf OneDrive) in einem sehr, sehr langen Ordnernamen abgelegt. Und wirklich: es ist dann leider nicht mehr möglich, die Bildlaufleiste so zu verschieben, dass ich das rechte Ende des Ordners sehen kann:
Die Lösung: Da ich den Text kenne, der am Ende steht, kann ich den gewünschten Ordner auch über „endet nicht mit“ filtern. DAS klappt.
Gestern PowerQuery-Schulung. Wir üben und probieren den Zugriff: Excelmappen, Textdateien, XML, json, die SQL-Datenbank, Ordner, Web, … alles klappt.
SharePoint?
Der Teilnehmer kopiert seinen Sharepoint-Pfad in das Eingabefeld:
Und noch bevor ich sagen kann, dass er sich über das Microsoft-Konto – drei Zeilen darunter – anmelden muss, erhält er eine Fehlermeldung:
Zweiter Versuch: erneute Anmeldung. Das Resultat: sofortige Fehlermeldung ohne die Möglichkeit sich über das „Microsoft-Konto“ anzumelden. Wie gelangt man wieder dort hinein?
Es dauert eine Weile, bis wir es gefunden haben:
Man muss über die Datenquelleneinstellungen den Pfad löschen:
… dann wird man bei der nächsten Anmeldung wieder nach ALLEN Einstellungsoptionen gefragt.
Es ist unglaublich, aber ich habe wirklich das Gefühl, dass ich in jeden «Sche…sstopf» falle, welchen Microsoft zu bieten hat.
Seit 2 Tagen kämpfe ich mit dem Problem, dass in einer table in jeder Zelle scheinbar versteckte Tabs vorhanden sind. Dies hat natürlich die traurige Konsequenz, dass damit s- oder wverweise auf diese table kläglich scheitern und zu #NV Fehlern führen.
Zum Problem mit Tabs hast Du ja den Artikel tabulatoren | Excel nervt … (excel-nervt.de) geschrieben, doch in meinem Fall hilft mir dieser (wenigstens im Moment) nicht wirklich weiter.
Ich muss dazu vielleicht etwas ausholen und den Vorgang beschreiben, welcher mich zum Problem geführt hat. Am Anfang steht Excel File mit einer table. Diese table wird mittels Power Automate in eine SharePoint Online Liste geschrieben.
In einem anderen Excel File werden die Daten der SharePoint Liste wieder mit einer PowerQuery Abfrage eingelesen und stehen somit wieder in einer table, auf welche ich eben mit dem erwähnten wverweis zugreifen möchte. Der Befehl führt eben zu dem #NV und nach langem Suchen, habe ich letztendlich herausgefunden, dass in der abgefragten table in allen Zellen ein tab steht. Interessanterweise ist es aber so, dass in der table sämtliche Zellwerte linksbündig angezeigt werden. Klicke ich dann bei denjenigen Zellen welche eine Zahl enthalten nicht auf sondern in die Zelle, dann springen die Zahlen nach rechts (ohne dass ich ausser dem Klick in die Zelle etwas anderes mache) Noch verwirrender (wenigstens für mich) ist die Tatsache, dass die Zellformatierungen danach erhalten bleiben. Ich meine damit, dass diejenigen Zellen in welche ich wie beschrieben einmal reingeklickt habe, auch nach einem reload der Power Query Abfrage erhalten bleiben.
Hast Du vielleicht eine Erklärung für dieses Verhalten? Wieso und wann wurden die Tabs in die Zellen geschrieben und gibt keine Möglichkeit dies zu beeinflussen?
Bezugnehmend auf Deine vorherige Antwort ist es aber sicherlich schon so, dass man solche Phänomene auch mit der besten Schulung nicht abwenden kann ☹
Würde mich auf jeden Fall darüber freuen, wenn Du eine Idee zu meinem neuen Problem hättest
Lieber Gruss
Hallo Herby,
das Problem ist mir und vielen anderen bekannt – ich würde
es nicht als Anomalie, sondern als Bug von Excel bezeichnen.
– dort beschreibe ich mehrere Lösungen (mein Liebling ist Daten / Text in Spalten) und auch, wie dieses Phänomen zustande kommt.
Liebe Grüße
Rene
Hallo Rene
Danke für die abermals hilfreiche Unterstützung
Mein Problem schein aber irgendwie anders gelagert zu sein und entgegen meiner
vorherigen Problemschilderung ist es leider nicht so, dass der Fehler mit einem
Klick in eine der betroffenen Zellen «nachaltig» gelöst wird.
Zur besseren Veranschaulichung habe ich eine Kopie der Tabelle erstell, welche
auf der PQ Abfrage beruht. Am Bsp der Zelle B2 kannst Du sehen, dass der
Zellwert nach einem Klick in die Zelle, nach rechts gesprungen ist.
Sobald ich das bei irgend einer benötigten Zelle mache, welche einen Zahlenwert
enthält, springen die Werte nach rechts und die Formeln mit den darauf
referenzierenden Zellen, funktionieren.
Wenn ich hingegen die PQ Abfrage aktualisiere, springen die Zahlen wieder nach
links und die Formeln bringen den #NV
D.h die PQ Abfrage erzeugt die falschen Daten und dabei spielt es
überhaupt keine Rolle, wie die Zellen formatiert sind.
Die Spalten der Daten Quelle (ShareListe) sind ausnahmslos als standard
formatiert und dies lässt sich auch nicht ändern, da innerhalb einer Spalte
unterschiedliche Daten vorhanden sind.
Wie bei Excel gibt es beim PQ unter Transformieren/Bereinigen die Trim
Funktion, mit welcher eigentlich ein tab aus einer Zelle entfernt werden
sollte.
Aber bis dato ist mir dies damit nicht gelungen
Das Problem muss beim erzeugen der Tabelle gelöst werden, da die Daten
dynamisch sind und laufend aktualisiert werden. Oder anders ausgedrückt, eine
neue Abfrage würde die vormals vorgenommenen Korrekturen mir den Daten
überschreiben.
Das File Servicekatalog Quelldaten dient als Datenquelle, das heisst wenn sich
irgendwelche Daten vom Servicekatalog geändert haben, werden diese dort
eingepflegt. Eine Flow schreibt die Daten in die SharePoint Liste, welche dann
wie PQ Abfrage von überall in eine Servicekatalog.xlsx gelesen werden können.
Die Quelldatei hat das Problem auf jeden Fall nicht, d.h entweder auf dem
SharePoint oder bei anschliessenden PQ Abfrage wird ein problematischer tab
angehängt ☹
Vielleicht mache ich einen Denkfehler und/oder Du hast eine Idee, was ich
ändern muss
Lieber Gruss
Hallo Herby,
Das Problem ist Folgendes:
In einer Spalten stehen Zahlen und Texte.
Wird diese Liste nach PowerQuery „gezogen“ und dort der Typ nicht explizit angepasst, so bleiben die Zahlen Zahlen (rechtsbündig) und die Texte Texte.
Verwendet man in PowerQuery jedoch den Datentyp „Text“, dann „schiebt“ Excel unter diese Zahlen ein Textformat (das so nicht sichtbar ist).
Da die Zelle als Standard (oder Zahl) formatiert ist, verschwindet das Textformat beim Editieren (Doppelklick) der Zelle. Andererseits: Nach Aktualisierung von PowerQuery haben wir die gleiche Situation wie am Anfang.
Gegenfrage: Warum MÜSSEN in einer Spalte Zahlen und Texte
stehen? Das widerspricht einem Datenbankdenken.
Und: wenn schon Zahlen – dann sollten sie auch Texte bleiben
– als Informationen und nicht zum Rechnen verwendet werden.
Excelstammtisch. Hartmut zeigt, dass man das Datenmodell von Excel nach PowerBI importieren kann.
Ich frage, ob er wisse, wann das zu Problemen führt. Und zeige eine Datei:
Darin befinden sich Tabellen, die ins Datenmodell geladen wurden. Mit Hilfe des Datenmodells wurde eine Pivottabelle erstellt. Die Tabellen wurden mit Measures angereichert und sind untereinander verknüpft.
Nun will ich diese Datei (genauer: die Daten, Verknüpfungen und Measures) nach PowerBI importieren:
Ich erhalte eine Fehlermeldung – fast nichts wird importiert:
Wir machen uns auf die Suche – Hartmut wird fündig. Man darf nicht die Daten in Tabellen in der Arbeitsmappe halten und diese ins Datenmodell laden, sondern man muss sie mit PowerQuery importieren. So:
Diese Daten werden nun ins Datenmodell geladen – dort kann man sie verknüpfen
und mit Measures anreichern:
Das Ergebnis:
Ein erneuter Import nach PowerBI Desktop:
Klappt!
Ein Dankeschön an Hartmut Hilbich für das Suchen und Auffinden der Lösung des Importproblems. Hartmut schreibt dazu:
„Das Problem bestand hier (besteht!) darin, dass PBID das Datenmodell selbst sehr wohl importiert, aber nicht gleichzeitig auch die Quelltabellen!
Ich habe die
Quelltabelle mit PQ abgefragt und das PP-Modell exemplarisch mit 2 Measures
versehen. Der Import in PBID funktioniert dann einwandfrei!
Mein Fazit: Es ist nicht
ratsam, die Quelldaten physikalisch gemeinsam mit dem PP-Modell zu speichern.
Also entweder die Daten direkt mit PP abfragen, oder aber (besser) mit PQ
abfragen. Was also innerhalb von PP kein Problem ist, wird dann aber eines beim
Import in PBID.
PowerBI-Schulung. Wir greifen auf Excelmappen zu, die auf Sharepoint liegen. Es kommt die Frage, ob man auch auf einen Sharepoint-Ordner zugreifen kann. Klar kann man:
Man muss nur den Ordnerpfad kopieren und eintragen:
Und – erhält einen Fehler:
Ach, klar, natürlich: man muss sich natürlich noch anmelden. Ist ein bisschen versteckt:
Erstaunlicherweise kann man JETZT OHNE Anmedlung in Excel über PowerQuery auf einen Sharepoint-Ordner zugreifen. Muss ich das verstehen?
Amüsant: ich habe eine große Excelliste mit mehrere Tausend Datensätzen. Ich bearbeite sie in PowerQuery:
Ich importiere eine zweite Liste und verknüpfe sie mit einem Left outer Join:
Das Ergebnis sieht in PowerQuery gut aus:
Ich lade die Tabelle zurück nach Excel und erhalte einen Fehler:
Zurück zu PowerQuery versuche ich einen Right outer Join:
Die Ursache? PowerQuery zeigt nur 1.000 Datensätze. Wenn in der Liste DANACH eine Zelle mit einem fehlerhaften Wert steht, wird er bei einem Left Outer Join nicht angezeigt. Erst in Excel. Natürlich kann man sich in PowerQuery auf die Suche nach dem fehlerhaften Datensatz machen und ihn entfernen. Oder in Excel:
Danke an Christa für diesen Hinweis und danke für die Bemerkung, dass die Fehlermeldung in älteren PowerQuery-Versionen eine andere war:
Gestern habe ich für den Excelstammtisch einige Dateien vorbereitet, um zu zeigen, was PowerQuery verlangsamt. Ich habe eine Liste mit Dummy-Namen mit 20.000 Datensätzen:
Diese verknüpfe ich mit einer Liste, die zwei Zeilen lang ist:
Das Ergebnis: 28.877 Datensätze
Ein zweiter Blick auf die Liste zeigt, dass einige Zeilen (nicht alle!) nun zwei Mal in der Liste auftauchen:
Nein – an der Verwendung eines Primärschlüssels liegt es nicht – die Zeile
Zuerst habe ich mich geärgert. In PowerQuery gab es früher ein Symbol „Von Tabelle“. Daraus wurde in der Gruppe „Daten abrufen und transformieren“ das Symbol „Aus Tabelle/Bereich“.
Seit ein paar Tagen heißt es nun „Vom Blatt“
Muss das sein? Ständiges Umbenennen?
Frank Arentd-Theilen hat mich auf den Grund hingewiesen (danke für den Hinweis):
Ja – denn nun kann man Listen in Excel, die mit den neuen Arrayfunktionen erstellt wurden, beispielsweise mit FILTER, SORTIEREN und SORTIERENNACH in PowerQuery importieren:
Das funktioniert auch mit der Funktion SEQUENZ:
Okay – zugegeben – leider nicht immer. Wenn diese Matrixfunktionen innerhalb einer Liste stehen, wie beispielsweise hier in diesem Monatskalender:
dann wandelt PowerQuery die gesamte Liste in eine (intelligente) Tabelle um und – scheitert! Klar: Tabellen dürfen keine Matrixfunktionen verwenden …
Ich suche jemanden, der fit in power query und power pivot
ist und dem ich ca. eine stunde lang fragen stellen kann.
Hintergrund: Ich habe einen größeren Auftrag, da geht es um mehrere Tools im Excel-Umfeld, da geht es bei einem Tool jetzt erst mal darum, ob power query da was bringen würde.
Ich hatte Schlimmes oder Schwieriges befürchtet. Aber die zentrale Frage war weder schlimm noch schwierig zu beantworten.
Gegeben sei eine Auftragstabelle mit Verkaufsdaten:
Diese Liste wird nach PowerQuery gezogen und dort bearbeitet. Das Ergebnis wird zurückgegeben:
Die erste Frage lautete: Wie kann man Anfang und Ende als Filter in PowerQuery einbauen?
Die Antwort:
Man muss die jeweils zwei Zellen in eine intelligente Tabelle konvertieren.
Man muss diese ebenso nach PowerQuery importieren.,
Dort den Datentyp in Datum ändern.
Und dort ein Drilldown durchführen. Das heißt: die Tabelle in einen Wert, besser: in eine Variable, verwandeln.
Diese Variable hat einen Namen – er kann verwendet werden.
Also so:
Man schaltet einen beliebigen Datumsfilter ein („Zwischen“):
Und ersetzt in M die beiden Werte durch die Variablennamen:
Fertig! Test in Excel:
Und natürlich kam danach die Frage:
ich möchte die berechnung lieber in PowerPivot vornehmen und mit einer Pivottabelle gruppieren und das Meassure verwenden.
Ich habe jetzt in DAX diesen ausdruck, der funktioniert:
Gestern im Excelstammtisch. Frank Arendt-Theilen macht darauf aufmerksam, das PowerQuery einen Parameter bei der Funktionen RUNDEN (Number.Round) anbietet:
IntelliSense zeigt allerdings in M, dass diese Funktion einen weiteren Parameter besitzt: roundingMode mit fünf Konstanten:
Die Standardeinstellung von PowerQuery ist RoundingMode.ToEven. Damit unterscheidet sich diese Rundenfunktion von RUNDEN in Excel. Dort wird RoundingMode.AwayFromZero verwendet. Deshalb unterscheiden sich diese beiden Runden-Funktionen: PQ rundet wie VBA; Excel rundet anders …
Vielen Dank, Frank für diesen sehr, sehr wertvollen Hinweis!
ich arbeite an einem VBA – Projekt, dass aus Power BI Dateien die
Metadaten rauslesen soll.
Das Auslesen geschieht über Power Query (what else….), aber ich
muss noch ein paar Prüfungen mit VBA erstellen und insbesondere die Power Query
Abfragen on the fly erstellen. Letzteres geht problemlos.
Der Ablauf:
Prüfe, ob User die pbix geöffnet hat.
Falls nicht, bitte freundlich darauf aufmerksam machen
Falls nein, Abbruch – falls ja, pbix öffnen.
Bis dahin klappt alles.
Nun kommt der Punkt, wo der Benutzer sich gegenüber der Power BI
Datei authentifizieren muss, nachdem er ja gesagt hat.
falls er aber den Dialog hier abbricht (…..DAU…….), kommt
eine „schöne“ Meldung:
Nun meine Frage:
Wie kann ich hier meine eigene Meldung einbauen und vor allem, wie
fange ich das ab?
Bin schon voller Zweifel…..
Merci, lieber René für deine Geduld mit mir
Freundliche Grüsse Hans Peter
########################################
die unwissenden erleuchten sich selber
habs gefunden. nach Drücken von „Senden“ fiel es mir wieder ein, da stand was im Buch von René
Erstaunlich! Auf dem letzten Excelstammtisch, den Frank Arendt-Theilen organisiert hat, hat er angemerkt, dass die PowerQuery-Funktion Date.WeekOfYear, die man über Spalte hinzufügen / Datum / Woche / Woche des Jahres nach dem US-amerikanischen Modell rechnet. Zwar verfügt Excel seit vielen Versionen über die Funktion ISOKALENDERWOCHE, welche die KW korrekt nach ISO 8601 berechnet. Auch Outlook unterscheidet bei den Kalenderwochen zwischen USA und Europa. Jedoch nicht PowerQuery. „Haben die das vergessen?“, fragt Frank. Also muss man diese Funktion in PQ nachbauen …
ich bin durch Zufall auf Ihren Blog aufmerksam geworden.
Leider hat Excel immer wieder merkwürdige Verhaltensweisen.
Warum auch immer.
Ich habe auf einem Rechner ein Problem mit der Funktion Daten
„Abrufen und transformieren“
Ich kann auf dem PC keinerlei Daten über diese Funktion aufrufen.
Keine CSV noch eine Tabelle aus einem SQL Server.
Ich bekomme immer wieder die Fehlermeldung, dass die
Initialisierung der Daten fehlgeschlagen sei.
Lade ich die CSV auf einem anderen Rechner ein, funktioniert dies
Problemlos.
Gleiches gilt bei der SQL Abfrage.
Haben Sie noch eine Idee wo ich das Problem suchen kann?
In der PowerQuery kann ich die Daten sauber sehen.
Nur das Einfügen der Daten aus der Verbindung in das Tabellenblatt
funktioniert nicht.
Vielen Dank für Ihre Zeit. Mit besten Grüßen,
####
Ich habe es mir gerade angesehen: Excelversion 2016.
Ich erstelle eine intelligente Tabelle, ziehe sie in PQ, klappt; ich bearbeite, ich tue, ich mache, M-Code ist vorhanden – klappt.
Ich lade sie als
Verbindung. Klappt.
Aber sobald ich die Daten als Tabelle „sehen“ / „haben“ möchte – knallt es:
Kennt jemand diesen Fehler?
Initialisierung der Datenquelle schlug fehl. Überprüfen Sie den Datenbankserver oder kontaktieren Sie Ihren Datenbankadministrator. Vergewissern Sie sich, dass die externe Datenbank verfügbar ist, und wiederholen Sie den Vorgang. Sofern diese Nachricht wieder erscheint, erstellen Sie eine neue Datenbankquelle um mit der Datenbank Verbindung aufzunehmen.
In der letzten Excelschulung waren wir erstaunt. Wir verknüpfen mehrere Tabellen miteinander:
Warum dauert das Verknüpfen der Daten in PowerQuery so lange?
Die Ursache war schnell gefunden: die Teilnehmerin hatte den Cursor nicht in die Liste gesetzt und so aus der Liste eine (intelligente) Tabelle erzeugt, sondern die ganzen Spalten markiert und dann diese (mit den leeren Zeilen) in eine Tabelle umgewandelt.
Der Anfang der Tabelle:
Und das Ende:
Als wir den Fehler entdeckt hatten, wollte die Teilnehmerin den Bereich „per Hand“ nach oben ziehen:
Ich werde nervös, wenn Aktion SOOO lange dauern. Ein kurzer Blick … das muss doch schneller gehen … und wirklich: es geht schneller. Das Werkzeug „Tabellengröße ändern“ in der Registerkarte „Tabellenentwurf“ bietet eine schnelle Möglichkeit Tabellen zu vergrößern und verkleinern. Man muss nur $A$1:$E$2156 tippen – und schon ist die Tabelle kleiner. Und PowerQuery schneller!
Die Originaldatenquelle ändert sich – sie wird kleiner. Die Verbindung wird aktualisiert:
Die Folge: Die Formel wird angepasst, beispielsweise in:
=KKLEINSTE($F$2:$F$15;ZEILE(A1))
Fehlermeldungen sind die Folge.
Ändert sich die Liste erneut und wird nun länger, werde diese Bezugsfehler natürlich nicht korrigiert …
Fehler in der Berechnung sind die Folge.
Heißt: Wenn schon (intelligente/formatierte/dynamische) Tabellen – dann bitte die Bezüge auf diese Tabellen in Tabellenschreibweise und nicht in Bezugsschreibweise! Sonst gibt es Ärger!
Wer mit Datenbanken arbeitet, der würde in dieser Liste sofort eine n:m-Beziehung erkennen: einer Rebsorte sind mehrere Länder zugeordnet. In einem Land werden es mehrere Rebsorten angebaut. (zugegeben: das Original-Beispiel, das mir die Teilnehmerin zeigte waren Firmendaten aus dem Bereich firmeninterne Weiterbildungen – aber die Struktur war die gleiche)
Auch wenn die Länder durch einen Umbruch in eine Zelle eingefügt wurden, kann man sie mit dem Assistenten „Text in Spalten“ oder mit PowerQuery trennen.
Allerdings sollen nun Zuordnungen zu den Ländern getroffen werden. Das heißt: in einer Zeile steht ein Land oder mehrere Länder NEBENEINANDER.
Zum Glück stellt PowerQuery den Assistenten entpivotieren zur Verfügung:
Damit werden nicht nur die Zeilen n Mal wiederholt, sondern die zugehörigen Länder stehen auch UNTEREINANDER, was zur Weiterverarbeitung (SVERWEIS oder was auch immer) hervorragend geeignet ist:
Sind mehrere Texte in einer Zelle untereinander geschrieben, kann man sie mit dem Assistenten Daten / Text in Spalten trennen.
Und die Blitzvorschau? Ein Versuch ist es wert:
Sieht gut aus – jedoch:
Okay zu lang. Na ja! Und der zweite Wert? Versagt, weil in der zweiten Zeile nur ein Wert steht. Die Anzahl der Werte, die sich untereinander befinden, ist unterschiedlich groß:
Auf ein Neues: PowerQuery. Seit einigen Versionen stellt PowerQuery – anders als der Assistent „Text in Spalten“ als Trennzeichen den Zeilenumbruch zur Verfügung:
Splitter.SplitTextByDelimiter(„#(lf)“
Klappt! Klappt hervorragend!
Können Sie M? Da wir wissen, dass der Zeilenumbruch in Excel dem Wert 10 entspricht hätte man auch verwenden können:
Character.FromNumber(10)
Also:
„Split Column by Delimiter“ = Table.SplitColumn(Source, „Anbauländer“, Splitter.SplitTextByDelimiter(Character.FromNumber(10), QuoteStyle.Csv), …
Einmal links, einmal rechts – da muss ich jedesmal hinschauen. Kennt ihr das? Ich habe eine Datei erstellt oder geöffnet und modifiziert und möchte die Datei oder die Applikation schließen OHNE zu speichern. Sei es, weil ich etwas ausprobieren wollte, weil ich nur drucken wollte, weil die Änderungen falsch waren, weil Excel volatile Funktionen neu berechnet hat… Es gibt eine Reihe von Gründen. Also: schließen/beenden OHNE ZU SPEICHERN. Wohin klicken? „Nicht speichern“ – rechts:
Eben: „Nicht speichern“ – rechts:
Ups: noch ein Button mehr:
Hier auch:
Oder ich muss genau hinschauen, um zu verstehen, dass „NEIN“ „nicht speichern“ bedeutet:
In PowerQuery muss ich wieder rechts klicken – allerdings: „Verwerfen“:
Und hier: richtig: links klicken! Damit das Hirn wieder funktioniert! Die Aufmerksamkeit auf den Text gelenkt wird! Bloß keine Langeweile oder Gewohnheit aufkommt:
Unabhängig
davon möchte ich Ihnen nochmals für die sehr gelungene Onlineschulung am Freitag
danken.
Sehr
praxisnah und super erklärt! Ich freue ich schon auf PowerBI im September.
Bei dem File gibt es noch ein kleines Problem
Formula.Firewall: Abfrage ‚Tabelle 1‘ verweist auf andere Abfragen oder Schritte und kann daher nicht direkt auf eine Datenquelle zugreifen. Erstellen Sie diese Datenkombination neu.
Ich kann mir dies im Moment nicht im Detail ansehen (Pfad scheint korrekt, Files vorhanden), werde aber am Nachmittag nach Anleitung versuchen, dies „nachzubauen“.
Könnte ein Kompatibilitätsproblem sein (Excel-Version). Bekomme vor öffnen von Power Query diese Meldung:
Kompatibilitätswarnung: Die Abfragen in dieser Arbeitsmappe sind u.U. nicht mit Ihrer aktuellen Version von Excel kompatibel.
Hallo Herr Martin,
Ihre
Liste funktioniert doch – es waren meine Sicherheitseinstellungen.
#“Added Index“[Artikelname] ist die Spalte aus der die
Daten gruppiert werden.
[Index] – ab dieser Position wird gruppiert
],[#“Artikel (2).Anzahl“] – so viele Elemente werden
gruppiert
Steht ein Wert beispielsweise drei Mal in der Liste, können die letzten zwei Werte gelöscht werden. Dies erreicht man mit dem Befehl „Duplikate entfernen“, den Sie in Home / Zeilen verringern / Zeilen entfernen finden.
Amüsant. Während Inquire auch ausgeblendete Blätter anzeigt (sowohl hidden als auch very hidden)
zeigt PowerQuery nut die sichtbaren Blätter an:
Nein! Nicht ganz. Wenn man die Daten nun transformiert und zurück zur Source wechselt, so sieht man auch dort alle Blätter – egal ob sichtbar oder ausgeblendet:
Danke an Dominique Dauphin für diesen wertvollen Hinweis!
Ich habe eine Tabelle. Ich lege einen Druckbereich fest. Ich möchte, dass Menschen zwar die Tabel drucken dürfen, aber die Daten nicht stehlen, also nicht einfach rauskopieren.
Also wird ein Schutz auf das Tabellenblatt gelegt.
Wir wissen, dass PowerQuery von Dateien Tabellenblattnamen, Namen und intelligente Tabellen anzeigt. Da der Druckbereich als Name bespeichert wird, wird er angezeigt.
Kann geladen werden und nach Excel zurückgeschrieben werden.
Und schon hat man Zugriff auf die Faten. Ohne die Datei zu entzippen, das Protect-Element zu löschen, …
das ist sehr spannend, was da passiert. Ich habe die Ursache gefunden:
Die Überschrift Ihrer Tabelle ist länger als 255 Zeichen.
Sie speichern die Arbeismappe. Sie greifen mit PowerQuery auf diese Datei zu. PQ greift mit der Zeile
= Table.TransformColumnTypes(#“Höher gestufte Header“,{{„ID“, Int64.Type}, {„Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet.“, type number}})
darauf zu. Wir schreiben die Tabelle als intelligente Tabelle zurück nach Excel. Tabellen dürfen maximal 255 Zeichen in der Überschrift haben. Excel schneidet die restlichen Zeichen ab.
Soweit klappt de Workflow. Wenn ich allerdings diese Datei schließe und öffne, erhalte ich die Fehlermeldung.
Die Ursache: die Überschrift endet jetzt nicht mehr auf „dolor sit amet“.
Eine weitere Fehlermeldung ist die Folge:
Sehr spannend. Lösung: Mit einer intelligenten Tabelle arbeiten! Dann ist die maximale Anzahl der Buchstaben der Überschrift begrenzt.
Heute in der PowerQuery-Schulung kam die Frage, ob man ab einer bestimmten Spalten alle anderen Spalten bis zum Ende der Tabelle löschen könne:
Schöne Frage. Geht aber nicht mit den Hausmittel. Ein paar Zeilen Code M wären nötig.
Ich habe vorgeschlagen von der ersten bis zu der Spalte mit der [Umschalttaste] zu markieren und anschließend „Andere Spalten entfernen“. Ist ein Klick mehr. Geht aber auch …
Power Query bei Ken Puls zu lernen ist ein Genuss.
Teil II
Auch deshalb (aber nicht nur deshalb), weil er auch so gerne über Excel, Ungereimtheiten und Schwächen lästert. Hier eine kleine Auswahl seiner spöttischen Bemerkungen über Power Query & co:
Der Dialog „gruppieren nach“ ist klasse – aber er zeigt die drei Pünktchen erst dann, wenn man mit der Maus darüber fährt.
Importiert man einen Bereich nach Power Query wird daraus eine Tabelle!?! Der Name der Tabelle: Tabelle1!
Power Query bei Ken Puls zu lernen ist ein Genuss.
Auch deshalb (aber nicht nur deshalb), weil er auch so gerne über Excel, Ungereimtheiten und Schwächen lästert. Hier eine kleine Auswahl seiner spöttischen Bemerkungen über Power Query & co:
Warum ist bei Dialogen so häufig der Default-Button derjenige, der am unwichtigsten ist? Kens Tipp: meistens ist der Button links von der Abbrechen-Schaltfläche der wichtige:
„Gebietsschema“: Der langsamste Dialog in PQ:
Warum ist das „schnelle Laden von Daten“ nicht Standard?
Warum zeigt ein Doppelklick auf den Rand nicht den kompletten Inhalt?
Ich habe meine Verwunderung darüber ausgedrückt, dass PowerQuery (ein Werkzeug, das ich wirklich schätze und das sehr stark und mächtig ist), nicht druckbare Zeichen nicht darstellt. Das rief Kritik auf den Plan. Von vorne. Gegeben sei eine Tabelle, die von einem anderen System geliefert wurde, in denen nicht druckbare Zeichen vorhanden sind:
Die Funktionen CODE und ZEICHEN, TEIL und WECHSELN helfen in Excel beim Säubern, beziehungsweise beim Trennen der Daten.
Ziehe ich die Daten nun nach Power Query, so mein Erstaunen, werden diese Zeichen dort nicht angezeigt. Auch der Assistent „Spalten teilen“ biete keine Option für „nicht druckbare Zeichen“. Beim Zurückspielen nach Excel sind diese Zeichen wieder vorhanden (sie wurden ja nie gelöscht):
Als ich etwas leichtfertig und zugegebenermaßen nicht ganz korrekt, gepostet habe, dass PQ das nicht kann, rief ich Kritik auf den Plan:
„Hallo René, ich hoffe es geht Dir gut. Ich weiß zwar nicht genau, was Du mit nichtdruckbaren Zeichen im Detail in Excel machst, aber ich bin mir ziemlich sicher, dass das – entgegen Deiner Bemerkung – auch mit Power Query geht“
„Das ruft den Experten auf den Plan, wenn ich behaupte, dass das nicht mit PQ geht … Hallo Lars, es gibt Systeme, die liefern in Excel oder Textdateien nicht-druckbare Zeichen (die dort – in anderen Systemen – als Trennzeichen definiert sind) Mit ist aufgefallen, dass PQ diese nicht anzeigt – aber – wenn ich die transformierte Datei wieder zurückspiele – diese Zeichen wieder drin sind. schau mal; probier mal – korrigiere mich – lasse ich gerne!“
„Was Power Query nicht alles kann:
Als Hintergrund: Wenn Du die Daten in Power Query lädst, dann sind die nicht druckbaren Sonderzeichen zwar nicht (ohne weitere Arbeit) sichtbar, aber sie sind vorhanden und man kann sich „um sie kümmern“ Ich denke, dass ich dazu mal einen Blogbeitrag schreiben werde. Danke für die Datei und diese Herausforderung“
#“Changed Type“ =
Table.TransformColumnTypes(Source,{{„Name“, type text}}),
#“Name getrennt“ = Table.AddColumn(#“Changed Type“,
„Name getrennt“, each
Text.Replace([Name],Character.FromNumber(7),“|“))
in
#“Name getrennt“
Ich hätte es schön gefunden, wenn das mächtige Power Query in seinem Assistenten „Spalte teilen“ eine Option dafür gehabt hätte …“
„Hi Rene,
okay, aber in Excel benutzt Du dafür doch auch Formeln, wieso ist das für PQ dann nicht erlaubt? Die Engine hat die Fähigkeiten, aber das Dev Team hat über die GUI eben noch keinen Befehl bereitgestellt.
Aus Deinem Post hatte ich verstanden, dass es gar nicht geht, nicht, dass es nicht über die GUI geht. Das finde ich nicht besonders schlimm.“
„Okay, Lars, du hast gewonnen. Ich habe den Satz korrigiert: „Übrigens: bedauerlicherweise kann man dies nicht mit Power Query mit den „Hausmitteln“ trennen – man benötigt hier einige Zeilen M.“ Ich war verblüfft, dass die nicht druckbaren Zeichen nicht angezeigt werden, aber (und das ist eigentlich auch vernünftig) nicht gelöscht werden. Ich hätte mir in dem (sehr viel mächtigeren Assistenten als in Excel) „Spalten teilen“ eine Option gewünscht, wo man Character.FromNumber() (oder ähnliches) eintragen kann. Tja. Liebe Grüße Rene“
„Meine Funktion tut genau das… Ich habe sie recht schnell entworfen, daher muss der ReplacerText auch als Unicode-Zeichen (also als Nummer) eingegeben werden, anstatt als Text… könnte man alles noch verbessern, aber sie tut bisher, was sie soll…
(TextMitNonPrintables as text, optional ReplacerText as number) as text =>
Daumen hoch für Johannes Curio (http://curio-consulting.de/), der auch als Referent bei unseren Exceltagen zur Verfügung stand. Er hielt informative, amüsante und spannende Referate über Pivot, Power Query und PowerBI.
Spannend fand ich seine Bemerkung, dass man in PowerQuery niemals den Automatismus „Changed Type“ verwenden sollte. In vielen Fällen wird der Datentyp nicht richtig erkannt, so seine Bemerkung.
Dies demonstrierte er anhand eines CSV-Imports am Beispiel einer Datumsspalte. Seine Empfehlung: diesen Schritt löschen und selbst das Datenformat definieren:
Rückblick Exceltage 2019. Mit Imke Feldmann konnten wir eine hervorragende PowerBI-Programmiererin und -kennerin finden. Warum erscheint sie nicht bei der Suche nach PowerBi-Fragen? Ihr Blog https://www.thebiccountant.com/ ist auf Englisch und deshalb wird sie Deutschland nur schwer gefunden. Dennoch: Kenner der Szene kennen und schätzen sie sehr. Ich habe sie das erste Mal live erlebt und war begeistert von ihrer lebendigen und witzigen Art, aber auch von ihrem profunden Sachwissen und ihrer Kompetenz, Probleme mit Daten zu lösen.
Amüsiert habe ich mich über ihr Erstaunen, dass links neben den PowerQuery-Befehlen Zeilennummern (besser: Befehlsnummern) stehen.
Man kann diese Befehle im Erweiterten Editor ein- und ausschalten: In den Anzeigeoptionen gibt es die Einstellung „Zeilennummern anzeigen“.
Für unsere Exceltage 2019, die in München am 18. und 19. Oktober stattfinden, konnten wir auch den hervorvorragenden „Power“-Spezialisten Hans-Peter Pfister gewinnen. Er wird über PowerQuery, Power Pivot, Power BI und M sprechen.
In seinem Skript über die Abfragesprache M finde ich folgenden wichtigen Satz:
Mit Eingabe des Kommas wird die Variablendefinition abgeschlossen.
Einzige Ausnahme ist die letzte Variablendefinition vor in – hier
darf nie ein Komma stehen.
Wie oft bin ich schon darüber gestolpert, dass ich – Macht der Gewohnheit – hier ein Komma eingetragen habe.
Schade! Wenn man mit Power Query auf eine Liste zugreift und diese in Excel als Tabelle einfügt, kann man sie aus dem Aufgabenbereich „Abfragen und Verbindungen“ in einer „anderen Form“ laden – der Dialog „Daten importieren“ wird geöffnet.
Dieser Dialog kann auch über das Symbol „Laden in“ aus der Registerkarte „Abfrage“ der „Abfragetools“ geöffnet werden:
Jedoch leider nicht aus dem Power Query-Editor, wenn er einmal geschlossen wurde und dann wieder geöffnet wurde:
Schade. Ich liebe Power Query! Gut, durchdacht, clever, scheinbar fehlerfrei. Jedoch: eine Sache habe ich gefunden, die mich sehr irritiert.
Importiert man eine XML-Datei, in der sich Umlaute befinden, werden diese nicht korrekt angezeigt und lassen sich auch noch transformieren. Ich habe weder einen Schalter (Gebietsschema) noch einen anderen, cleveren Ersetzen-Befehl gefunden. Schade!
Die Aktion kann nicht abgeschlossen werden, da die Datei in Microsoft Mashup Evaluation Container geöffnet ist.
Diese lustige Meldung habe ich erhalten, als ich versucht habe eine Datei umzubenennen. Was habe ich gemacht? Ich habe mit Power Query in Excel auf die Datei zugegriffen und dann den Power Query Editor verlassen und die Änderungen nicht beibehalten. Im Fenster „Abfragen und Verbindungen“ wird keine Verbindung angezeigt, dennoch hält das “ Microsoft Mashup Evaluation Container“ diese Datei.
das Werkzeug heißt „Daten abrufen und transformieren“. Und
darum geht es – nicht um das Formatieren:
Ich erstelle eine Verknüpfung zur Nordwinddatenbank und lade
beispielsweise die Tabelle „Rechnungen“ in den Power Query-Editor. In den
letzten beiden Spalten befinden sich Zahlen > 1000. Ich wandle sie in Text
um.
Beispielsweise 1113,75
Konvertiere ich diesen Text nun in eine Dezimalzahl nach dem
englischen Gebietsschema (US) um, so erhalte ich 111375. Das Komma wäre
in den USA als Tausendertrennzeichen gedacht; macht keinen Sinn – wird
entfernt.
Letzten Schritt löschen.
Ich konvertiere den Typ in Dezimalzahlen Gebietsschema
Deutsch (Deutschland) und erhalte nun 1113,75.
Es geht beim Konvertieren nicht um die Frage: ich möchte
diese Zahl US-amerikanisch oder deutsch darstellen, sondern ich erhalte eine
solche Zahl (oder Datum) und möchte sie so transformieren, dass mein System es
verarbeiten kann.
Die Darstellung wird dann in Excel durch Formatieren
erledigt. Oder durch die Einstellungen des Betriebssystems, bzw. von Excel.
Gestern Abend auf dem Excelstammtisch. Wir diskutieren über Listen und über verschiedene Möglichkeiten sie zu vergleichen. Beispielsweise mit Power Query (Daten abrufen und transformieren). Man muss nicht nur eine Spalte verwenden (die ID), sondern kann auch mehrere Spalten als Primärschlüssel verwenden. Man muss sie markieren. Ich versuche es – padautz – es geht nicht!
Die Lösung ist schnell gefunden: Ich habe in der ersten Liste Spalte 1 und dann Spalte 2 markiert, in der unteren dagegen Spalte 2 und anschießend Spalte 1.
Die Fehlermeldung ist merkwürdig: „Wählen Sie Spalten desselben Typs aus, um den Vorgang fortzusetzen.“ Habe ich doch!
Wenn man genau hinschaut, kann man die Nummer der Reihenfolge als Beschriftung in der Spalte sehen:
Also: richtig markieren – dann darf ich auch verknüpfen: